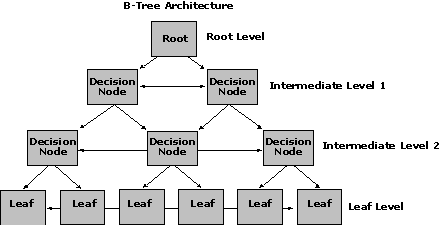
Microsoft SQL Server offers clustered and nonclustered index structures. These indexes are made up of pages that form a branching structure known as a B-tree (similar to the Oracle B-tree index structure). The starting page (root level) specifies ranges of values within the table. Each range on the root-level page points to another page (decision node), which contains a more limited range of values for the table. In turn, these decision nodes can point to other decision nodes, further narrowing the search range. The final level in the branching structure is called the leaf level.
Clustered indexes are implemented in Oracle as index-organized tables. A clustered index is an index that has been physically merged with a table. The table and index share the same storage area. The clustered index physically rearranges the rows of data in indexed order, forming the intermediate decision nodes. The leaf pages of the index contain the actual table data. This architecture permits only one clustered index per table. Microsoft SQL Server automatically creates a clustered index for the table whenever a PRIMARY KEY or UNIQUE constraint is placed on the table. Clustered indexes are useful for:
SELECT * FROM STUDENT WHERE GRAD_DATE
BETWEEN '1/1/97' AND '12/31/97'
SELECT * FROM STUDENT WHERE LNAME = 'SMITH'
For example, on the STUDENT table, it might be helpful to include a nonclustered index on the primary key of ssn, and a clustered index could be created on lname, fname, (last name, first name), because this is the way students are often grouped.
Dropping and re-creating a clustered index is a common technique for reorganizing a table in SQL Server. It is an easy way to ensure that data pages are contiguous on disk and to reestablish some free space in the table. This is similar to exporting, dropping, and importing a table in Oracle.
A SQL Server clustered index is not at all like an Oracle cluster. An Oracle cluster is a physical grouping of two or more tables that share the same data blocks and use common columns as a cluster key. SQL Server does not have a structure similar to an Oracle cluster.
As a general rule, defining a clustered index on a table improves SQL Server performance and space management. If you do not know the query or update patterns for a given table, you can create the clustered index on the primary key.
The table shows an excerpt from the sample application source code. Note the use of the SQL Server clustered index.
| Oracle | Microsoft SQL Server |
|---|---|
| CREATE TABLE STUDENT_ADMIN.GRADE ( SSN CHAR(9) NOT NULL, CCODE VARCHAR2(4) NOT NULL, GRADE VARCHAR2(2) NULL, CONSTRAINT GRADE_SSN_CCODE_PK PRIMARY KEY (SSN, CCODE) CONSTRAINT GRADE_SSN_FK FOREIGN KEY (SSN) REFERENCES STUDENT_ADMIN.STUDENT (SSN), CONSTRAINT GRADE_CCODE_FK FOREIGN KEY (CCODE) REFERENCES DEPT_ADMIN.CLASS (CCODE) ) |
CREATE TABLE STUDENT_ADMIN.GRADE ( SSN CHAR(9) NOT NULL, CCODE VARCHAR(4) NOT NULL, GRADE VARCHAR(2) NULL, CONSTRAINT GRADE_SSN_CCODE_PK PRIMARY KEY CLUSTERED (SSN, CCODE), CONSTRAINT GRADE_SSN_FK FOREIGN KEY (SSN) REFERENCES STUDENT_ADMIN.STUDENT (SSN), CONSTRAINT GRADE_CCODE_FK FOREIGN KEY (CCODE) REFERENCES DEPT_ADMIN.CLASS (CCODE) ) |
In nonclustered indexes, the index data and the table data are physically separate, and the rows in the table are not stored in the order of the index. You can move Oracle index definitions to Microsoft SQL Server nonclustered index definitions (as shown in the following example). For performance reasons, however, you might want to choose one of the indexes of a given table and create it as a clustered index.
| Oracle | Microsoft SQL Server |
|---|---|
| CREATE INDEX STUDENT_ADMIN.STUDENT_ MAJOR_IDX ON STUDENT_ADMIN.STUDENT (MAJOR) TABLESPACE USER_DATA PCTFREE 0 STORAGE (INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED) |
CREATE NONCLUSTERED INDEX STUDENT_MAJOR_IDX ON USER_DB.STUDENT_ ADMIN.STUDENT (MAJOR) |
In Oracle, an index name is unique within a user account. In Microsoft SQL Server, an index name must be unique within a table name, but it does not have to be unique within a user account or database. Therefore, when creating or dropping an index in SQL Server, you must specify both the table name and the index name. Additionally, the SQL Server DROP INDEX statement can drop multiple indexes at one time.
| Oracle | Microsoft SQL Server |
|---|---|
| CREATE [UNIQUE] INDEX [schema].index_name ON [schema.]table_name (column_name [, column_name]...) [INITRANS n] [MAXTRANS n] [TABLESPACE tablespace_name] [STORAGE storage_parameters] [PCTFREE n] [NOSORT] DROP INDEX ABC; |
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX index_name ON table (column [,…n]) [WITH [PAD_INDEX] [[,] FILLFACTOR = fillfactor] [[,] IGNORE_DUP_KEY] [[,] DROP_EXISTING] [[,] STATISTICS_NORECOMPUTE] ] [ON filegroup] DROP INDEX USER_DB.STUDENT.DEMO_IDX, USER_DB.GRADE.DEMO_IDX |
The FILLFACTOR option in Microsoft SQL Server functions in much the same way as the PCTFREE variable does in Oracle. As tables grow in size, index pages split to accommodate new data. The index must reorganize itself to accommodate new data values. The fill factor percentage is used only when the index is created, and it is not maintained afterwards.
The FILLFACTOR option (values are 0 through 100) controls how much space is left on an index page when the index is initially created. The default fill factor of 0 is used if none is specified–this will completely fill index leaf pages and leave space on each decision node page for at least one entry (two for nonunique clustered indexes).
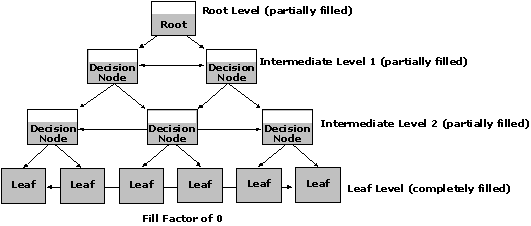
A lower fill factor value initially reduces the splitting of index pages and increases the number of levels in the B-tree index structure. A higher fill factor value uses index page space more efficiently, requires fewer disk I/Os to access index data, and reduces the number of levels in the B-tree index structure.
The PAD_INDEX option specifies that the fill factor setting be applied to the decision node pages as well as to the data pages in the index.
While it may be necessary to adjust the PCTFREE parameter for optimal performance in Oracle, it is seldom necessary to include the FILLFACTOR option in a CREATE INDEX statement. The fill factor is provided for fine-tuning performance. It is useful only when creating a new index on a table with existing data, and then it is useful only when you can accurately predict future changes in that data.
If you have set PCTFREE to 0 for your Oracle indexes, consider using a fill factor of 100. This is used when there will be no inserts or updates occurring in the table (a read-only table). When fill factor is set to 100, SQL Server creates indexes with each page 100 percent full.
With both Oracle and Microsoft SQL Server, users cannot insert duplicate values for a uniquely indexed column or columns. An attempt to do so generates an error message. Nevertheless, SQL Server lets the developer choose how the INSERT or UPDATE statement will respond to the error.
If IGNORE_DUP_KEY was specified in the CREATE INDEX statement, and an INSERT or UPDATE statement that creates a duplicate key is executed, SQL Server issues a warning message and ignores (does not insert) the duplicate row. If IGNORE_DUP_KEY was not specified for the index, SQL Server issues an error message and rolls back the entire INSERT statement. For more information about these options, see SQL Server Books Online.