Entity integrity defines a row as a unique entity for a particular table. Entity integrity enforces the integrity of the identifier column(s) or the primary key of a table through indexes, UNIQUE constraints, PRIMARY KEY constraints, or IDENTITY properties.
You should always name your constraints explicitly. If you do not, Oracle and Microsoft SQL Server will use different naming conventions to name the constraint implicitly. These differences in naming can complicate your migration process unnecessarily. The discrepancy appears when dropping or disabling constraints, because constraints must be dropped by name. The syntax for explicitly naming constraints is the same for Oracle and SQL Server:
CONSTRAINT constraint_name
The SQL-92 standard requires that all values in a primary key be unique and that the column not allow null values. Both Oracle and Microsoft SQL Server enforce uniqueness by automatically creating unique indexes whenever a PRIMARY KEY or UNIQUE constraint is defined. Additionally, primary key columns are automatically defined as NOT NULL. Only one primary key is allowed per table.
A SQL Server clustered index is created by default for a primary key, though a nonclustered index can be requested. The Oracle index on primary keys can be removed by either dropping or disabling the constraint, whereas the SQL Server index can be removed only by dropping the constraint.
In either RDBMS, alternate keys can be defined with a UNIQUE constraint. Multiple UNIQUE constraints can be defined on any table. UNIQUE constraint columns are nullable. In SQL Server, a nonclustered index is created by default, unless otherwise specified.
When migrating your application, it is important to note that SQL Server allows only one row to contain the value NULL for the complete unique key (single or multiple column index), and Oracle allows any number of rows to contain the value NULL for the complete unique key.
| Oracle | Microsoft SQL Server |
|---|---|
| CREATE TABLE DEPT_ADMIN.DEPT (DEPT VARCHAR2(4) NOT NULL, DNAME VARCHAR2(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY (DEPT) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE ( INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE (DNAME) USING INDEX TABLESPACE USER_DATA PCTFREE 0 STORAGE ( INITIAL 10K NEXT 10K MINEXTENTS 1 MAXEXTENTS UNLIMITED) ) |
CREATE TABLE USER_DB.DEPT_ADMIN.DEPT (DEPT VARCHAR(4) NOT NULL, DNAME VARCHAR(30) NOT NULL, CONSTRAINT DEPT_DEPT_PK PRIMARY KEY CLUSTERED (DEPT), CONSTRAINT DEPT_DNAME_UNIQUE UNIQUE NONCLUSTERED (DNAME) ) |
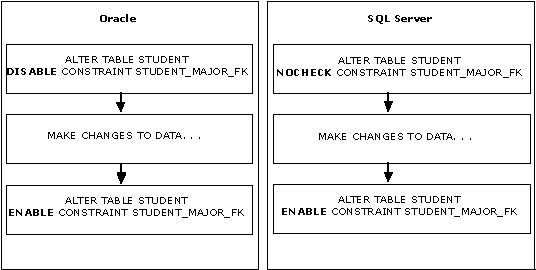
Disabling constraints can improve database performance and streamline the data replication process. For example, when you rebuild or replicate table data at a remote site, you do not have to repeat constraint checks, because the integrity of the data was checked when it was originally entered into the table. You can program an Oracle application to disable and enable constraints (except for PRIMARY KEYand UNIQUE). You can accomplish this in Microsoft SQL Server using the CHECK and WITH NOCHECK options with the ALTER TABLE statement.
This illustration shows a comparison of this process.
With SQL Server, you can defer all of the table constraints by using the ALL keyword with the NOCHECK clause.
If your Oracle application uses the CASCADE option to disable or drop PRIMARY KEY or UNIQUE constraints, you may need to rewrite some code because the CASCADE option disables or drops both the parent and any related child integrity constraints.
This is an example of the syntax:
DROP CONSTRAINT DEPT_DEPT_PK CASCADE
The SQL Server application must be modified to first drop the child constraints and then the parent constraints. For example, in order to drop the PRIMARY KEY constraint on the DEPT table, the foreign keys for the columns STUDENT.MAJOR and CLASS.DEPT must be dropped. This is an example of the syntax:
ALTER TABLE STUDENT
DROP CONSTRAINT STUDENT_MAJOR_FKALTER TABLE CLASS
DROP CONSTRAINT CLASS_DEPT_FKALTER TABLE DEPT
DROP CONSTRAINT DEPT_DEPT_PK
The ALTER TABLE syntax that adds and drops constraints is almost identical for Oracle and SQL Server.
If your Oracle application uses SEQUENCEs, it can be altered easily to take advantage of the Microsoft SQL Server IDENTITY property.
| Category | Microsoft SQL Server IDENTITY |
|---|---|
| Syntax | CREATE TABLE new_employees ( Empid int IDENTITY (1,1), Employee_Name varchar(60), CONSTRAINT Emp_PK PRIMARY KEY (Empid) ) If increment interval is 5: CREATE TABLE new_employees ( Empid int IDENTITY (1,5), Employee_Name varchar(60), CONSTRAINT Emp_PK PRIMARY KEY (Empid) ) |
| Identity columns per table | One |
| Null values allowed | No |
| Use of default constraints, values | Cannot be used. |
| Enforcing uniqueness | Yes |
| Querying for maximum current identity number after an INSERT, SELECT INTO, or bulk copy statement completes | @@IDENTITY (function) |
| Returns the seed value specified during the creation of an identity column | IDENT_SEED('table_name') |
| Returns the increment value specified during the creation of an identity column | IDENT_INCR('table_name') |
| SELECT syntax | The keyword IDENTITYCOL can be used in place of a column name when you reference a column that has the IDENTITY property, in SELECT, INSERT, UPDATE, and DELETE statements. |
Although the IDENTITY property automates row numbering within one table, separate tables, each with its own identifier column, can generate the same values. This is because the IDENTITY property is guaranteed to be unique only for the table on which it is used. If an application must generate an identifier column that is unique across the entire database, or every database on every networked computer in the world, use the ROWGUIDCOL property, the uniqueidentifier data type, and the NEWID function. SQL Server uses globally unique identifier columns for merge replication to ensure that rows are uniquely identified across multiple copies of the table.
For more information about creating and modifying identifier columns, see SQL Server Books Online.