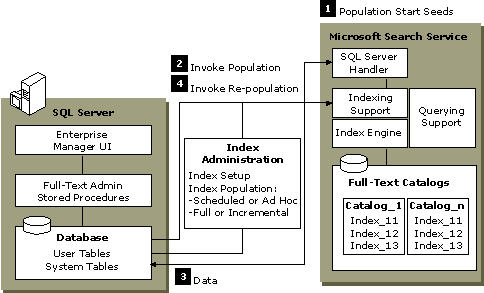
The indexing components manage the initial population and subsequent updating of the full-text indexes.
Before presenting the steps involved in the indexing process, various subcomponents are introduced, and then the flow among the subcomponents is described.
SQL Server Enterprise Manager is the GUI for the full-text indexing administration utility. It takes the form of extensions to the current Microsoft SQL Server Enterprise Manager property sheets, and a new wizard. These have been designed to assist first-time and infrequent administrators of full-text indexed tables. The GUI also is appropriate for frequent users. It allows a user to select the desired tables for full-text indexing and walks the user through the various steps needed to set this up.
One option is to schedule regular refreshing of full-text indexes; this uses the scheduling facilities that already exist in SQL Server. The GUI also can be used to display properties of the full-text indexed tables. This GUI uses a set of new full-text administration system stored procedures, a set of full-text related properties available through the SQL Server property functions, as well as the existing SQL Server Agent job scheduler.
This set of system stored procedures is used to:
The setup and configuration capabilities of full-text indexing reside in the stored procedures, not in the GUI. It is possible to use these stored procedures directly rather than using SQL Server Enterprise Manager, and experienced administrators may choose to do this. Calls to the stored procedures also may be embedded in scripts and other stored procedures.
The set of stored procedures (such as sp_add_jobschedule) that is used for scheduling regular jobs also can be used to schedule refreshes of full-text catalogs.
The sysdatabases system catalog has been extended to provide the new IsFulltextEnabled property, which is available through the DATABASEPROPERTY() function.
A new system table, sysfulltextcatalogs, is present for each database. This table holds metadata about the full-text catalogs that are linked to the database. A given full-text catalog is linked to only one database.
The sysobjects, sysindexes, and syscolumns tables that reside in each database are augmented with information about the tables and the associated columns in that database that have been full-text indexed. The information is:
This is a Windows NT service that has two roles:
Microsoft Search Service operates under the context of the local system account. This service must be run on the same computer as SQL Server.
The information about populating full-text indexes is submitted in the form of a population start seed value, which uniquely identifies both the database and the table that needs to be full-text indexed. When the service is ready to handle the population, it invokes the SQL Server Handler driver.
This subcomponent is a driver that plugs into indexing support and is specially coded to handle SQL Server data stores.
SQL Server Handler always runs in the same process as Microsoft Search Service.
This subcomponent presents indexable units of text (in the form of character strings), each with an identifying key. It scans through character strings, determines the word boundaries, removes all noise words, and then populates a full-text index with the remaining words.
This is where full-text indexes reside. This is a Windows NT file-system directory that is accessible only by Windows NT Administrator and Microsoft Search Service. The full-text indexes are organized into full-text catalogs, which are referenced by friendly names. Typically, the full-text index data for an entire database is placed into a single full-text catalog. However, administrators can partition the full-text index data for a database across more than one full-text catalog. This is useful if one or more of the tables being full-text indexed contains a large number of rows. A full-text catalog is limited to holding index data for 231 to 64K rows.
In SQL Server 7.0, there are no facilities to coordinate backup and recovery relational database data in conjunction with the relevant indexes in the full-text catalogs (however there are facilities to resynchronize them). Coordinated backup and recovery is a candidate for a future release of SQL Server.
The following steps are started by an administrator using GUIs or stored procedures (either on demand or as scheduled).
If a table has a row-versioning (timestamp) column, repopulation can be handled more efficiently. At the time the population start seed for a table is constructed, the largest row-versioning value in the database is remembered. When an incremental population is requested, the SQL Server handler connects to the database and requests only rows where the row-versioning value is greater than the remembered value.
During an incremental population, if there is a full-text indexed table in a catalog that does not have a row-versioning column, then that table will be completely repopulated.
There are two cases where a complete repopulation is performed, even though there is a row-versioning column on the table. These are:
After populating tables with a row-versioning column, the remembered row-versioning value is updated.
Since incremental repopulation on relatively static tables with timestamp columns can be completed faster than a complete repopulation, users can schedule repopulation on a more frequent basis. For a given database, users should take care not to mix index data from tables with timestamp columns with tables in the same full-text catalog, because these two groups of tables usually should be on separate repopulation schedules.