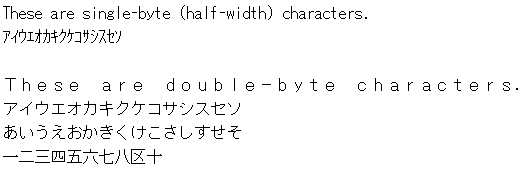
Glossary
The Chinese language defines more than 10000 basic ideographic characters. Many of these characters were borrowed or adapted for other writing systems long ago. These characters are called hantsu or hanzi in Chinese, kanji in Japanese, and hanja in Korean. Single-byte character sets are too small to accommodate these languages. Once you have assigned 256 code points (that is, indexes to the code page), what do you do with the rest of the several thousand characters that Chinese or Japanese readers and writers typically use every day?
A solution commonly used on PCs is to encode most characters (primarily ideographs) with 2-byte values, thus making room for far more than 256 characters. The key phrase in the previous sentence is "most characters"—characters such as those in the ASCII set and the Japanese phonetic syllabary known as katakana still have single-byte representations. The result is a code page that mixes single-byte and double-byte characters. You can actually see the difference when typing text using most fonts on Far East editions of Windows. (See Figure 3-1.) Ideographic characters exist only in full-width form; there's no such thing as a single-byte kanji character.
Figure 3-1 Half-width ASCII characters followed by half-width katakana characters; and full-width ASCII characters followed by full-width katakana, hiragana, and kanji characters. Notice how the columns line up.
On other systems, such as some Unix systems, characters can be represented by as many as 3 bytes. (See Figure 3-2.) Character sets that mix character codes of 1, 2, and 3 bytes are generally called multibyte character sets. Double-byte character sets are specific types of multibyte character sets, in contrast with Unicode, in which each character is always 16 bits wide.
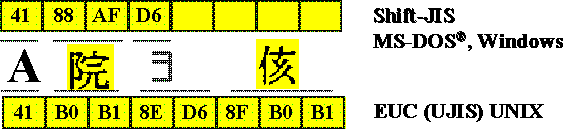
Figure 3-2 Multibyte character sets.
The mixing of byte lengths in multibyte character sets used by Far East editions of Windows leads to more complex string-parsing code. Figure 3-3 gives an example of a Shift-JIS string and the different code-point ranges that can appear: ASCII, Lead Byte-s trail bytes, and kana. Each byte does not necessarily represent a single character. For this reason, developers must exercise caution when coding string-parsing routines.
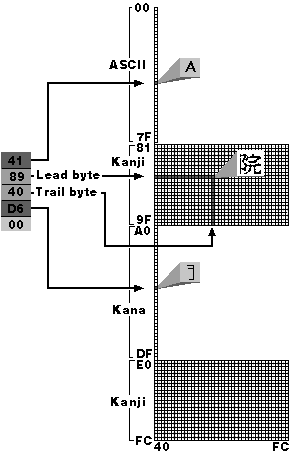
Figure 3-3 A Shift-JIS string. Four code ranges are shown: ASCII (0x00 through 0x7F), the first Shift-JIS lead-byte range (0x81 through 0x9F), kana (0xA0 through 0xDF), and the second lead-byte range (0xE0 through 0xFC).