
Glossary
Unicode is an integral part of Windows NT. Windows NT handles characters internally in Unicode and supports all of the wide-character variants of the Win32 API. The Windows NT GDI processes all text in Unicode, the resource compiler compiles strings into Unicode, system information files are stored as Unicode, and the Windows NT file system (NTFS) filenames are always in Unicode. Machines running Windows NT always exchange data on the network in Unicode format unless they are communicating with non-Unicode workstations, such as those running Microsoft Windows for Workgroups 3.11 or LAN Manager. (See Figure 3-13.)
Figure 3-13 Unicode on Windows NT.
Whereas tailoring programs for some language editions of Windows 95 requires modifying code for specific character sets, writing programs for the wide-character version of the Win32 API does not; programs will run unaltered on all language editions of Windows NT because all editions support Unicode. Keep in mind that to have a fully functional application for Far Eastern languages, however, you will still need to add support for Input Method Editors. (See Chapter 7.)
Windows NT demonstrates how Unicode can facilitate the creation of different language editions of a product. Unicode was an integral part of the design of Windows NT from the beginning. Since the code didn't have to be adjusted to handle a mixed-width character set such as Shift-JIS, many of the system modules could be left unchanged for the Japanese edition. (See Figure 3-14.) In fact, the Win32 API for Japanese Windows NT is exactly the same as the English API, except for 12 additional functions related to Input Method Editors (IMEs). Microsoft was able to release Japanese Windows NT six months after the US edition was released—a full year shorter than the time between the release of US and Japanese editions of Windows 3.1.
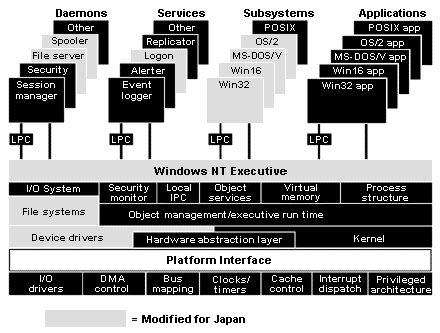
Figure 3-14 Many Windows NT modules remained unchanged when the Japanese edition was created. For Windows 3.1, almost all pieces of the system had to be modified.
Because the system is based on Unicode, Win32-based applications that use Unicode will run more efficiently on Windows NT and can process as many characters as the system can. This is especially true for programs localized for Far Eastern languages. Because the Windows NT system converts non-Unicode API parameters to Unicode at run time, not using Unicode adds a layer of overhead to some function calls and message processing. In addition, the system converts text returned from function calls to a local character set for non–Unicode-based applications, and information can be lost during the conversion because, like Windows 3.x, Windows NT supports only one local code page at a time. If the installed local code page is Latin 1 and the application calls GetLocaleInfoA to retrieve the Russian word for January, the system returns a string of question marks because there are no Cyrillic characters in the Latin 1 code page. A similar conversion process takes place for Windows messages and clipboard text.
You can base applications for Windows NT on Windows code pages by using the -A versions of the Win32 API entry points. (Console applications can also use MS-DOS OEM code pages.) An -A API entry point eventually calls the -W version of the same API. The system takes care of the necessary character code conversions by calling MultiByteToWideChar and WideCharToMultiByte.
Similarly, Windows NT converts string parameters of Windows messages that are passed between a Unicode and a non-Unicode window procedure. You should register a window class that expects Unicode string parameters using RegisterClassW. If another application passes a message with non-Unicode parameters to this window (the Japanese Windows NT IME applet, for example, passes strings in Shift-JIS), Windows NT will convert the parameters into Unicode. This automatic code conversion supplied by Windows NT is convenient and makes it possible for Unicode-based applications to interact with applications that do not support Unicode, though the range of characters that can be transferred between applications is much smaller than the full Unicode range.
In addition to supporting the -A versions of the Win32 API, all language editions of Windows NT support one Windows code page and one MS-DOS code page for the benefit of MS-DOS and 16-bit Windows-based applications. By default, US Windows NT supports the Latin 1 code page 1252 and MS-DOS code page 437. Japanese Windows NT supports the Shift-JIS character set for both. The constants CP_ACP (for the ANSI or Windows code page) and CP_OEMCP (for the OEM code page) resolve to the default code-page values set by the user. These macros are useful for Win32 API calls that require a Windows or OEM code-page number as a parameter, such as WideCharToMultiByte and IsDBCSLeadByteEx. The following table lists API functions that enumerate, set, and retrieve code-page IDs. Code-page ID numbers are listed in Appendix E.
| Win32 API Functions |
| API | Function |
| EnumSystemCodePages | Enumerates the system code pages (including OEM, ANSI, and EBCDIC) that are either installed or supported, depending on the specified flags |
| GetACP | Returns the code-page ID for the installed Windows code page |
| GetConsoleCP | Returns the code-page ID of the current console code page |
| GetConsoleOutputCP | Returns the code-page ID of the current console output code page |
| GetCPInfo | Returns a structure containing the maximum width of a character in the specified code page; the lead-byte ranges, if any; and the code page's default character, used in conjunction with WideCharToMultiByte |
| GetOEMCP | Returns the code-page ID for the installed MS-DOS or OEM code page |
| IsDBCSLeadByteEx | Returns whether a character is a lead byte in the specified code page |
| IsValidCodePage | Determines whether a code page is installed in the system |
| SetConsoleCP | Sets the code-page ID of the current console code page |
| SetConsoleOutputCP | Sets the code-page ID of the current console output code page |