Several Win32 API calls are useful for manipulating Unicode
data. LCMapStringW can map a character string to
uppercase, to lowercase, or even to a sort key based on a locale
ID. CompareStringW provides locale-sensitive string
comparison. Both LCMapStringW and CompareStringW
can handle Unicode strings and Unicode idiosyncrasies such as
nonspacing characters. CompareStringW carries an option to
ignore a character's case, width, or accents when comparing
character strings. This option is the preferred way to compare a
with A or ä. If you specify the right flags, you
can even equate more disparate characters, such as the German ß
with SS or the hiragana ![]() with the katakana
with the katakana ![]() .
.
GetStringTypeW can be used to test whether characters are alphabetic characters, numeric characters, punctuation, right-to-left characters, hiragana, and so on. In this case, the return values are not locale-sensitive but are based on Unicode classifications. Thus, Greek letters are always tagged as alphabetic, even though in English they are often used as symbols. (GetStringTypeA, CompareStringA, and LCMapStringA are based on code pages, not on Unicode, in Win32s and Windows 95. The results of the -A and -W API calls are identical, however.)
Like LCMapStringW, FoldStringW maps strings, but like GetStringTypeW, the conversions are based solely on Unicode rules and are not locale-sensitive. FoldStringW provides a way to map any kind of digit (such as Arabic-Hindi, kanji, or Thai) to ASCII '0' through '9' and also maps between an accented character and its composed forms—a plain character followed by one or more nonspacing accent marks.
See Figure 3-15 below:
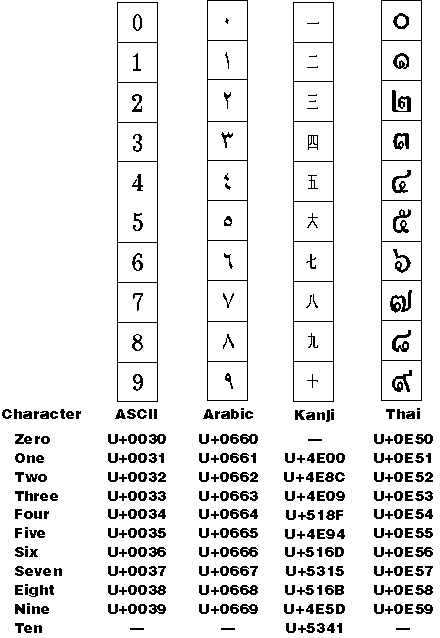
Figure 3-15 ASCII, Arabic-Hindi, kanji, and Thai numbers.
The FoldStringW function can also map characters in Unicode's compatibility zone into standard Unicode characters. The compatibility zone contains characters that aren't part of Unicode's standard range because they duplicate existing characters but are necessary for one-to-one round-trip conversion between Unicode and other standards. For example, the full-width ASCII characters and the half-width katakana characters in Shift-JIS are mapped to Unicode's compatibility zone (see Figure 3-16). They duplicate the half-width ASCII and the full-width katakana characters of Shift-JIS, which are mapped to Unicode's standard range. The compatibility zone also contains vertical alternates of some glyphs and variants of Arabic characters. FoldStringW is useful when it's not important to preserve round-trip conversion or when it's unnecessary to distinguish between character variants. For example, if you are looking for all instances of the letter A, half-width and full-width forms are equivalent.
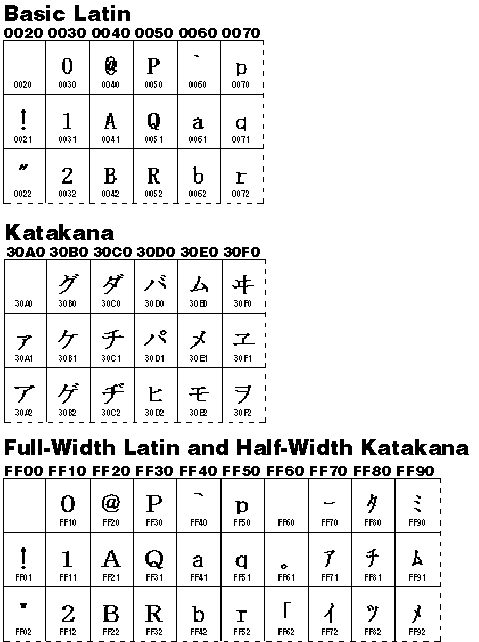
Figure 3-16 Excerpts from the half-width ASCII characters (0x20 through 0x7F in Shift-JIS), the full-width katakana characters (0x8340 through 0x8396 in Shift-JIS), the full-width Latin alphabet (0x8249 through 0x829A in Shift-JIS), and the half-width katakana characters (0xA6 through 0xDF in Shift-JIS) as they appear in Unicode. The full-width Latin and half-width katakana characters are part of the compatibility zone.
Windows NT also takes advantage of Unicode's private-use zone. The system maps the end-user defined character (EUDC) ranges set aside in Windows 3.1–based Far East code pages to the private-use zone, but it doesn't assign any fonts, glyphs, or other special semantics to these characters. These characters sort together as a group in numeric code-point order and sort last after all other script ranges. Because the private-use characters could be anything, depending on the application, Windows NT does not allow private-use characters in user names, share names, volume labels, or filenames. They are more or less banned from the system name space.