April 20, 1999
See also:
"Dr. GUI and COM Automation, Part 1"
"Dr. GUI and COM Automation, Part 2"
Dr. GUI's Bits and Bytes
Where We've Been; Where We're Going
Give It a Shot!
Where We've Been; Where We're Going
Just before deadline for this column, Dr. GUI received a book every ATL programmer should have: ATL Internals, written by Brent Rector and Chris Sells (published by Addison-Wesley). It's excellent—the book the folks who created ATL wish they'd written. (See the quote from ATL lead Jim Springfield.) Check it out at http://cseng.aw.com/bookdetail.qry?ISBN=0-201-69589-8&ptype=0, and check out the very interesting reviews at Amazon.com.
Dr. GUI got a piece of mail saying Time magazine had named Tim Berners-Lee as one of the Time 100—one of the 100 most important people of the twentieth century (which, by the way, doesn't end until the end of the year 2000). See the article about him at http://cgi.pathfinder.com/time/time100/scientist/profile/bernerslee.html.
While you're there, you might want to check out other folks important to computing, such as Alan Turing (http://cgi.pathfinder.com/time/time100/scientist/profile/turing.html), William Shockley (http://cgi.pathfinder.com/time/time100/scientist/profile/shockley.html), Thomas Watson, Jr. (http://cgi.pathfinder.com/time/time100/builder/profile/watson.html), and Bill Gates (http://cgi.pathfinder.com/time/time100/builder/profile/gates.html).
Check out the other 75 profiles at http://cgi.pathfinder.com/time/time100/index.html. (The last 20, Heroes and Inspirations, won't be posted until June.) The articles are generally well written. (The good doctor quibbles about the tone of the Gates article a bit, but then Dr. GUI admits a bias in Bill's favor.)
Dr. GUI's been steadfastly resisting to write about streaming media (for the most part), despite the pleas of various marketing people. But the new audio format has Dr. GUI jazzed—it's both streamable and downloadable. It's half the size of MP3 and gives equal or better sound quality, and authors can use licensing to protect their work if they choose.
Dr. GUI hasn't had a chance to download the Windows Media Audio SDK, but check it out. It's only 836 KB, so it's not a huge download.
Dr. GUI is pleased to announce that MSDN will soon have a new columnist: We've hired Bobby Schmidt, who, among other things, writes for C/C++ User's Journal. Bobby has a wealth of experience inside Microsoft (including product support and development) and outside of Microsoft (including working with P.J. Plauger and Metrowerks). He's planning to focus on helping C++ programmers use their language more effectively. Dr. GUI is pleased to work with him, and he knows you'll be pleased to read his column when it debuts on MSDN Online Voices next month.
Bobby hasn't worked with Windows boxes much—he's a Mac kind of guy. So as he was working on figuring out what to write, he asked the good doctor whether he really needed to install the MSDN CD/DVD.
Well, Dr. GUI ALWAYS uses the CD/DVD when he can—he likes the speed ever so much better. But because we have a great connection to the Internet here, Bobby and the good doctor were wondering whether the MSDN Online Library could replace the CD/DVD.
The answer was simple: No. Not yet.
Here's why:
All of the content is there, and the tree control table of contents is there, too—but as soon as you need to search or use the index, you'll be in pain. MSDN Online Library is a great Web site, but it still has a way to go before it's as useful to developers as the CD/DVD.
How come? Well, it's simple: HTML/HTTP was not originally developed as an applications platform. It was originally developed as a way to display hyperlinked text. But it wasn't particularly good at that, either: Its layout capabilities were incredibly primitive. It's been amazing—Time had it right when they honored Tim Berners-Lee, but HTML is clearly not the be-all and end-all.
Now, HTML/HTTP has been extended this way and that to improve its layout capabilities and its programmability, but it's still not a premier applications platform. There are a lot of applications that work great in HTML, but it's very easy to run into severe limitations when you're trying to do serious client-server or distributed applications development in HTML/HTTP.
So, part of the reason the Web version of the Library isn't as good is simple: It's really hard to do it right because the platform is limited. The Web doesn't solve all problems.
By the way, if you develop software for a living, the money you spend on the MSDN Library or other MSDN products is well worth it (see subscription info). You will save enough time looking up things that it'll pay for itself before you know it. And every copy of Microsoft Visual Studio comes with a free special edition copy of the MSDN Library.
This is the third of three parts about COM Automation. Yes! We're done! On to COM events next time!
Last time, we talked about VARIANTs. This time, we'll talk about the other special data types COM provides—BSTR, DATE, CURRENCY, DECIMAL, and SAFEARRAY. And we'll talk about collections and error objects for reporting extended error information.
Many COM strings are passed using a C/C++ style zero-terminated string (LPOLESTR) that consists of a pointer to a Unicode string. Each character in a Unicode string (including the zero terminator) occupies 2 bytes. (You can learn more about Unicode at http://www.unicode.org/.) Because each Unicode character occupies 2 bytes, there are 65,536 possible Unicode characters—more than enough to represent all of the characters in almost all of the world's languages, including most Asian languages.
For Automation, however, the supported string format is BSTR. The "B" stands for Basic—this is the string format Microsoft Visual Basic® uses internally. A BSTR is a pointer to an LPOLESTR zero-terminated string. The difference is in what comes before the string: the length of the string (in bytes, not counting the terminator) is stored in the 4 bytes immediately preceding the first character of the string. Note that because we know the length of the string, it is possible to have characters containing binary zero within the string as well, so be careful when you manipulate BSTR strings that might contain embedded zeroes, especially strings passed to you by others.
BSTR strings are also used for passing string data between COM components using strings allocated with COM's memory allocator. (This allocator allows you to allocate a string in one component and free it in another, regardless of what process or machine the two components are running on.)
Here's a simple example of allocating and freeing a BSTR using the COM APIs SysAllocString and SysFreeString:
BSTR bstrMsg = SysAllocString(OLESTR("Hello"));
// call some method that expects a BSTR or LPOLESTR passing bstrMsg
ptrInterface->Method(bstrMsg);
Note that we insured we had the right type of string constant by using the OLESTR macro. For Microsoft Win32®, this puts an uppercase "L" in front of the string, changing our string to the Unicode wide character string:
L"Hello"
We could have just written the "L" ourselves, but using the macro insures that the right thing happens on all platforms.
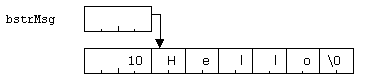
The resulting string looks like the following in memory. Note that the pointer points to the first byte of the Unicode string, not to the count.
The count is unusual: it contains the number of bytes, not characters, in the string. This count doesn't include the terminating zero character (2 bytes). So, for the five-character string "Hello," the count contains 10.
Note that the allocation is at least 16 bytes for this string: four for the count, 10 to contain the 5 Unicode characters (at 2 bytes each), and two for the terminating zero character.
When we're done with it, we free the BSTR like this:
SysFreeString(bstrMsg);
The second thing to note is that we could have passed the BSTR to another component, even on another machine, and that other component could have called SysFreeString to free the string. COM makes sure the right thing gets done.
We've seen some of the COM API already: SysAllocString and SysFreeString. In addition, there are SysAllocStringLen and SysAllocStringByteLen to allocate a fixed-length string or a string containing binary data (perhaps including zero bytes), SysReAllocString and SysReAllocStringLen to reassign a BSTR (including freeing the old BSTR), and SysStringLen and SysStringByteLen to return the length of the string in characters and bytes.
Access the characters in the string by using pointer arithmetic and the standard C/C++ string functions. You cannot change the length of the string—if you need to, create a C/C++ Unicode string and use one of the SysReAllocString functions to update the BSTR.
You can convert BSTR strings to one-dimensional safe arrays (more on safe arrays later) with VectorFromBstr and BstrFromVector.
There is also a pair of currently undocumented functions that might be useful. VarBstrCat concatenates two BSTR strings into a third, and VarBstrCmp compares two BSTR strings, returning VTCMP_LT, VTCMP_EQ, VTCMP_GT, or VTCMP_NULL.
Microsoft Foundation Classes (MFC) doesn't have a helper class that wraps BSTR; instead, it takes a different approach by allowing you to easily convert between BSTR and MFC's CString class. To convert from a BSTR to a CString, just pass the BSTR to the CString constructor, as in:
CString strFoo(bstrMsg);
To convert a CString to a BSTR, use one of the two methods of the CString class: AllocSysString to create a new BSTR, or SetSysString to reallocate a BSTR.
ATL provides the CComBSTR class to provide an easier interface to BSTR strings. In addition to creating, assigning, and freeing the strings, CComBSTR also provides methods for concatenating strings.
Microsoft Visual C++® version 5.0 and later support the _bstr_t class to provide a more sophisticated wrapper for BSTR. In addition to the functionality of CComBSTR, _bstr_t also provides comparison operators. In addition, _bstr_t avoids allocating extra BSTR objects by using reference counting—more efficient, but not as thin a wrapper as the CComBSTR.
You can also use the C++ Standard Library's wstring class, but you'll have to convert to and from BSTR. You can convert from BSTR to wstring by constructing a new wstring object using the appropriate constructor. You convert to a BSTR by getting a pointer to the string wrapped by the wstring object and calling one of the COM APIs that allocate a BSTR, such as SysAllocString.
Dr. GUI hopes you know that binary floating-point types, such as float and double in C, C++, or Java and Single and Double in Visual Basic, cannot represent decimal fractions with perfect precision. By the same token, decimal numbers cannot represent some fractions with perfect precision. (For instance, decimal representation cannot represent 1/3 accurately.) In both cases, you can get as close as you need for most practical purposes by adding more digits, but you'll never have perfect representation. And the number of digits is limited in a computer, anyway.
This anomaly shows up in programs that deal with money. For instance, if you try to find the value of 10 million pennies with the following program, you'll get $99,999.999986, not $100,000, as the result.
double acc = 0;
for (int i = 0; i < 10000000; i++) {
acc = acc + 0.01;
}
printf("Accumulated value is $%f\n", acc);
The error is small, but small errors can accumulate. And you know how accountants hate to be off by even a penny.
The problem isn't a shortcoming of any sort—it's simply that the data type, which is a binary fraction (where the bits represent one over a power of two, such as 1/2, 1/4, 1/8, 1/16, and so forth), cannot represent fractions such as 1/10 and 1/100 with perfect accuracy.
You can try to work around these problems by rounding carefully, or you can use a data representation that accurately represents decimal fractions. (We've still not fixed the 1/3 problem, however. That takes a rational number representation with a separate numerator and denominator—but even that won't represent irrational numbers such as e and pi.)
One common method is to use integers to represent decimal numbers and divide the number by 100, 1,000, or 10,000 before you print it. In other words, adding one to the integer really adds a penny, a tenth of a penny, or a hundredth of a penny, depending on the representation. To put it another way, you'd have to add 100, 1,000, or 10,000 to the integer to add a dollar, again depending on the representation.
Another representation is to use binary coded decimal (BCD), in which each decimal digit is stored in four bits, so each byte stores two decimal digits, 0-99.
The integer storage method has the huge advantage that you can use standard 64-bit integer operations to do math. Algorithms for doing math with BCD are really ugly and slow. (Intel processors have BCD math built into the floating-point section of the processor, so there's no speed problem with BCD there: They convert the BCD number to an 80-bit floating-point number containing an integer.)
The COM CY and Visual Basic Currency type is a signed 64-bit integer in units of 1/10,000 (or 1/100 of a cent). The currency type can accurately represent dollars and cents values, so it's good for financial calculations. The range of the currency type is more than +/- 900 trillion, so it'll even cover calculations of the national debt, at least for the foreseeable future. (If that's not enough, use the DECIMAL type described later.)
The only documented COM API for dealing with the currency type is the set of 20 or 30 conversion functions to convert to or from other types. If you use the _int64 data type, you can do most math operations safely because the currency type is an integer.
There is also a set of currently undocumented currency math functions that appear similar to the corresponding variant math functions. The set of functions includes: VarCyAdd, VarCyMul, VarCyMulI4, VarCySub, VarCyAbs, VarCyFix, VarCyInt, VarCyNeg, VarCyRound, VarCyCmp, and VarCyCmpR8. VarCyMulI4 and VarCyCmpR8 use long and double for the second parameter. This is more efficient than converting other types to the currency type. Note that there currently is no function to do division.
The selection of C++ currency classes is much smaller: Only MFC has a wrapper class, COleCurrency. COleCurrency has arithmetic and comparison operators, members for formatting a currency object as a string and parsing a string to get a currency object, and the usual constructors, destructors, and assignment operators.
So, 900 trillion isn't big enough for you, huh? Well, if you need accurate decimal representation of numbers up to 28 decimal digits, you'll want to use a DECIMAL. A DECIMAL fits in 16 bytes—exactly the same as a VARIANT. It uses two bytes that are reserved (used for the VT_DECIMAL tag), a byte for the scale, a byte for the sign, and the remaining 12 bytes (96 bits) for the integer number. Adding another 32 bits to the integer means you can handle numbers with 28 or 29 decimal digits—that's one big number! Because you can set the scaling (the number of digits to the right of the decimal point) from 0 to 28, the DECIMAL type is much more flexible in terms of the numbers it can hold. However, doing math with DECIMAL numbers is S-L-O-W. If you don't need the extended capacity, use the currency type instead—they're much faster.
The only documented COM API for dealing with the DECIMAL type is the set of 20 or 30 conversion functions to convert to or from other types.
The soon-to-be-documented functions found in OLEAUTO.H do what you'd expect, even division. The functions are VarDecAdd, VarDecDiv, VarDecMul, VarDecSub, VarDecAbs, VarDecFix, VarDecInt, VarDecNeg, VarDecRound, VarDecCmp, and VarDecCmpR8.
Ah—no such luck. DECIMAL was relatively recently added to COM, so there are no helper classes—not even in MFC.
The COM DATE type represents both a date and a time. The date and time are stored as an 8-byte floating-point number (in C/C++/Java, double). The whole part of the number represents the day; the fractional part represents the time within the day. The format can represent time from January 1, 100, to December 31, 9999—no Y2K problem here. (But there is a Y10K problem, which is not nearly as bad as having a D10K problem. Dr. GUI's not sweating it.)
One note: Because the time is represented as the fractional part of a binary floating-point number, it is not possible to represent many times exactly. Only times that are sums of binary fractions of a day—such as any sum of 1/2 (12 hours), 1/4 (6 hours), 1/256 (5.625 minutes), and so on—can be represented exactly. So, for instance, one hour, one minute, and one second cannot be represented exactly.
Because you generally don't do repeated calculations using time values, the rounding isn't usually a big issue—but you should be aware of it. Also, the representation of the time has less resolution the farther you are from midnight, 30 December 1899 (which is represented by zero), because there are more bits required to represent the day, leaving fewer to represent the time. Don't worry about this scaling, however: It takes a maximum of 22 bits to represent the day (in 9999 AD), which leaves about 40 bits to represent the time. It only takes about 24 bits to represent 1/100 of a second, so there are 16 bits left over to add even more accuracy.
The COM API for dealing with dates is very small: There's the previously mentioned VarFormatDateTime function, the 20 or 30 conversion functions, VarWeekdayName and VarMonthName to get a string with the local name of the day of the week or the month, and GetAltMonthNames to get a list of alternate month names (useful only for Hijrah Arabic lunar, Polish, and Russian alternate month names).
You can do date arithmetic by adding or subtracting a number representing the number of days to a DATE object. You'll simply use the standard floating-point math to do the addition or subtraction. For instance, to advance one day, add one to a DATE object; to go back six hours, subtract 0.25 from a DATE object. Note, though, that it's very hard to advance a month or a year, because the number of days per month and year vary.
There are also two very handy functions for unpacking a DATE into a structure that contains a SYSTEMTIME structure and the day of the year (one for January 1, 32 for February 1, and so on) and for packing such a structure into a DATE. VarUdateFromDate unpacks a DATE into a UDATE structure, which VarDateFromUdate takes from a UDATE structure and packs it into a DATE. The UDATE structure contains:
typedef struct {
SYSTEMTIME st;
USHORT wDayOfYear;
} UDATE;...and the SYSTEMTIME structure contains:
typedef struct _SYSTEMTIME { // st
WORD wYear;
WORD wMonth;
WORD wDayOfWeek;
WORD wDay;
WORD wHour;
WORD wMinute;
WORD wSecond;
WORD wMilliseconds;
} SYSTEMTIME;
Finally, there is a set of four functions for converting from DATE (actually, double) to and from the DOS date and time format and the SYSTEMTIME format just described. If you don't need the wDayOfYear member, you may prefer to use the SYSTEMTIME conversion functions: VariantTimeToSystemTime and SystemTimeToVariantTime.
You can do date arithmetic, such as adding or subtracting years, months, days, hours, minutes, seconds, and milliseconds to a date, by converting to a UDATE or SYSTEMTIME, changing the appropriate members of the UDATE (and/or SYSTEMTIME) structures, and then converting back to a DATE. Note that it's your responsibility to make sure you keep the members of the structure consistent and that you don't overflow them. For instance, if you modify wDay, you should also modify wDayOfWeek (and wDayOfYear) in the same manner—and you need to make sure that none of them overflow their defined values. By the same token, if you modify wMonth, wHour, wMinute, wSecond, or wMilliseconds, make sure you don't overflow them. If you do, you will likely get strange results when you call VariantTimeToSystemTime or VarDateFromUdate to convert back.
MFC has two classes that can help you deal with dates: COleDateTime and COleDateTimeSpan.
COleDateTime contains methods to construct a date object using a time you specify or the current time; convert to a SYSTEMTIME struct; get the year/month/day/hours/minute/second/day of week/day of year; set the date and time; format to a string and parse from a string; and subtract or compare two COleDateTime objects.
The result of subtracting two COleDateTime objects is a COleDateTimeSpan object, which represents elapsed time. You can also add a COleDateTimeSpan object to a COleDateTime object, giving a COleDateTime object.
The COleDateTime object supports methods for setting the time span; getting days/ hours/minutes/seconds and total days/hours/minutes/seconds; formatting; and addition and subtraction of two COleDateTimeSpan objects.
To pass an array using Automation, you construct a variant that contains (actually, points to) a safe array. A safe array is a one- or multi-dimensional array of a single data type. (However, this single data type can be a VARIANT, allowing you arrays of mixed types.) As in Visual Basic, the lower bound of the array does not have to be zero, so the safe array has to store its lower bound as well as the size.
The reason these arrays are called safe arrays is because they contain bounds information, allowing you to check the index or indices against the bounds before you access the data in the array. (The SafeArrayGetElement and SafeArrayPutElement APIs do this automatically for you.) Contrast this with C and C++ arrays, which are almost never bounds-checked and therefore are prone to hard-to-find and disastrous over- and under-indexing errors.
Finally, safe arrays allow locking (and unlocking) so you can be sure the pointer to the data you get is valid.
There is a large set of well-documented COM functions for accessing safe arrays. You should use these rather than dig through the structures and pointers directly. However, we will discuss the structure so you understand what's going on underneath the covers.
The definition of SAFEARRAY is (comments added):
typedef struct tagSAFEARRAY
{
USHORT cDims; // number of dimensions
USHORT fFeatures; // flags for allocation type, data type
ULONG cbElements; // size of a single element
ULONG cLocks; // lock counter
PVOID pvData; // pointer to actual data block
SAFEARRAYBOUND rgsabound[ 1 ]; // array of bounds structs
} SAFEARRAY;
Most of the members are fairly simple to understand. The flag word fFeatures tells whether the safe array is allocated on the stack, embedded in a structure, or statically; whether it can be resized; and whether it contains VARIANTs, BSTRs, IDispatch pointers, or IUnknown pointers.
The rgsabound array will contain one element per dimension. That means the size of the SAFEARRAY structure is not constant—it depends on the number of dimensions, as stored in cDims. (Because C and C++ don't do array bounds checking, you can access any number of elements in the rgsabound array even though it's declared as only one element.)
The SAFEARRAYBOUND structure is simple:
typedef struct tagSAFEARRAYBOUND
{
ULONG cElements;
LONG lLbound;
} SAFEARRAYBOUND;
It contains only a count of elements and the lower bound for that dimension.
There are 29 functions for accessing safe arrays, only 21 of which are currently documented. (The remaining 8 will be documented in an upcoming release.)
You'll usually create a safe array by calling SafeArrayCreate, SafeArrayCreateVector, SafeArrayCopy, SafeArrayCreateEx, or SafeArrayCreateVectorEx. The "Vector" versions create a one-dimensional array only. The "Ex" versions allow for a full range of VARIANT data types and specifying that an interface ID can be associated with the array (handy safe arrays that contain records or interface pointers).
You then access the array's dimension information and data with SafeArrayGetDim, SafeArrayGetLBound, SafeArrayGetUBound, SafeArrayGetElemsize, SafeArrayGetElement, and SafeArrayPutElement. For faster access, you can lock the array and get a pointer to the data with SafeArrayLock or SafeArrayAccessData. You can then get a pointer to any element with SafeArrayPtrOfIndex, or you can access it on your own. Once you're done accessing the data directly, be sure to unlock the array with SafeArrayUnlock or SafeArrayUnaccessData.
Note that when you access the array's data, you'll have to pass a pointer to an array of indices (or one index). That means you'll have to set up the array and modify it before you call—you can't pass the indices directly in the parameter list. Bummer.
Unless you specified no resizing when you created the array, you can change the rightmost dimension of the array with SafeArrayRedim. In other words, you can change a 20-element array to 10 or 30 elements, or change a 10 x 10 x 5 array to a 10 x 10 x 10, but you can't change a 10 x 10 x 5 array to a 10 x 7 x 5 array. COM takes care of deallocating or allocating and initializing elements as necessary.
When you're done with the array, call SafeArrayDestroy.
Several deal with the array descriptor (the SAFEARRAY structure) or the data individually: SafeArrayAllocDescriptor, SafeArrayAllocDescriptorEx, SafeArrayAllocData, SafeArrayCopyData, SafeArrayDestroyDescriptor, and SafeArrayDestroyData.
Finally, there are some additional, currently undocumented, functions that are primarily useful when dealing with arrays of UDTs (records) and IUnknown/IDispatch pointers. SafeArraySetIID and SafeArrayGetIID allow you to set and get the IID associated with the array. SafeArrayGetRecordInfo and SafeArrayGetRecordInfo allow you to set and get the IID for the IRecordInfo interface for the record type for arrays of records. And SafeArrayGetVartype returns the element type information you passed to the "Ex" versions of the creation functions when you created the array.
Again, only MFC comes through with a helper class for safe arrays: COleSafeArray. Most of the methods are very similar to the functions just described—they're even named the same (except they don't begin with "SafeArray"). They're thin wrappers for the preceding functions, so they do exactly the same things.
There is a set of methods that deal with vectors called CreateOneDim, GetOneDimSize, and ResizeOneDim. These provide a slightly easier way to deal with vectors.
Finally, COleSafeArray contains constructors and a set of operators for assignment, comparison, and writing to an archive and a debugging dump context.
It's very common for complicated Automation objects to expose subobjects called collections. A collection is a container for a group of some other objects. For instance, an invoice object might contain a collection of Item objects called Items. By convention, the name of an Automation collection is the plural form of the type of the object contained in the collection. So, a collection that contains Page objects would be called Pages.
Note that the collection is a separate Automation object from any of the items contained in the collection, so it has a separate automation interface that does the things that collections need to do, primarily to access items. Do not confuse these collections with the collections available in the MFC and STL C++ libraries. The C++ collections also hold objects, but they hold C++ objects rather than COM objects, have different interfaces, and can't be directly accessed from Automation clients. In other words: same name, same basic idea, different everything else.
The collection does very little except allow you to access the data. (A collection might have Add and Remove methods as well.) The simplest standard way to access the data is to expose a property called Count and a method called Item. Count returns a long with the number of elements in the collection. Item takes a long as a parameter and returns the item at that index. With these, Visual Basic code such as the following becomes possible:
REM Documents is a collection
for i = 1 to Documents.Count
Documents.Item(i).Visible = false
next i
Assuming the Document interface supports a property called Visible, this loop would hide all of the documents in the collection.
That's all well and good, but many collections cannot be indexed efficiently. To deal with those collections, Visual Basic provides the for … each loop. This starts at the beginning of a collection and does one iteration of the loop for each element in the collection. Visual Basic code for this might look like this:
for each doc in Documents
doc.Visible = false
next i
In addition to this being simpler, it can be considerably more efficient. But what happens underneath?
Well, behind the scenes, Visual Basic uses an enumerator to access the collection. This enumerator is yet another COM object that functions somewhat like an index that starts at zero and can be incremented. Each enumerator object represents a position in the collection, just as the integer variables i, j, and k can represent different indices into an array.
Collections that are compatible with for … each must have a method called _NewEnum that has the dispid DISPID_NEWENUM. Note that the leading underscore in the name _NewEnum indicates that the method should be hidden from object browsers.
As its name implies, you must write _NewEnum so it returns an IEnumVARIANT pointer to a new enumerator object. Just as you can have more than one index into an array, you can have more than one enumerator for a given collection.
Your client then accesses the collection through the enumerator's IEnumVARIANT interface. The most important method is Next, which gets one or more elements from the collection and advances the enumerator to the element after the last one retrieved. There are several other methods (Clone, Reset, and Skip) that you must implement, but they're not as commonly used as Next.
The for … each loop just shown, then, would require Visual Basic to do the following internally:
To implement the enumerator, you'd implement the four methods in IEnumVARIANT. In order to do so, your iterator will have to store enough data to get to the current object—perhaps a pointer to an element in the object, or perhaps a pointer to the collection and some kind of index. Whatever data format you choose is fine, as long as you implement IEnumVARIANT correctly. However, you must create a new enumerator object each time _NewEnum is called, so you can't implement IEnumVARIANT in the same object that holds your collection—if you did, you'd have at most one enumerator for the collection.
Note that because your enumerator is created by your main collection object when you call the _NewEnum method, you won't be creating the enumerator objects by calling CoCreateInstance. So, enumerator objects need no class factories and don't need to implement IClassFactory (although they must, of course, implement IUnknown).
Aside from the definitions of enumerator interfaces (IEnum...), there is no help from COM in implementing or using enumerators.
There are no helpers in MFC or the Visual C++ COM support classes to assist in using or implementing collections, but ATL provides a few poorly documented template classes that help you implement an enumeration. Because they're not really documented (and they're far from trivial), Dr. GUI doesn't want to go into them here. But because ATL is provided in source code, you may want to look at them: The most interesting class template names are CComEnum and _Copy. But beware: Reading template code isn't always easy!
These classes are well-documented in the new ATL Internals book mentioned earlier—so if you don't want to hack through the template code, get a copy of ATL Internals and read about 'em there.
It's not all that common to need extended error information from an Automation method, but COM gives you a way to communicate it if needed. You might recall from the initial Automation article, or from the IDispatch::Invoke documentation in the Platform SDK, that one of the parameters passed to Invoke is a pointer to an EXCEPINFO structure. This structure is used to receive extended error information, which includes an error code, strings containing the source and description of the error, and a Help file name and context ID for more information. To return extended error information, your implementation of IDispatch::Invoke would fill in this structure and return DISP_E_EXCEPTION as its HRESULT.
That's all well and good if you actually implement IDispatch::Invoke yourself. But most folks don't do that—they write a dual interface instead and have COM call it using the information in the type library. Because you're not writing the Invoke method, you don't have an opportunity to set the members of the structure. (But you can return E_FAIL or another error code as your HRESULT.) The "pass and return a global structure" scheme can also run into problems in multithreaded programs. Worse yet, if you call through the vtable side of the dual interface, there's no way to get at the extended error information—because it's passed as a parameter to Invoke, it's only available if you call through the dispatch interface.
Clearly another solution was needed, so COM provided it. Better yet, it's backward- compatible with the old method, so there's no reason to use the old method at all.
The new method is that COM defines and can create for you an error object with two interfaces: IErrorInfo and ICreateErrorInfo. ICreateErrorInfo comprises a set of Set... functions for setting the error information. IErrorInfo comprises a corresponding set of Get... functions for reading the previously-set information.
If you need to pass extended error information to your client, you create one of these error objects by calling the COM API CreateErrorInfo. It will return a pointer to the ICreateErrorInfo interface of the error object. You then fill in the fields by calling the ICreateErrorInfo methods.
Next, you have to tell COM to use this error object by calling SetErrorInfo. However, SetErrorInfo takes an IErrorInfo pointer, not an ICreateErrorInfo pointer, so you'll have to call QueryInterface to get the proper pointer. Be sure to release both of the interfaces when you're done with them. SetErrorInfo calls AddRef so the error object can be passed back.
Here's code for creating an error object:
ICreateErrorInfo *pcerrinfo;
IErrorInfo *perrinfo;
HRESULT hr;
hr = CreateErrorInfo(&pcerrinfo);
// set fields here by calling ICreateErrorInfo methods on pcerrinfo
pcerrinfo->SetHelpContext(dwhelpcontext); // and so forth
hr = pcerrinfo->
QueryInterface(IID_IErrorInfo, (LPVOID FAR*) &perrinfo);
if (SUCCEEDED(hr))
{
SetErrorInfo(0, perrinfo);
perrinfo->Release();
}
pcerrinfo->Release();
// then, eventually...
return E_FAIL; // E_FAIL or other appropriate failure code
But what if your object is called the old way, via IDispatch::Invoke? If you use COM's standard dispatch implementation, COM will automatically take care of moving the data from the error object into the EXCEPINFO structure passed by the client.
In order for clients to know that your object can return extended error information, your object will have to implement ISupportErrorInfo. ISupportErrorInfo has but a single method, InterfaceSupportsErrorInfo, which takes an IID of the interface to check. A simple implementation would look like this:
STDMETHODIMP InterfaceSupportsErrorInfo(REFIID riid)
{
return (riid == m_iid) ? S_OK : S_FALSE;
}
So we know how, in the object, to create and set the error object and how to inform the client that extended error information is available. But what do we do when we're calling a method that might return extended error information?
The first step is to check the HRESULT from the method call. If you're using IDispatch::Invoke, errors will be indicated by an HRESULT containing DISP_E_EXCEPTION. If you're calling via the vtable, you'll get whatever error code the method returned—typically E_FAIL. You should check this with the FAILED macro, as in the following code.
If you called the method via IDispatch::Invoke, the rest is easy: Assuming you passed a pointer to an EXCEPINFO structure, look at the members of the structure to determine what the error was and how to handle it.
If you called the method via a vtable call, life is a little more complicated. First, you should examine the HRESULT from the method call to decide whether you can handle the error or not. If you can't, just return the same HRESULT to the method that you called.
If you think you can handle the error, do a QI on the object to see if it supports ISupportErrorInfo. If it does, call InterfaceSupportsErrorInfo to make sure the error object will be valid.
If it is, retrieve a pointer to the error object by calling GetErrorInfo, which gives you an IErrorInfo pointer to the error object. Use the IErrorInfo methods to find information on the error, and handle it.
Calling GetErrorInfo clears the error information for your thread, so be sure to call it only if you think you can handle the error.
Code for the vtable call case might look like this:
HRESULT hrMethod = pVtableInterface->MethodCall();
if (FAILED(hrMethod)) {
if (bCanHandle(hrMethod)) { // true if I can handle this error
ISupportErrorInfo *pSupport;
HRESULT hr =
pVtableInterface->QueryInterface(IID_ISupportErrorInfo,
&pSupport);
if (SUCCEEDED(hr)) {
hr = pSupport->InterfaceSupportsErrorInfo(IID_IYours);
if (hr == S_OK) { // can't use SUCCEEDED here! S_FALSE succeeds!
IErrorInfo *pErrorInfo;
hr = GetErrorInfo(0, &pErrorInfo);
if (SUCCEEDED(hr)) {
// FINALLY can call methods on pErrorInfo!
// ...and handle the error!
pErrorInfo->Release(); // don't forget to release!
}
}
pSupport->Release();
}
}
return hrMethod; // couldn't handle
}
// no error—continue
If you think that's an awful lot of code for one measly method call, Dr. GUI agrees. You can encapsulate the process of getting the IErrorInfo pointer into a function that you can reuse elsewhere, at least. Or, better yet, use one of the following…
MFC provides help for passing back extended error information in the form of the class COleDispatchException and the global API AfxThrowOleDispatchException. Basically, to pass extended error information to the client you just create and initialize a COleDispatchException object and pass it to AfxThrowOleDispatchException.
If your MFC application is calling an Automation object via a class derived from COleDispatchDriver, a COleDispatchException (or COleException) will be thrown if the object returns an error. You can catch these with a try/catch block—much easier than the nested if statements just discussed.
ATL doesn't provide any helpers for passing or receiving error information, but it does provide an implementation of ISupportErrorInfo. If you want to implement ISupportErrorInfo, just check Support ISupportErrorInfo on the Attributes tab of the ATL Object Wizard Properties page when you're creating the object. Checking this adds ISupportErrorInfo to your inheritance list, adds a fairly sophisticated implementation of InterfaceSupportsErrorInfo to your class (that you can edit later), and adds an appropriate entry to the COM_MAP. There is also an ISupportErrorInfoImpl template class you can use if you're only returning error information on a single interface.
The compiler COM support classes for extended error information are actually quite good—and very similar to MFC. The _com_error class encapsulates the error information. To throw an error, create an error information object as just described and pass it, along with the HRESULT, to _com_raise_error.
If a COM method you call though a smart pointer (using the _com_ptr_t smart pointer class, usually generated via #import) returns an error, the helper function throws a _com_error exception. It's a simple matter in your catch block to query the _com_error object to get the extended error information and handle the error—much simpler than the preceding code! Note that you can use the compiler's COM support classes in any program, including ATL programs.
Dr. GUI knows full well that you won't know whether you really know what we've talked about until you try it—so give it a shot!
This time, we talked way more about COM data types than you ever wanted to know. Dr. GUI knows it's more than he was planning on writing originally!
Next time, we'll start delving into the mysteries of events and the COM model for events, including connection points.