According to the definition of encapsulation, a client simply does not care about the internal implementation of a component or its constituent objects. For all the client knows, the component itself might be built out of any number of other components, which in turn might themselves be built out of components. Reusability is therefore the exclusive concern of a component implementer. Reusability in OLE is about the implementation of objects with the desired interfaces on a binary level, where source code is not available.
The two reusability mechanisms in OLE are called containment and aggregation, and they are literally the means to reuse some other component at run time rather than inheriting implementation at compile time. (This latter method is totally valid when you are compiling your own source code but not for binary OLE components that are reusable only at run time.)8
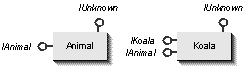
Let's say we want to implement a Koala object with the IAnimal and IKoala interfaces (the separate interfaces described above). We know that our target systems will have a basic implementation of an Animal object, with only IAnimal, that we want to use in our implementation of Koala. The two objects are illustrated below, with an IUnknown interface extending out the top explicitly to show its presence. How this IUnknown is implemented and how the other interfaces implement their IUnknown members will be part of our discussion.
In reusability relationships, the component/object being used is called the inner object, whereas the component/object doing the reusing is called the outer object. The outer object conceptually contains the inner object and is a client of that inner object.
Containment is by far the simplest and most frequently used method of reuse in OLE that requires no special reusability support on behalf of the object being reused. In containment, the outer object uses the inner object exactly as any other client would use the inner object. It is a simple client-object relationship, and the inner object does not know that its immediate client is an object itself.
The simplest case of this occurs when a component with multiple objects simply instantiates an object outside of itself that it incorporates into the component as a whole. When the component needs that object, it instantiates the object the same way any client would.
A more interesting case occurs when the outer object wants to reuse the implementation of the inner object's interfaces in order to help implement its own interfaces. In our example, the Koala object implements both its IAnimal and its IKoala interface. When the Koala object is created, it internally creates an instance (however that's done) of the Animal class and queries for its IAnimal interface. Inside the Koala object's implementation of IAnimal, it makes calls to the Animal class's IAnimal implementation. The Koala object's implementation might do nothing more than this, or it might embellish the calls in any way it wants. The Koala object is simply using the services of the Animal class, as would any other client. This overall relationship is shown in Figure 2-4. The Koala object's client, of course, has no idea that Animal is being used internally, as Animal is entirely encapsulated within Koala.
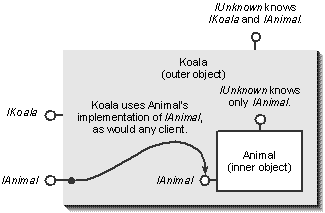
Figure 2-4.
The containment relationship between the inner object and the outer object.
Containment, as mentioned earlier, is the most frequently used means of object reuse. There are circumstances, however, in which you would like to completely reuse another object's implementation of one or more interfaces without modification and without the hassle of having to code a bunch of functions that do nothing more than delegate to another interface pointer. In our example, let's say that Koala wants to completely reuse Animal's implementation of IAnimal without modification. In essence, Koala would like to expose Animal's interface directly, as if it came from Koala itself, as shown in Figure 2-5 on the following page.
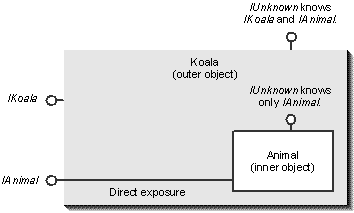
Figure 2-5.
A possible relationship between the inner object and the outer object.
To do this, Koala would create an instance of Animal during initialization, the same as it would in containment. Koala would query for Animal's IAnimal pointer, and when Koala itself was asked in QueryInterface for a pointer to IAnimal, it would simply return Animal's pointer. Right?
Here's the problem. Clients of the Koala object expect reflexive and tran-sitive behavior from both IKoala::QueryInterface and IAnimal::QueryInterface. They also expect that AddRef and Release calls through both interfaces control Koala's lifetime. However, although IKoala::QueryInterface(IID_IAnimal) will return Animal's IAnimal, a subsequent IAnimal::QueryInterface(IID_IKoala) will fail, breaking the QueryInterface properties. Why? Because the implementation of this function, as well as AddRef and Release, resides in Animal when called through this IAnimal pointer, and the Animal class has absolutely no idea about the outer Koala object!
Somehow Animal must implement the correct behavior of Koala's IUnknown functions so that QueryInterface works and the reference count affects Koala as a whole. To accomplish this, Koala must pass a pointer to its own IUnknown to Animal at creation time, which is simple because Koala will exist before Animal does (top-down creation) and will readily have its own IUnknown pointer to pass. If an object such as Animal supports aggregation, it must provide a creation function that accepts this pointer, which is called the outer unknown or the controlling unknown. As we'll see in Chapter 5, both the custom component creation function, CoCreateInstance, and the IClassFactory interface (which we saw in Chapter 1) have arguments for this purpose. Other OLE API functions that create objects have such arguments as well.
So when Animal is created, it will be given this outer unknown pointer; if it receives a NULL pointer, it knows that aggregation is not in use. If it receives a non-NULL pointer, it must delegate all IUnknown calls from its own interfaces to this outer unknown. Therefore, any client's calls to the AddRef, Release, and QueryInterface functions of IAnimal are simply delegated to this Koala object's IUnknown, which of course provides the correct behavior of this interface for the Koala object. This relationship is shown in Figure 2-6.
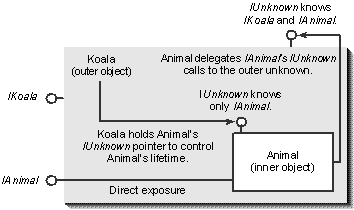
Figure 2-6.
The aggregation relationship between the inner object and the outer object. The outer object provides the inner object with the outer unknown so that the inner object can delegate calls to that outer unknown. This provides the correct IUnknown behavior for the outer object through the inner object's own interfaces.
There is a small complication that affects the implementation of the inner object in this relationship: somehow the outer object must still be able to individually control the inner object's lifetime. For this reason, and in light of other matters regarding this technique, there are several additional rules for the aggregation mechanism:

The second to last rule in this list is specified to simplify the management of reference counts in objects aggregated across process boundaries. It exists because a QueryInterface on the inner object will call the outer unknown's AddRef, which could not be released until the outer object was destroying itself. But that destruction cannot happen, of course, because the outer Release will never see a zero reference count. Therefore, the rule initially fixes the outer object's reference count without affecting the lifetime of the inner object's interface (which is what's important for remote objects). The cleanup part of the rule fixes the outer object's count so that a Release call to the inner object will not cause reentrant destruction, which the artificial reference count also protects.
The last rule avoids problems when a client asks for a newer version of an interface that the inner object supports but the outer object supports only the old version of the interface from which the new one is derived. Without this rule, the client would talk directly to the inner object's newer interface and bypass the outer object altogether. If the outer object is aware of the new interface and wants to reuse it from the inner object, it will explicitly delegate QueryInterface for that case.
The point is that when implementing a particular version of an object, you want to decide ahead of time what interfaces that version will support. You should choose which interfaces your object will implement and which it will obtain from an existing object through aggregation. If the inner object is updated without your knowledge, it will suddenly change the prototype of your object in ways you did not logically expectthis can lead to problems.
In some cases, however, the outer object is intentionally trying to embellish the inner object with an interface that is otherwise unknown to the inner object. For example, a client might want to create a generic object wrapper with a custom interface that aggregates every object used from the client. This wrapper could provide a custom interface known only to that one client, thereby centralizing container-specific methods and properties within that wrapper object. This technique is used in OLE Control containers, for example, where a container creates an extended control that wraps the real control via aggregation. It is a highly useful technique but must be used with care.
The aggregation contract thus allows the outer object to reuse complete interfaces from an inner object, but it also requires the inner object to be written specifically to support aggregation. There is an error code for creation functions, CLASS_E_NOAGGREGATION, that an inner object returns to tell an outer object that aggregation is not supported.
A final note is that aggregation works to arbitrarily deep levels. The Animal object in use here might itself be an aggregate that obtained its IAnimal from some other component, and that component was an aggregate using yet another aggregate, and so on. Since object creation is top-down, Koala creates Animal, which in turn creates any object within it. If Animal is given an outer unknown pointer during creation, it must pass that pointer down to whatever object it creates, which in turn passes the pointer on down the chain. In this way, every object in every level of an arbitrarily deep aggregation will always have a pointer to the outermost unknown. No matter whose interface pointers the outer object ultimately exposes, all delegated IUnknown calls go directly to the outermost IUnknown implementation. In other words, the calls do not have to percolate up the entire aggregation chain: it's simply one quick step up to the outer unknown.
8 Everyone at Microsoft who worked on marketing OLE in the early days myself included with the first edition of this book placed far far too much emphasis on aggregation which is used much less often and is merely a convenience for certain containment cases. |