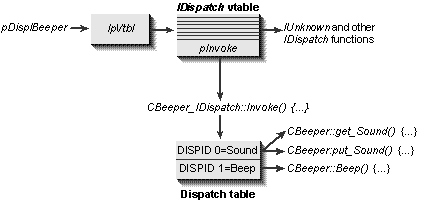
The magic mapping function that invokes a method or a property according to a dispID is IDispatch::Invoke. When a controller has a pointer to a dispinterface, it really has a pointer to an implementation of IDispatch that responds to a set of dispIDs specific to that implementation. If a controller has two IDispatch pointers for two different objects, for example, dispID 0 may mean something completely different to each object. So while a controller will have compiled code to call IDispatch::Invoke, the actual method or property invoked is not determined until run time. This is the nature of late binding.
IDispatch::Invoke is the workhorse of OLE Automation, and besides a dispID it takes a number of other arguments to pass on to the object's implementation, as shown in Figure 14-3 on the following page. The other member functions of IDispatch exist to assist the controller in determining the dispIDs and types for methods and properties through type information.
Figure 14-3.
The accessing of methods and properties in a dispinterface is routed through IDispatch::Invoke. This calls the object's internal functions as necessary based on the dispID passed from the controller.
Because a controller is usually a programming environment, it is generally a script or program running in that controller that determines which dispID gets passed to which object's IDispatch. The controller, however, needs only one piece of code that knows how to call IDispatch members polymorphically, letting its interpreter or processing engine provide the appropriate arguments for IDispatch members on the basis of the running script. This processing will generally involve all four of the specific IDispatch members:
interface IDispatch : IUnknown
{
HRESULT GetTypeInfoCount(unsigned int *pctinfo);
HRESULT GetTypeInfo(unsigned int itinfo, LCID lcid
ITypeInfo **pptinfo);
HRESULT GetIDsOfNames(REFIID riid, OLECHAR **rgszNames
, unsigned int cNames, LCID lcid, DISPID *rgdispid);
HRESULT Invoke(DISPID dispID, REFIID riid, LCID lcid
, unsigned short wFlags, DISPPARAMS *pDispParams
, VARIANT *pVarResult, EXCEPINFO *pExcepInfo
, unsigned int *puArgErr);
};
Member Function | Description |
Invoke | Given a dispID and any other necessary parameters, calls a method or accesses a property in this dispinterface |
GetIDsOfNames | Converts text names of properties and methods (including arguments) to their corresponding dispIDs |
GetTypeInfoCount | Determines whether there is type information available for this dispinterface, returning 0 (unavailable) or 1 (available) |
GetTypeInfo | Retrieves the type information for this dispinterface if GetTypeInfoCount returned successfully |
You can implement the IDispatch interface in various ways (as we'll see later in this chapter), including the use of OLE API functions such as DispInvoke, DispGetIDsOfNames, and CreateStdDispatch. Regardless of the implementation technique, Invoke always requires the same arguments, which include the following:
Given the dispID of a dispinterface member and the necessary information about property types and method arguments, a controller can access everything in the dispinterface. But how does a controller obtain the dispID and the arguments in the first place?
Using our Beeper object as an example, consider a little fragment of code in a Basic-oriented automation controller (DispTest or Visual Basic). This code sets Beeper's Sound property and instructs the object to play that sound by calling the Beep method. (Obviously, this is not the only way to access an automation object through a controller language; Basic is just an example.)
Beeper.Sound = 32 '32=MB_ICONHAND, a system sound
Beeper.Beep
The controller has to turn both of these pieces of code into IDispatch::Invoke calls with the right dispID and other parameters. To convert the names "Sound" and "Beep" to their dispIDs, the controller can pass those names to IDispatch::GetIDsOfNames. Passing "Sound," for example, to our Beeper's implementation of this function would return a dispID of 0. Passing "Beep" would return a dispID of 1.
You must also give the right type of data to the Beeper object to assign to the Sound property. The value 32 (defined for C/C++ programmers, at least, as MB_ICONHAND in WINDOWS.H) is an integer. The Basic interpreter must perform type checking to ensure that the type of the argument is compatible with the Sound property. This is accomplished either at run time (pass the arguments to Invoke and see whether the object rejects it) or through the object's type information as obtained through IDispatch::GetTypeInfo (if IDispatch::GetTypeInfoCount returns a 1). A well-behaved controller wants to use type information when it is available. If it is not, IDispatch::Invoke will perform type coercion and type checking itself, returning type mismatch errors as necessary.
The same dispID passed to different objects may result in a completely different method or property invocation. In general, specific dispinterfaces themselves are not polymorphic, although Microsoft has standardized a few dispIDs with defined semantics, as described in Table 14-1. We'll see a number of these throughout the rest of this chapter. Each of these standard dispIDs has a zero or negative value, and Microsoft reserves all negative dispID values (those with the high bit set) for future use.
dispID (Value)* | Value and Description |
DISPID_VALUE (0) | The default member for the dispinterfacethat is, the property or method invoked if the object name is specified by itself without a property or a method in a controller script. |
DISPID_UNKNOWN (-1) | Value returned by IDispatch::GetIDsOfNames to indicate that a member or parameter name was not found. |
DISPID_PROPERTYPUT (-3) | Indicates the parameter that receives the value of an assignment in a prop-erty put. |
DISPID_NEWENUM (-4) | The _NewEnum method of a collection. (See "Collections" later in this chapter.) |
DISPID_EVALUATE (-5) | A method named Evaluate that a controller implicitly invokes when it encounters arguments in square brackets. For example, the following two lines are equivalent: |
DISPID_CONSTRUCTOR (-6) | The method that acts as the object's constructor. Reserves for future use. |
DISPID_DESTRUCTOR (-7) | The method that acts as the object's destructor. Reserves for future use. |
* The dispID -2 ran off and became a gypsy. You might see it at a rest stop along some European motorway someday. Actually, -2 is called ID_DEFAULTINST and is used specifically in ITypeComp::Bind to identify an implicitly created or default variable. The value was assigned from the dispID pool at a time when member IDs of arguments and interface members were not clearly distinct from dispIDs of methods and properties in a dispinterface.
Table 14-1.
Standard dispID values and their meanings.
Two special data types are specified as part of OLE Automation, although like much else, they are usable outside an IDispatch implementation. These types are the BSTR and the Safe Array.
A BSTR is a Basic STRing in which the string is stored as a DWORD count of characters followed by the characters themselves, as illustrated below. In OLE Automation, these strings are NULL-terminated, so a pointer to the beginning of the character array is the same as a C string pointer; in C or C++, a BSTR type always points to the characters, but the character count always precedes it in memory.

OLE provides a special set of API functions to allocate, manage, and free BSTR types: SysAllocString, SysAllocStringLen, SysFreeString, SysReAllocString, SysReAllocStringLen, and SysStringLen. You can easily guess what each function does. (The OLE Programmer's Reference holds the complete documentation for these functions.)
An important reason why Automation employs BSTR types for strings is that Automation was designed and implemented for the most part in the group at Microsoft that also produces Visual Basic, and Basic stores strings in a BSTR format. In addition, a BSTR is faster to copy across a process boundary because the length of the string is already known. As we'll see later in this chapter, it is quite simple to deal with BSTR variables. In fact, it can often be more convenient than working with C strings.
A Safe Array is an array of other types. The reason they are safe is that the array itself is a data structure that contains boundary information for the array as well as the actual reference to the data. Here's how the SAFEARRAY type is defined in the Automation header files:
typedef struct tagSAFEARRAY
{
USHORT cDims; //Count of array dimensions
USHORT fFeatures; //Flags describing array
USHORT cbElements; //Size of each element
USHORT cLocks; //Number of locks on array
HANDLE handle; //HGLOBAL to actual array
void * pvData; //Pointer to data valid when cLocks > 0
SAFEARRAYBOUND rgsabound[]; //One bound for each dimension
} SAFEARRAY;
typedef struct tagSAFEARRAYBOUND
{
ULONG cElements; //Number of elements in dimension
long LBound; //Lower bound of dimension
} SAFEARRAYBOUND
The various flags, symbols prefixed with FADF_, identify the array elements as BSTRs, IDispatch or IUnknown pointers, or VARIANT structures (see the following section). There are two flags that also indicate whether the array is allocated on the stack or allocated statically, which means that the array does not need to be freed explicitly when the SAFEARRAY structure is freed.
As with BSTRs, OLE provides a number of API functions, 19 in all, for creating, accessing, and releasing safe arrays: SafeArrayAccessData, SafeArrayAllocData, SafeArrayAllocDescriptor, SafeArrayCopy, SafeArrayCreate, SafeArrayDestroy, SafeArrayDestroyData, SafeArrayDestroyDescriptor, SafeArrayGetDim, SafeArrayGetElement, SafeArrayGetElemsize, SafeArrayGetLBound, SafeArrayGetUBound, SafeArrayLock, SafeArrayPtrOfIndex, SafeArrayPutElement, SafeArrayRedim, SafeArrayUnaccessData, and SafeArrayUnlock. Again, see the OLE Programmer's Reference for more information about all of these functions.
The VARIANT is a structure that can contain any kind of data. With IDispatch::Invoke, a VARIANT carries the return value from a property get or a method call; a VARIANTARG carries the arguments to a property put or a method call. Both structures have exactly the same format, shown in the following, and you'll often see the two types used interchangeably:
typedef struct tagVARIANT VARIANT;
typedef struct tagVARIANT VARIANTARG;
typedef struct tagVARIANT
{
VARTYPE vt; //Identifies the type
unsigned short wReserved1;
unsigned short wReserved2;
unsigned short wReserved3;
union
{
//by-value fields
short iVal;
long lVal;
float fltVal;
double dblVal;
VARIANT_BOOL bool;
SCODE scode;
CY cyVal; //Currency
DATE date;
BSTR bstrVal;
IUnknown FAR * punkVal;
IDispatch FAR* pdispVal;
SAFEARRAY FAR* parray;
//by-reference fields
short FAR* piVal;
long FAR* plVal;
float FAR* pfltVal;
double FAR* pdblVal;
VARIANT_BOOL FAR* pbool;
SCODE FAR* pscode;
CY FAR* pcyVal;
DATE FAR* pdate;
BSTR FAR* pbstrVal;
IUnknown FAR* FAR* ppunkVal;
IDispatch FAR* FAR* ppdispVal;
VARIANT FAR* pvarVal;
void FAR* byref;
};
};
You can see that while this structure is actually quite small16 bytesit can hold just about any type of value or pointer within it. We've already seen the BSTR and SAFEARRAY types, which leaves the CY (currency) and DATE structures as the only newcomers. These two are very simple:
typedef struct tagCY
{
unsigned long Lo;
long Hi;
} CY;
typedef double DATE;
On systems that use big-endian microprocessorslike the Macintoshthe ordering of the CY structure's fields is reversed. In any case, the currency type is an 8-byte fixed-point number, and the DATE type is a double that contains the number of days since December 30, 1899, in the whole part and the time in the fractional part. The time is expressed as a fraction of a day.2
The VARTYPE field, an unsigned short, at the beginning of the structure identifies the actual type that is held in the structure itselfthat is, which one of the many fields of the union has meaning. The value in vt is drawn from the enumeration VARENUM, which defines not only the possible VARIANT types but also the types that are used in type information and persistent property sets, which we'll see in a Chapter 16. (See Table 16-1 on page 784.) The following is the comment for VARENUM, taken from the OLE header files, that describes the enumeration (the actual values of the symbols are unimportant):
/*
* VARENUM usage key,
*
* * [V] - may appear in a VARIANT
* * [T] - may appear in a TYPEDESC
* * [P] - may appear in an OLE property set
* * [S] - may appear in a Safe Array
*
*
* VT_EMPTY [V] [P] nothing
* VT_NULL [V] SQL-style Null
* VT_I2 [V][T][P][S] 2-byte signed int
* VT_I4 [V][T][P][S] 4-byte signed int
* VT_R4 [V][T][P][S] 4-byte real
* VT_R8 [V][T][P][S] 8-byte real
* VT_CY [V][T][P][S] currency
* VT_DATE [V][T][P][S] date
* VT_BSTR [V][T][P][S] binary string
* VT_DISPATCH [V][T] [S] IDispatch FAR*
* VT_ERROR [V][T] [S] SCODE
* VT_BOOL [V][T][P][S] True=-1, False=0
* VT_VARIANT [V][T][P][S] VARIANT FAR*
* VT_UNKNOWN [V][T] [S] IUnknown FAR*
* VT_I1 [T] signed char
* VT_UI1 [V][T] [S] unsigned char
* VT_UI2 [T] unsigned short
* VT_UI4 [T] unsigned short * VT_I8 [T][P] signed 64-bit int
* VT_UI8 [T] unsigned 64-bit int
* VT_INT [T] signed machine int
* VT_UINT [T] unsigned machine int
* VT_VOID [T] C-style void
* VT_HRESULT [T]
* VT_PTR [T] pointer type
* VT_SAFEARRAY [T] (use VT_ARRAY in VARIANT)
* VT_CARRAY [T] C-style array
* VT_USERDEFINED [T] user-defined type
* VT_LPSTR [T][P] null-terminated string
* VT_LPWSTR [T][P] wide null-terminated string
* VT_FILETIME [P] FILETIME
* VT_BLOB [P] Length-prefixed bytes
* VT_STREAM [P] Name of the stream follows
* VT_STORAGE [P] Name of the storage follows
* VT_STREAMED_OBJECT [P] Stream contains an object
* VT_STORED_OBJECT [P] Storage contains an object
* VT_BLOB_OBJECT [P] Blob contains an object
* VT_CF [P] Clipboard format
* VT_CLSID [P] A Class ID
* VT_VECTOR [P] simple counted array
* VT_ARRAY [V] SAFEARRAY*
* VT_BYREF [V]
*/

You'll notice that the types you can specify in a VARIANT are mostly the generic types. The others are useful in describing type information or in describing persistent binary data such as a BLOB. The VT_BYREF flag is what differentiates a VARIANTARG from a VARIANT: only a VARIANTARG is allowed to use this flag in order to pass parameters by reference. In that case, all of the by-reference fields in the VARIANTARG structure have no meaning in the VARIANT itself. For all intents and purposes, however, the two structures are otherwise the same.
OLE provides a few functions to initialize and otherwise manage both structures. These generally simplify your work with these structures and reduce the need for you to access fields of the structures directly.
In addition, OLE provides a host of functions to deal with the conversion between types, the topic of the next section. There are also a great number of macros that eliminate the need to refer to individual fields in a VARIANT or a VARIANTARG. V_I2(var) performs the equivalent of var->iVal, and V_BSTRREF(var) is the same as var->pbstrVal. The macro V_VT extracts the vt field, V_ISBYREF checks whether vt has the VT_BYREF flag, and V_ISARRAY and V_ISVECTOR do the same check for VT_ARRAY and VT_VECTOR. Using these macros isn't necessary; there is no magic here. They are provided simply to make your source code more readable if you prefer this sort of syntax.
Function | Description |
VariantClear | Clears the VARIANT[ARG] by releasing any resources within it and setting the type to VT_EMPTY. If the structure contains a BSTR or SAFEARRAY, that element is freed with SysFreeString, SafeArrayDestroyData, or SafeArrayDestroy; if the element is an IUnknown or an IDispatch pointer, this calls IUnknown::Release. It does not recurse deeper if the type is VT_VARIANT. |
VariantCopy | Copies the contents from one VARIANT[ARG] to another. The destination structure is cleared with VariantClear; BSTRs and SAFEARRAYs are copied in their entirety, and AddRef is called through any IUnknown or IDispatch pointers. |
VariantCopyInd | Indirect version of VariantCopy that copies a by-reference VARIANTARG to a by-value VARIANT. The contents of the destination VARIANT are cleared with VariantClear. |
VariantInit | Initializes the fields of a VARIANT[ARG], for example a field declared as a stack variable. It sets vt to VT_EMPTY and the wReserved* fields to 0, but it does not change the union value. |
Inside an implementation of IDispatch::Invoke, an object will generally find it necessary to coerce into the necessary type the variables passed to a method or put in a property. The reason is that a controller, because of its language structure (especially for weakly typed languages such as Basic), may pass arguments or properties in a type other than that specified in an object's type information. Certainly a sophisticated controller can provide some type checking before calling Invoke at run time, but this is not required. Ultimately it is the object's responsibility to ensure that the information it receives is converted to the type that it needs.
Now Invoke will receive in its DISPPARAMS argument an array of VARIANTARG structures. These structures hold every argument to a method or the value to put in a property. Where Invoke might expect a BSTR it gets a long, or a BOOL where it needs a double, or even an IDispatch pointer where it really wants CY or DATE. Type coercion is the process of converting one type to a compatible type. This might include conversion of strings to numbers and vice versa, and it may even involve getting or setting a property through another object's IDispatch.
To assist with this process, OLE comes with two basic functions, VariantChangeType and VariantChangeTypeEx. (The Ex brand is sensitive to localization concerns such as date and currency formats.) You can throw a VARIANT to one of these functions and see whether OLE can convince it to become a different type (inside another VARIANT). Of course, OLE is not so heavy-handed that it will try to force a square peg through a round hole, so some types simply cannot be converted to others. How, for example, does one convert an array of IUnknown pointers to a currency value? If I were dealing with my bank account, I'd be happy for it to max out the currency value, but I don't think my bank would appreciate that. In the interests of honesty, OLE doesn't convert incompatible types; it returns the programmer's nemesis, a type mismatch error. Rats.
In any case, OLE can coerce many types into many others. Each conversion actually has its own function with a name like Var<type>From<type>, as in VarR4FromI2, which is used internally inside VariantChangeType[Ex] through one massive double switch statement. There are conversion functions for every combination of short, long, float, double, BOOL, CY, DATE, BSTR, and IDispatch *, as is accurately documented in the OLE Programmer's Reference. These conversions are not necessarily trivial either; converting a BOOL to a BSTR, for example, gives you the string "True" or "False" as appropriate; converting dates and currency values with BSTRs does all the formatting and parsing according to the user's international settings.
What is most interesting is that you can often convert between these types and an IDispatch pointer. What the IDispatch pointer really represents is another object whose DISPID_VALUE property is the value to convert. The conversion functions that work with IDispatch pointersnamed Var<type>FromDispcall that interface's Invoke with a property get on DISPID_VALUE and then attempt to coerce any simple value to another type. "Simple" means that if Invoke returns another IDispatch pointer, for example, and we're trying to coerce into a long, the final converted value will be the numeric value of that pointer, losing any sense of it being a pointer to anything. If we were converting to a short, we'd end up with only the lower 16 bits of that pointer. In other words, this final conversion does not recurse into VariantChangeTypeit just extracts the value to return out of the VARIANT that comes back from Invoke. This simple conversion will always work, but it may result in a useless value.
As a further assistance to implementation of IDispatch::Invoke, OLE offers the function DispGetParam, which retrieves a value from a VARIANTARG buried within Invoke's DISPPARAMS argument. To use this function, you pass the DISPPARAMS pointer, the position of the argument, and the type you want to retrieve. DispGetParam will extract the appropriate argument and try to coerce it into the type you want by using VariantChangeType. If this function fails, it gives you back the error information to return to the controller that originally called Invoke.
I'm sure you'd like to know of a way to avoid messing with VARIANTs and performing all this tedious muck with type coercion, with or without DispGetParam. You might figure that because all the argument and property types you support through an implementation of IDispatch::Invoke are described in an object's type information, OLE can handle all this coercion automatically. In fact, you are absolutely correct. OLE provides automatic type coercion and checking directly through the ITypeInfo interface, specifically the function ITypeInfo::Invoke. We'll see how to use this feature later in this chapter, when we look at the various techniques for implementing IDispatch.
Shhhh! Wanna hear a secret? You can use all the VARIANT functions as nothing more than a rich type conversion API. Nowhere in the Win32 API will you find functions to parse a date or time or currency string into an actual numeric value using the current international settings or to convert a value to a string. Nowhere else will you find functions to conveniently convert an integer to a "True" or "False" string. All the VARIANT manipulation functions are essentially a stand-alone library of useful functions that require only a prior call to CoInitialize as the BSTR and SAFEARRAY types use COM's memory allocation service.
Now that we know about the VARIANT[ARG] and about coercing one type of VARIANT[ARG] into another, we can understand the DISPPARAMS structure that is passed as pDispParams to IDispatch::Invoke. This structure contains all the arguments for a method call or a property put and has the following structure:
typedef struct tagDISPPARAMS
{
VARIANTARG FAR* rgvarg; //Array of arguments
DISPID FAR* rgdispidNamedArgs; //dispIDs of named arguments
unsigned int cArgs; //Number of total arguments
unsigned int cNamedArgs; //Number of named arguments
} DISPPARAMS;
In the simplest cases, the rgvarg array has the VARIANTARG structures that make up the arguments to the method or property. For a property put, there is only one argument; for a method invocation, there may be zero or more arguments. Every VARIANTARG element in rgvarg is considered read-only unless it has VT_BYREF set in its vt field. In that case, the argument can be used as an out-parameter when necessary. Simple enough.
But of course, there are some tricks involved with DISPPARAMS that introduce more complications. First of all, any strings or other pointers to possibly allocated resources that are passed as arguments in this structure are always the caller's responsibility. In other words, Invoke should never free arguments itself. If Invoke wants to hold a copy of a by-reference value, for example a BSTR or an IUnknown or IDispatch pointer, it must copy the data or call AddRef through the pointer, respectively.
The order of the arguments inside the rgvarg array is from last to firstthat is, a right to left stacking order. Say, for example, that you invoke a method with three arguments as follows:
Object.Method(arg1, arg2, arg3)
You would then have the value 3 in pDispParams->cArgs, with arg1 at rgvarg[2], arg2 at rgvarg[1], and arg3 at rgvarg[0].
Next, a method can support optional arguments. Such arguments are specifically marked in a dispinterface's type information as optional, but they must always be sent to Invoke inside the DISPPARAMS structure. To check whether an optional argument was sent or not, an implementation of Invoke checks whether the VARIANTARG has type VT_ERROR and the contents of DISP_E_PARAMNOTFOUND in the scode field. If so, the controller didn't provide the argument; otherwise, the argument is there and the object has to coerce it to the proper type. A method always gets its full complement of arguments, but some of them may not be available. Also, some older controllers might set the type of a nonexistent optional argument to VT_EMPTY instead of VT_ERROR.
If any argument cannot be coerced into a usable type, Invoke must return DISP_E_TYPEMISMATCH. Of course, it is highly useful for a controller, and ultimately the programmer or user of that controller, to know which argument was mismatched. To provide that information, the automation object must store the rgvarg index or the bad argument in the location pointed to by the Invoke parameter puArgErr.
Both the required and optional arguments mentioned so far are called positional argumentsthey always appear in the same position in the rgvarg array. IDispatch::Invoke, more appropriately an automation object, can also support named arguments that appear first in the rgvarg array. In other words, they occupy the low positions in the array where the positional arguments come at the end. The pDispParams->cNamedArgs field tells you whether you have any named arguments. If this value is 0, everything is positional.
What are named arguments? They are arguments that can be placed anywhere in a method's argument list and are identified by a name that has meaning to the method itself. For example, consider a method named FindRockBand for a music database. The method has one positional argument containing the number of members in the band and three named arguments, named LeadGuitar, BassGuitar, and Percussion, which are strings possessing the last names of the band members. (To complete this type of query function, we might add optional parameters such as Vocals and RhythmGuitar, which would be noted with the count argument being higher than 3, but we don't need to complicate matters here.) This method, which might return a long identifier to the database record, would be declared in the object's type information as follows:
LONG FindRockBand(int cMembers, BSTR LeadGuitar, BSTR BassGuitar
, BSTR Percussion)
MKTYPLIB will assign each argument its own member identifier in the order declared, starting with 0. So cMembers would be ID 0, LeadGuitar ID 1, BassGuitar ID 2, and Percussion ID 3. Do not confuse these member ID values with the dispID values of methods and properties: the identifiers simply mark the argument.
With named arguments, you can invoke FindRockBand in a controller such as Visual Basic as follows:
id=Database.FindRockBand(3, LeadGuitar="Lifeson", BassGuitar="Lee"
, Percussion="Peart")
Because named arguments are used, you can employ any other permutation as an exact equivalent, as in the following:
id=Database.FindRockBand(3, Percussion="Peart", LeadGuitar="Lifeson"
, BassGuitar="Lee")
or
id=Database.FindRockBand(3, BassGuitar="Lee", Percussion="Peart"
, LeadGuitar="Lifeson")
Inside Invoke, the DISPPARAMS structure for any of these calls will have cArgs=4 (the total count) and cNamedArgs=3. The first (and in this case the only) positional argument in rgvarg would be rgvarg[3]that is, at the end of the array. The three named arguments will occupy rgvarg[3-cNamedArgs+0], rgvarg[3-cNamedArgs+1], and rgvarg[3-cNamedArgs+2]. I'm using 3 here to denote the last element in the array, subtracting cNamedArgs to get the beginning of the named arguments, and then adding 0, 1, and 2 to get to the first, second, and third named arguments.
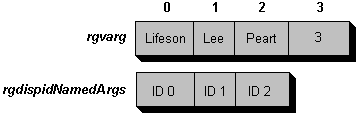
Keep in mind, that you cannot depend at all on the ordering of the named arguments inside rgvarg. Generally the controller will just throw them in DISPPARAMS in the order they appear in the controller code, but to an automation object the order is not an order at all, only a random sequence. How you actually determine which element in rgvarg contains which named argument is the purpose of the final field of DISPPARAMS, rgdispidNamedArgs. This is an array of member identifiers, those dispIDs assigned to arguments based on their order in the method declaration. This is how an implementation of Invoke identifies the arguments because only the IDs, not the names themselves, are passed in DISPPARAMS. The rgdispidNamedArgs[0] field will always contain the ID of the argument in rgvarg[0], rgdispidNamedArgs[1] will contain the ID of the argument in rgvarg[1], and so on. So if the controller executes the following code:
id=Database.FindRockBand(3, LeadGuitar="Lifeson", BassGuitar="Lee"
, Percussion="Peart")
the rgvarg and rgdispidNamesArgs arrays will appear as follows (lower memory to the left):
If the controller executes the following:
id=Database.FindRockBand(3, Percussion="Peart", LeadGuitar="Lifeson"
, BassGuitar="Lee")
the rgvarg and rgdispidNamesArgs arrays will instead appear as this:
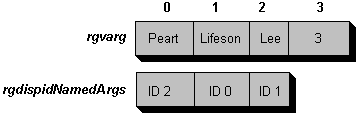
It is up to the automation object supporting named arguments to match elements in rgvarg with the proper argument value. The object itself can reject any attempt to pass named arguments by failing Invoke with DISP_E_NONAMEDARGS if cNamedArgs is nonzero.
There is one special case with named arguments. Any property put operation is considered to involve a named argument when the argument is the property itself. Inside Invoke, you'll see cArgs=1, cNamedArgs=1, and rgdispidNamedArgs[0] with DISPID_PROPERTYPUT, and rgvarg[0] with the VARIANT containing the new property value. A controller is responsible for generating this specific DISPPARAMS structure, and an automation object considers it an error to see a property put with anything different, returning DISP_E_PARAMNOTOPTIONAL to tell the controller so. This is required because some controllers, as a result of their language structure, cannot differentiate between a property get or put and a method call. This means the wFlags parameter to Invoke will indicate both operations. The object must use this special named argument case to determine what is actually going on.
Whereas the DISPPARAMS argument to Invoke handles all the arguments to a method or the new value for a property put, the VARIANT named pVarResult handles the return value of a method or the return value of a property get. This pVarResult exists because Invoke returns an HRESULT so it can describe errors; only if Invoke returns NOERROR does the result in pVarResult have meaning.
If the result is an allocated type such as a BSTR or an interface pointer, the object is responsible for allocating the resource or calling AddRef, whereas the controller must free the resource or call Release. You can see from this that combined with the rule that the object never frees arguments passed in DISPPARAMS, an automation object never frees any resources it shares with its controller, with the exception of in/out-parameters involved in a method invocation. As I mentioned earlier, arguments in DISPPARAMS are read-only unless they are passed by reference, and then they are read/write only if the method knows that they are, in fact, in/out-parameters themselves. With such in/out-parameters, the object must be sure to free whatever arguments were passed by calling VariantClear on those arguments, before overwriting them and returning from Invoke.
Because Invoke can return only a limited number of SCODEs, how can it give information to a controller about why an operation failed above and beyond a simple error code? How can you get Invoke to say, "This property set failed because the allowable range for this value is 1 through 5," instead of returning DISP_E_OVERFLOW or some terribly undetailed information such as E_FAIL? The answer is that the object can raise an OLE Automation exception.
In OLE Automation, an exception is really a form of rich and detailed error reporting. It's not the same thing as structured exception handling in C++, Win32, and so on. Although the controller can do what it wants with automation exceptionshaving chains of exception handlers, for exampleraising an exception from an automation object simply involves filling the fields of the EXCEPINFO structure passed to Invoke in the pExcepInfo argument and having Invoke return DISP_E_EXCEPTION. Controllers that don't handle exceptions will pass a NULL in pExcepInfo.
The EXCEPINFO itself is defined as follows:
typedef struct tagEXCEPINFO
{
unsigned short wCode; //Object exception code, excludes scode
unsigned short wReserved;
BSTR bstrSource; //ProgID of object
BSTR bstrDescription; //Text description of error
BSTR bstrHelpFile; //Full path to a help file
unsigned long dwHelpContext; //Help context ID to display
void FAR* pvReserved;
//An object function for delayed filling of structure
HRESULT (STDAPICALLTYPE *pfnDeferredFillIn)
(struct tagEXCEPINFO FAR*);
SCODE scode; //scode for error, excludes wCode
} EXCEPINFO, FAR* LPEXCEPINFO;
When an object raises an exception, it stores an error code inside either wCode or scode but not in both. A 0 in wCode means that the scode has the error. After storing the code, the object can choose either to fill in the rest of the fields as necessary except for pfnDeferredFillIn or to set everything to NULL and store a function pointer in pfnDeferredFillIn. If the controller sees an exception with a pointer in this field, it calls (*pfnDeferredFillIn)(&excepInfo) when it wants the information. This allows the object to defer all of the potential costs of loading strings for the source and description fields until the controller actually wants it. The structure passed to this deferred filling function will have the wCode or scode originally stored within Invoke so that the filling function knows which exception was raised.3
The other four fields in the structurehowever the controller obtains themare used to display information about the exception to the user of that controller. The bstrSource string should contain the object's VersionIndependentProgID. If the field is non-NULL, the controller can then extract the value of this VersionIndependentProgID (a readable name) from the registry and display a message box with a message in the form "Error <code> in <readable name> : <bstrDescription>" provided bstrDescription is also valid. For example, the Beeper object we used before had a Sound property that is played through MessageBeep when the object's Beep method is invoked. Because this sound has to be meaningful to MessageBeep, it can have only the value MB_OK (0), MB_ICONHAND (16), MB_ICONQUESTION (32), MB_ICONEXCLAMATION (48), or MB_ICONASTERISK (64). If a controller attempts to give this object a value outside this range, the object raises an exception because there is no SCODE sufficiently rich to describe the actual error. The object will store its error code in wCode or scode, its VersionIndependentProgID of "Beeper.Object" in bstrSource, and the error description in bstrDescription. The controller will then display this information as shown in Figure 15-2 on page 755.
This message box will have an OK button by default, but if the object provides a non-NULL bstrHelpFile, the message box will also have a Help button. Pressing the Help button tells the controller to launch WinHelp, specifying the help file and context ID in the EXCEPINFO structure:
WinHelp(NULL, pExcepInfo->bstrHelpFile, HELP_CONTEXT
, pExcepInfo->dwHelpContext);
The result is that the user can get even more detailed information on the exception, as shown in Figure 14-4.
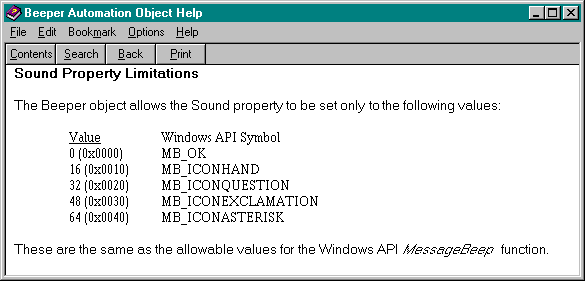
Figure 14-4.
Exception information displayed in a help file.
It is the controller's responsibility to call SysFreeString for all the BSTR fields of the EXCEPINFO structure.
As we explore various means of implementing IDispatch later in this chapter, we'll employ another error-reporting mechanism involving error objects. These are created with the API function CreateErrorInfo and the interface ICreateErrorInfo, set with the function SetErrorInfo, and accessed using GetErrorInfo and IErrorInfo. An object identifies its support for error objects by implementing ISupportErrorInfo. These functions and interfaces are basically a thread-safe mechanism for returning the same exception information to a controller that also ties into parts of OLE Automation itself.
In Chapter 3, we saw how a locale identifier serves as the basis for performing case mapping, string comparison, sorting, and conversion of date, time, and currency formats to and from strings. In addition, a locale identifier can form the basis for localized method, property, and event names for an automation object. For example, a user in Germany who would like to use our Beeper object would not necessarily understand what the Sound property really was or what action the Beep method would perform. In German, the object is better described as a Pieper (pronounced "peeper")with the property Ton (as in tone) and the method Piep. Instead of writing an automation script in English, a German user could write it in German:
Pieper.Ton = 32
Pieper.Piep
The lcid argument passed to the IDispatch members GetTypeInfo, GetIDsOfNames, and Invoke makes it possible for an IDispatch implementation to know which language is in use. It can use that information to return localized type information, convert localized member names to dispIDs, and invoke those members with the understanding that certain parameters, especially strings and time, date, or currency values, will be expressed in the language or format appropriate for that locale. In addition, it makes sense that any exception raised inside Invoke will provide information that is also sensitive to lcida user would not appreciate seeing an otherwise informative error message and help file show up in the wrong language!
You can support different locales from within an IDispatch implementation in a number of ways. We'll see some later in this chapter. The most flexible method of implementation is to have an automation object accept and support any locale from within a single version of the code. Then the object can be installed on any machine in the world and be immediately useful to any user.
This is, of course, the ideal case for an automation object, but it takes the most work. You can also choose an alternative approach that would not take as much time to implement and localize but that would still be flexible. The next-best technique, which is easily extensible to an arbitrary number of languages, is to support two languagesone localized, one neutral. (I'll illustrate this technique later with code.) An object like this allows a user to write a script in his or her own language while allowing the object to work with scripts written in the neutral language. This comes into play most often for automation objects that are useful to corporate or other developers. From what I've heard, programmers want to program in English, and this is understandable because all the system APIs are in English and all the lower-level programming tools and languages express their capabilities in English. As far as I know, the neutral language of choice is basic English (without a specific sublanguage).
Two-language support becomes very important with automation objects that can be accessed by multiple controllers at once. This means that the same instance of the object, one that is tied to a running application, for example, can be driven by two different controllers in two languages at the same time. One call to Invoke might use German, the next English, the next German, and so on. This would happen in the case in which the object was being driven both from an end-user script written in his or her local lang-uage and from a corporate developer's script written in English (the neutral language).
In my mind, the two-language approach is the best option because it's relatively easy to implement as well as to localize, and it addresses almost all of the important localization scenarios. Even so, there are two other techniques for handling locales; they are somewhat less flexible, but they might be the right choice in certain circumstances. In the first, an object can choose to support only a single locale, whatever the default is for the user or the machine, and return an error (DISP_E_UNKNOWNLCID) if a controller attempts to use it through any other language. This is fairly easy to implement, but it means that a script written for one language cannot be used on a machine that is operating with a different language, which, of course, shows why supporting a neutral language is advantageous. But if the automation object you're implementing is designed much more for an end user and not for corporate developers, this may be a reasonable choice.
On the other hand, you can implement an automation object that is not targeted to end users at all but targeted only to other developers (or perhaps advanced users). In that case, you can write an object that supports only one language, usually English, but also accepts any locale. This means you ignore any and all localization concerns, which is perfectly acceptable for objects that don't deal with time, date, or currency formats or with text that is displayed in a user interface or that would otherwise need translation. An automation object that performs 3-D graphics rendering, for example, is a good candidate for such an implementation. The more an implementation is potentially useful to an end user, the more important it becomes to support localization.
2 There are two functions for converting an OLE Automation DATE type to the same informa-tion stored in an MS-DOScompatible format (that is, the format used in the file system): DosDateTimeToVariantDateTime and VariantTimeToDosDateTime. |
3 DispTest and Visual Basic 3.0 do not support deferred exception filling, but later versions of Visual Basic and other controllers do. If you want to make a flexible object that fills the exception structure now for potential Visual Basic 3 customers, it is very useful to still write a deferred filling function and call it from within your Invoke to fill a structure. When customers shift to a newer controller, you can, if you want to support deferred filling, replace that call from inside Invoke and simply store the function pointer in pExcepInfo->pfnDeferredFillIn. |