To understand how OLE Documents as a whole works, we need to understand why compound documents exist and what sorts of requirements they have. It should be fairly obvious that much of the information generated today uses formats from a variety of sources. In this book, for example, the text was written using a word processor and the graphics were created with a drawing tool. An e-mail message might include graphics as well as other sorts of attachments, such as sound recordings or video clips. A presentation might include not only word processor text but also charts and tables from a spreadsheet, graphics, sounds, video, and all sorts of other interesting content. These collections of stuffdocument, e-mail message, or presentationare all things we call compound documents because they contain pieces of arbitrary information. We use the term document in a generic way to refer to any such collection (as opposed to a word processor document specifically).
Compound documents are not in any way new. Five-thousand-year-old pictures and hieroglyphics on the walls of Egyptian tombs are examples of a compound document, as are the illuminated manuscripts of the Middle Ages. Even in the twentieth century, compound documents have been created in much the same way as pyramid carvings and manuscriptsthat is, manually. Before the computer age, one typically created a compound document by carefully typing or printing the text on a page, leaving spaces for various other forms of data, primarily graphics, photographs, or other clippings. A layout artist then literally cut those other elements to the right size and pasted them into the document with glue. These actions gave us the clipboard metaphor and its ubiquitous Copy, Cut, and Paste commands.
Using the computer's clipboard by itselfwithout OLE Documentsyou can create very good compound documents, benefiting from automatic layout and easy positioning of elements within the document. To insert pieces of content in the document, you can run the application to create the content you want, create the data, select it, and then copy it to the clipboard and paste it into the document. The result is that in the document you have a rectangle that displays some meaningful datatext, graphics, and so on. Each rectangle is an object as far as the user is concerned. You insert content as many times as necessary to assemble all the data you want in that document. This is simple enough, but consider a few complications, some of which are especially difficult for novice users:
The user has to know what applications are available to create content in the first place. The user must manually locate those applications and run them.
Pasting data from the clipboard can result in a loss of information. Pasting a metafile drawing as a bitmap, for example, loses the individuality of lines, curves, and other graphical operations. Output quality can suffer accordingly.
The data pasted into the document does not retain any information about the program used to create it in the first place. To edit that data, the user must locate the correct application, run it, and then attempt to copy data from the document back into the editing application.
Copying data back is not always possible, and if information was lost in the paste, it might not be possible to edit the data as it was originally created.
To get around this last problem, the user must remember to save individual files containing the original source data. To edit the data, the user must remember not only the editing application but also the source file. Searching for files is a tedious process.
All in all, these complications make the process of creating and managing compound documents fragile and time-consuming. This was why Microsoft created OLE in the first place. OLE 1, which was then called Object Linking and Embedding, was specifically designed to solve the problems described earlier. OLE 2 was originally intended to improve the performance of various OLE 1 bottlenecks and to add the capability for in-place activation. In the process, Microsoft created the component architecture that we've been exploring in this book, which we now simply call OLE. OLE Documents is specifically the subset of OLE technologies that deals with creating and managing compound documents.
Here's how OLE Documents solves the problems outlined in the previous list, tremendously easing the burden on end users:
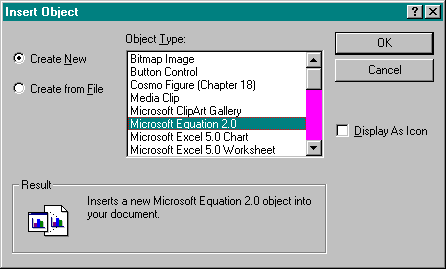
Through a standard Insert Object dialog box, shown in Figure 17-1 on page 818, users can choose from a list the type of content they want to insert into the document as an embedded or a linked content object. The list is full of the names of registered content objectsthose marked with a key named Insertableeach of which maps to a CLSID. This CLSID is then used to launch a server that knows how to edit and manipulate that content type. This means that the user never has to search for applications manually. As the user edits the data, changes are reflected in the container. When the user closes the editor, the data is automatically saved in the compound document; no copy and paste is necessary.
If the user has an editing application already running, copying and pasting data from it (if it supports OLE Documents) results in an embedded or a linked content object in the container. (The Paste Special dialog box can be used to choose alternative formats.) The object maintains its CLSID and all of its native data (or a moniker that names the location of that data) so that information is not lost. The container shows the result of this paste as a graphical representation of the object's data. The representation is cached along with the object's native data in the compound document itself. If the object provides an in-process handler (or server), it can control output quality directly.
When a user wants to edit or manipulate the data, the user tells the container to execute one of the object's verbs, specific actions such as Edit and Play. The container tells the object to activate itself using the verb, and in response, the object runs the editing code again, initializing the user interface with the native data stored previously (not the graphical representation). The user is automatically brought back to the original editing facilities with the original data. The user doesn't need to manually launch an application or attempt to manually copy data back to it.
Because the object knows where it came from (its CLSID) and maintains its original data, editing is always possible if the object's server is available on the machine. Even when the server is not available, other servers might be capable of emulating that CLSID so that they can work with the data. In the absence of all editing facilities, the cached graphical representations ensure that the user can always view and print the data in the document.
Embedded objects always maintain their own native data directly in the compound document itself. Linked objects maintain their own moniker to their original source file. In neither case is the user required to remember where source files are located, if they are necessary at all.
Figure 17-1.
The standard Insert Object dialog box as provided by the OLE UI Library.
To make this work, both the container and the object (and its server) must support their respective pieces of the OLE Documents protocol, much of which involves other OLE technologies. The basic process of launching a server given a CLSID and then setting up communication with it was covered in Chapters 5 and 6. As we saw in Chapter 7, the ability to share a file between a container and components is handled through a compound file, in which each embedded or linked object supports storage-based persistence through IPersistStorage (as we saw in Chapter 8). In particular, linked objects maintain a reference to their source information using a moniker, and the binding procedures we explored in Chapter 9 apply perfectly to the needs of OLE Documents. A content object supports IDataObject, IViewObject2, IOleCache2, and, optionally, IOleCacheControl (Chapters 10 and 11) to render data formats, draw presentations directly in the container, and cache presentations. Given additional clipboard formats, the OLE Clipboard and OLE Drag and Drop can be used to copy an embedded or a linked object from a source to a container's document, where the object's data is exchanged using an IStorage medium instead of global memory for more efficiency. To all of these interfaces, we add IOleObject and IRunnableObject, which fill out the capabilities of all content objects.
An object with these interfaces, as illustrated in Figure 17-2, is exactly what a container sees in its own process as a basic embedded content object. (Additional interfaces appear for linked objects and for objects that support in-place activation.) We are now ready to see how these interfaces make OLE Documents work.
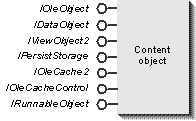
Figure 17-2.
How a basic embedded content object appears to a container.