You describe workloads to Response Probe, in part, by choosing a mean and standard deviation for several parameters that characterize threads in the workload. You choose a mean and standard deviation for
The theory behind Response Probe is that real workloads are normally distributed; that is, the time spent thinking, accessing memory, reading and writing to files, finding a record in a file, computing, and other such tasks, are distributed on a standard bell-shaped curve. Alternatively, if the workloads were invariant or random, they wouldn't simulate real use of real computers.
Note
The actions of threads and processes are normally distributed, so they are not, technically, fixed. However, in repeated trials the same inputs will produce the same results.
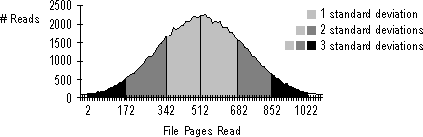
In a bell-shaped curve, most activity is concentrated around the mean, decreasing with distance from the mean, and with the least frequency at both extremes. The standard deviation determines how much activity is concentrated near the mean and how often more distant values occur. By definition, 2/3 of all activity occurs within one standard deviation on either side of the mean, 95% is within two standard deviations, and 99% is within three standard deviations of the mean.
Usually, the midpoint is chosen as the mean, and one-third of the total (1/6 on either side of the mean) is chosen as the standard deviation.
For example, in a 1024-page file, if page 512 is the mean and 170 pages is the standard deviation, then:
If, instead, the mean was 512 and the standard deviation was 256 (1/2 of 512), then 2/3 of reads will be from pages 256768, and the remaining third would be equally distributed throughout the rest of the file. At the extremes, if the standard deviation is 0, page 512 is the only one read, and if the mean is equal to the standard deviation, reading is random, so all pages are equally likely to be read.