
|
|
||
|
|
|||
Localized versions of Office 95 and earlier were based on character encoding standards that varied from one script to another. When users working in one language version of Office exchanged documents with a user who worked in another language version of Office, text was often garbled because of the difference between character encodings.
Therefore, users opening Office 2000 documents in a localized version of Office 95 or earlier might encounter some limitations in the languages that they can display. However, Office 2000 is based on an international character encoding standard — Unicode — that allows users upgrading to Office 2000 to more easily share documents across languages.
Multilingual documents can contain text in languages that require different scripts. A single script can be used to represent many languages.
For example, the Latin or Roman script has character shapes — glyphs — for the 26 letters (both uppercase and lowercase) of the English alphabet, as well as accented (extended) characters used to represent sounds in other Western European languages.
The Latin script has glyphs to represent all of the characters in most European languages and a few others. Other European languages, such as Greek or Russian, have characters for which there are no glyphs in the Latin script; these languages have their own scripts.
Some Asian languages use ideographic scripts that have glyphs based on Chinese characters. Other languages, such as Thai and Arabic, use complex scripts, which have glyphs that are composed of several smaller glyphs or glyphs that must be shaped differently depending on adjacent characters.
A common way to store text is to represent each character by using a single byte. The value of each byte is a numeric index — or code point — in a table of characters; a code point corresponds to a character in the code page. For example, a byte whose code point is the decimal value 65 might represent a capital letter a.
This table of characters is called a code page. A code page contains a maximum of 256 bytes; because each character in the code page is represented by a single byte, a code page can contain as many as 256 characters. One code page with its limit of 256 characters cannot accommodate all languages because some languages use far more than 256 characters. Therefore, different scripts use separate code pages. There is one code page for Greek, another for Cyrillic, and so on.
Single-byte code pages cannot accommodate Asian languages, which commonly use more than 5,000 Chinese-based characters. Double-byte code pages were developed to support these languages.
One drawback of the code page system is that the character represented by a particular code point depends on the specific code page on which the code point resides. If you don’t know which code page a code point is from, you cannot determine how to interpret the code point.
For example, unless you know which code page it comes from, the code point 230 might be the Greek lowercase zeta (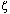 ), the Cyrillic lowercase zhe (
), the Cyrillic lowercase zhe (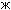 ), or the Western European diphthong (
), or the Western European diphthong (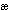 ). All three characters have the same code point (230), but the code point is from three different code pages (1253, 1251, and 1252, respectively). Users exchanging documents between these languages are likely to see incorrect characters.
). All three characters have the same code point (230), but the code point is from three different code pages (1253, 1251, and 1252, respectively). Users exchanging documents between these languages are likely to see incorrect characters.
Unicode was developed to create a universal character set that can accommodate all known scripts. Unicode uses a unique, two-byte encoding for every character; so in contrast to code pages, every character has its own unique code point. For example, the Unicode code point of lowercase zeta () is the hexadecimal value 03B6, lowercase zhe () is 0436, and the diphthong () is 00E6.
Unicode 2.0 defines code points for approximately 40,000 characters. More definitions are being added in Unicode 2.1 and Unicode 3.0. Built-in expansion mechanisms in Unicode allow for more than one million characters to be defined, which is more than sufficient for all known scripts.
Currently in the Microsoft Windows operating systems, the two systems of storing text — code pages and Unicode — coexist. However, Unicode-based systems are replacing code page – based systems. For example, Microsoft Windows NT®, Office 97 and later, Microsoft Internet Explorer version 4.0 and later, and Microsoft SQL Server™ version 7.0 are all based on Unicode.
Topic Contents | Previous | Next | Top Friday, March 5, 1999 © 1999 Microsoft Corporation. All rights reserved. Terms of use. | ||
|
License
|