Calculates the statistics for a line by using the "least squares" method to calculate a straight line that best fits your data, and returns an array that describes the line. Because this function returns an array of values, it must be entered as an array formula.
The equation for the line is:
y = mx + b or y = m1x1 + m2x2 + ... + b (if there are multiple ranges of x-values)
where the dependent y-value is a function of the independent x-values. The m-values are coefficients corresponding to each x-value, and b is a constant value. Note that y, x, and m can be vectors. The array that LINEST returns is {mn,mn-1, ...,m1,b}. LINEST can also return additional regression statistics.
Syntax
LINEST(known_y's,known_x's,const,stats)
Known_y's is the set of y-values you already know in the relationship y = mx + b.
Known_x's is an optional set of x-values that you may already know in the relationship y = mx + b.
Const is a logical value specifying whether to force the constant b to equal 0.
Stats is a logical value specifying whether to return additional regression statistics.
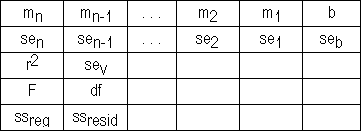
The additional regression statistics are as follows.
|
Statistic |
Description |
|
se1,se2, ...,sen |
The standard error values for the coefficients m1,m2, ...,mn. |
|
Seb |
The standard error value for the constant b (seb = #N/A when const is FALSE). |
|
r2 |
The coefficient of determination. Compares estimated and actual y-values, and ranges in value from 0 to 1. If it is 1, there is a perfect correlation in the sample there is no difference between the estimated y-value and the actual y-value. At the other extreme, if the coefficient of determination is 0, the regression equation is not helpful in predicting a y-value. For information about how r2 is calculated, see "Remarks" later in this topic. |
|
sey |
The standard error for the y estimate. |
|
F |
The F statistic, or the F-observed value. Use the F statistic to determine whether the observed relationship between the dependent and independent variables occurs by chance. |
|
df |
The degrees of freedom. Use the degrees of freedom to help you find F-critical values in a statistical table. Compare the values you find in the table to the F statistic returned by LINEST to determine a confidence level for the model. |
|
ssreg |
The regression sum of squares. |
|
ssresid |
The residual sum of squares. |
The following illustration shows the order in which the additional regression statistics are returned.
Remarks
Slope (m):
To find the slope of a line, often written as m, take two points on the line, (x1,y1) and (x2,y2); the slope is equal to (y2 - y1)/(x2 - x1).
Y-intercept (b):
The y-intercept of a line, often written as b, is the value of y at the point where the line crosses the y-axis.
The equation of a straight line is y = mx + b. Once you know the values of m and b, you can calculate any point on the line by plugging the y- or x-value into that equation. You can also use the TREND function. For more information, see TREND.
Slope:
INDEX(LINEST(known_y's,known_x's),1)
Y-intercept:
INDEX(LINEST(known_y's,known_x's),2)
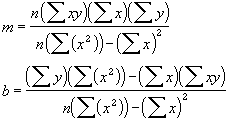
Example 1 Slope and Y-Intercept
LINEST({1,9,5,7},{0,4,2,3}) equals {2,1}, the slope = 2 and y-intercept = 1
Example 2 Simple Linear Regression
Suppose a small business has sales of $3,100, $4,500, $4,400, $5,400, $7,500, and $8,100 during the first six months of the fiscal year. Assuming that the values are entered in the range B2:B7, respectively, you can use the following simple linear regression model to estimate sales for the ninth month.
SUM(LINEST(B2:B7)*{9,1}) equals SUM({1000,2000}*{9,1}) equals $11,000
In general, SUM({m,b}*{x,1}) equals mx + b, the estimated y-value for a given x-value. You can also use the TREND function.
Example 3 Multiple Linear Regression
Suppose a commercial developer is considering purchasing a group of small office buildings in an established business district.
The developer can use multiple linear regression analysis to estimate the value of an office building in a given area based on the following variables.
|
Variable |
Refers to the |
|
y |
Assessed value of the office building |
|
x1 |
Floor space in square feet |
|
x2 |
Number of offices |
|
x3 |
Number of entrances |
|
x4 |
Age of the office building in years |
This example assumes that a straight-line relationship exists between each independent variable (x1, x2, x3, and x4) and the dependent variable (y), the value of office buildings in the area.
The developer randomly chooses a sample of 11 office buildings from a possible 1,500 office buildings and obtains the following data.
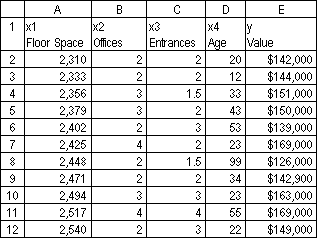
"Half an entrance" means an entrance for deliveries only. When entered as an array, the following formula:
LINEST(E2:E12,A2:D12,TRUE,TRUE)returns the following output.
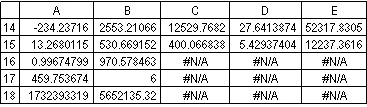
The multiple regression equation, y = m1*x1 + m2*x2 + m3*x3 + m4*x4 + b, can now be obtained using the values from row 14:
y = 27.64*x1 + 12,530*x2 + 2,553*x3+ 234.24*x4 + 52,318
The developer can now estimate the assessed value of an office building in the same area that has 2,500 square feet, three offices, and two entrances and is 25 years old, by using the following equation:
y = 27.64*2500 + 12530*3 + 2553*2 - 234.24*25 + 52318 = $158,261
You can also use the TREND function to calculate this value. For more information, see TREND.
Example 4 Using The F And R2 Statistics
In the previous example, the coefficient of determination, or r2, is 0.99675 (see cell A16 in the output for LINEST), which would indicate a strong relationship between the independent variables and the sale price. You can use the F statistic to determine whether these results, with such a high r2 value, occurred by chance.
Assume for the moment that in fact there is no relationship among the variables, but that you have drawn a rare sample of 11 office buildings that causes the statistical analysis to demonstrate a strong relationship. The term "Alpha" is used for the probability of erroneously concluding that there is a relationship.
There is a relationship among the variables if the F-observed statistic is greater than the F-critical value. The F-critical value can be obtained by referring to a table of F-critical values in many statistics textbooks. To read the table, assume a single-tailed test, use an Alpha value of 0.05, and for the degrees of freedom (abbreviated in most tables as v1 and v2), use v1 = k = 4 and v2 = n - (k + 1) = 11 - (4 + 1) = 6, where k is the number of variables in the regression analysis and n is the number of data points. The F-critical value is 4.53.
The F-observed value is 459.753674 (cell A17), which is substantially greater than the F-critical value of 4.53. Therefore, the regression equation is useful in predicting the assessed value of office buildings in this area.
Example 5 Calculating The T-Statistics
Another hypothesis test will determine whether each slope coefficient is useful in estimating the assessed value of an office building in example 3. For example, to test the age coefficient for statistical significance, divide -234.24 (age slope coefficient) by 13.268 (the estimated standard error of age coefficients in cell A15). The following is the t-observed value:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
If you consult a table in a statistics manual, you will find that t-critical, single tail, with 6 degrees of freedom and Alpha = 0.05 is 1.94. Because the absolute value of t, 17.7, is greater than 1.94, age is an important variable when estimating the assessed value of an office building. Each of the other independent variables can be tested for statistical significance in a similar manner. The following are the t-observed values for each of the independent variables.
|
Variable |
t-observed value |
|
Floor space |
5.1 |
|
Number of offices |
31.3 |
|
Number of entrances |
4.8 |
|
Age |
17.7 |
These values all have an absolute value greater than 1.94; therefore, all the variables used in the regression equation are useful in predicting the assessed value of office buildings in this area.