MDAC 2.5 SDK - OLE DB Programmer's Reference
Chapter 21: OLE DB for OLAP Concepts
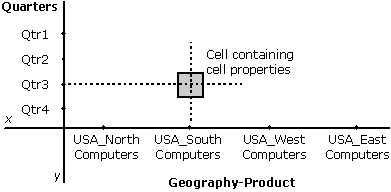
The dataset encapsulates a multidimensional result set and is the result of executing an MDX statement. A dataset consists of a set of axes. The points along an axis are called coordinates. For an axis that consists of a single dimension, these coordinates are a subset of the members of that dimension.
If an axis consists of more than one dimension, each coordinate is a compound entity that has n parts, where n is the number of dimensions oriented along that axis. Each part of the coordinate is a member from one constituent dimension.
For example, if the Geography and Products dimensions are oriented along the x-axis of a dataset, a coordinate along this axis might be (USA, Computers). In this example, the "USA" member of the Geography dimension has been combined with the "Computers" member of the Products dimension to result in the compound entity, the tuple. In this example, determining a coordinate along the x-axis requires members from each dimension oriented along it.
At the intersection of axes coordinates are cells. Each cell has multiple pieces of information associated with it. The data itself is one such piece of information. Other pieces of information include the following:
These "information pieces" are collectively called cell properties.
Postprocessing and Specifying New Datasets
After obtaining a new dataset, the consumer typically will perform several operations on it, such as pivoting, changing dimension orientation, sorting, or rotating.
OLE DB for OLAP solves this problem by employing postprocessing, in which the consumer creates a dataset object from some command specification. Once the object is created, further user operations modify the dataset object, resulting in a change to the data manifold represented by the dataset. There is no need to create a new dataset or alter the original command specification that created the dataset.
Any operation that the user wants to perform on a dataset is necessarily a subset of the operations needed to create the dataset from the cube. By considering postprocessing operators as incremental changes to the original dataset specification, all the semantics of the command specification process (which have already been defined) can be leveraged. The postprocessing approach requires first identifying the postprocessing operators as a subset of the original command operators, defining semantics for each of these operators, and so on.