So where did client/server come from? To answer this, and give you some background that will help you to understand the design principles we'll be discussing later in this chapter, we need to go back to the beginnings of computer networks.
Even the earliest computers were network based, in that the user sat at a terminal in the corner of the room, and the computer filled the other four floors of the building. In effect, the control of the machine was from a terminal—a remote keyboard, card reader, printer, or screen.
If this sounds a little far-fetched, consider the modern PC. The DOS interpreter still understands the kind of commands that were used then, for example the keyword
refers to the console—what the operating system understands as the keyboard and the screen. In a DOS Command Window, CONCOPYC:\MYFILE.TXT
produces a listing of the file's contents, and CONCOPYCON
creates a new file containing the character you type. (If you decide to try this, don't forget that you have to press Ctrl-Z to close the file and get control of the system again).NEWFILE.TXT
The advent of graphical interfaces has blurred this distinction somewhat, but in effect you're still sitting at a machine where the keyboard and screen form a 'dumb terminal', which talks to the rest of the system behind the scenes. This is a similar scenario to the first kinds of distributed computing. All you needed to do was allow the central processing unit to support several sets of screens and keyboards—or terminals—and scatter them around the building.
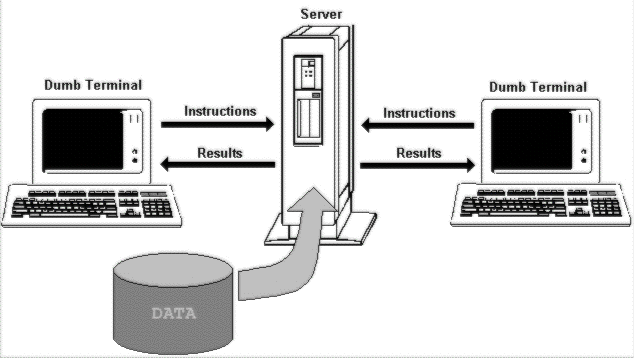
In a dumb terminal network, the server stores all the data and carries out all the processing.
This was the traditional central processing system model. 'Dumb terminals' carried no processing power of their own, other than that required to collect keystrokes and send them back to the main processing unit, and display information coming from it.
This is still a common model for modern-day computing, where a mainframe or mini computer drives the network. It stores all the data, and carries out all the processing. All the terminal sees is the results of the commands it sends—and this concept has even been extended to provide graphical user interfaces on the client terminal.
The traditional dumb terminal network is the administrator's dream come true. All of the configuration and (most important of all) the power of the system, is contained inside that air-conditioned room. As long as the physical network connections are intact, and the simple terminals aren't belching smoke, it all works. Central control means that the entire network can be managed, monitored, and maintained from one place. It also means that network traffic is minimized. All that has to travel the wires are the instructions coming from the terminals, and the results being sent back.
And if you think that the dumb terminal network is dead, then just take a look at Java. Right now there is a huge development effort going into the Java Station, the Network Computer, and even 'TV set-top box' Web terminals. All these, by and large, are terminals with limited processing power, zero configuration requirements, and no local storage.
So how does the Internet, and especially the World Wide Web, fit in? It's easy to see that the concept of a dumb terminal network almost exactly matches way in which we use the 'Net. Although the machine on our desk has huge reserves of processing power, and (in theory anyway) plenty of local storage space, all we are doing with a browser is acting as a dumb terminal.
We send a request off to the Web server, and it sends back the processed information as a static page that the browser just has to display. Up until the advent of client-side technologies like Java, ActiveX and scripting languages, the browser was literally a dumb terminal.
The physical structure of the Internet also matches this model very well. Bandwidth is at a premium, so the minimization of network traffic is a major bonus. And the remote geographical nature of the terminals makes visits by the network technician impossible.
Of course, with the arrival of the personal computer, users wanted more than just a dumb terminal on their desk. Seeing what was possible with their own 'real' computer meant that static information coming from a server, over which they had little or no control, was obviously severely limiting when the technology beckoned with ever-increasing capabilities. And soon, PCs were strung together to form local area networks. Users could share files and resources, like printers, between the machines.
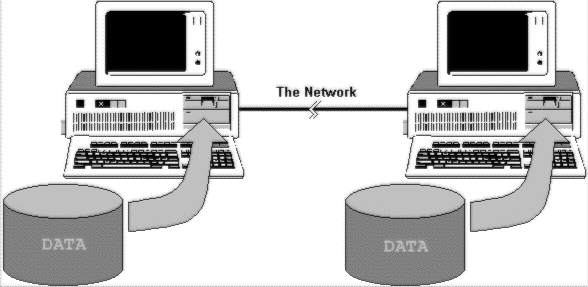
On a peer to peer network, each machine holds it's own data and carries out its own processing on that data.
This is great, except for three things. Firstly, there is no real central management, so everyone ends up using different applications, styles, and formats—documents stray from the standard corporate design, and everyone can do their own thing. Secondly, because each machine has its own local storage, files are duplicated across the network. Each user keeps their own copy of the corporate data, and so backing up—and even just getting an overall picture of the information available—becomes impossible.
And finally, the PC is a rather more complex beast than a dumb terminal. Configuration and maintenance now involve the technician rushing around the building, installing and upgrading each machine separately. Even strict management of the users, and new technologies which allow remote configuration of machines and replication of data across them, generally fail to achieve real solutions to these problems.
Linking individual PCs together, as we've just been discussing, is generally referred to a peer-to-peer networking, because everyone has equal rights on the network. And, as we've seen, one of the major problems is that data becomes duplicated across the various machines. One simple way to cure this problem is to place a single copy of each file on a nominated machine, and let every user access that copy.
Now, the junior accountant keeps the customer database on his hard disk, and remembers to back it up daily. However, the constant accesses from all the other users are going to limit the responsiveness of his machine. It could well slow to a crawl when the sales desk is busy. The solution is to dedicate one machine on the network as a central file server, provide it with oodles of disk space, and put all the files there. It becomes a lot easier to do proper backing up, and duplication of the data is prevented.
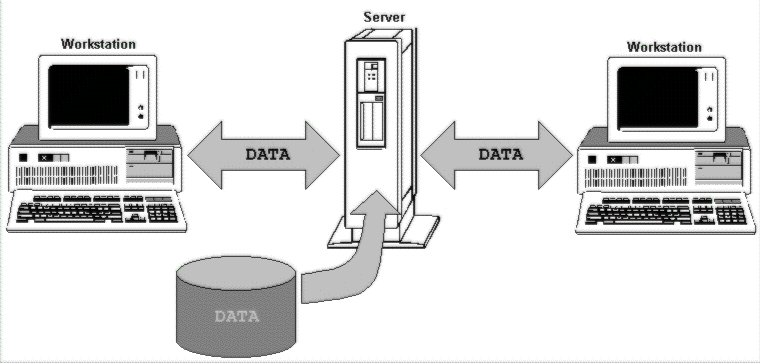
Using a central file server means that all the data has to pass across the network each time it is queried or updated.
While this network model solves the file duplication problem, and to some extent aids network management, it does little to solve the concerns of configuring and maintaining the rest of the machines on the network. It also, unfortunately, adds another problem. Every file has to travel across the network from the server to the end user, then back again to be saved. If the junior accountant needs to update the customer database, the complete file it has to be fetched from the server, processed, and saved back there again. Network bandwidth requirements go through the roof.
In recent years, technologies have been developed which were aimed solely at solving the mixture of problems we've seen so far in the various networking models. An example of this is Microsoft Access, which can work either as a stand-alone application, or in a kind of client/server mode.
When we create a new database on our hard disk, Access works as a single-user local processing application. All the data storage and manipulation is done on our machine. However, we can use Access as a 'front end' to a set of database tables, by linking them to it. These tables can then be placed on another part of the network, say the central file server. Now, everyone can have an Access front-end (and not necessarily all the same one), while working with a single set of data.
But this alone isn't client/server computing, and it does little to limit bandwidth requirements. What completes the picture is that the central server can carry it's own copy of the database engine, minus the 'front end'. Now, instead of the client machines fetching a whole table of data across the network each time, they can issue an instruction to the central database engine, which extracts the results they need from the tables and sends just that back across the network.
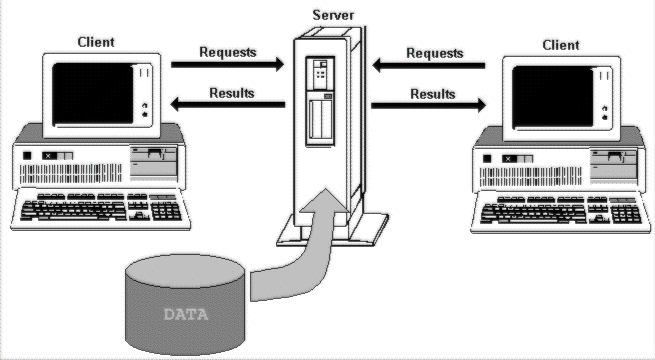
Client/server systems minimize network traffic by distributing the processing between the server and the client machines.
In Microsoft Access terms, the database engine is executing stored procedures, something we came across back in Chapters 4 and 5 when we looked at the Active Data Object. This itself is just a way of connecting to, amongst other things, different database engines.
So client/server, at least in theory, gives us the best of all the worlds. We get minimized network traffic, central data storage, and easier systems management because the 'important' processing can be done at the server end if required. The only real down side, and the one that is currently the biggest cause for concern in the corporate world, is the continued difficulties of individual client machine maintenance, upgrades, and configuration.
As you'll have already guessed from our earlier discussions of Active Server Pages, one thing it aims to achieve is to allow easy development of client/server applications on the Internet, and more particularly in the environment of the World Wide Web. In many ways, this is the only way to go, because the prospect of any real increases in the bandwidth available in the near future is unlikely. While a modern corporate network will run at 10Mbps, and even up to 100Mbps, many users are usually limited to 28.8Kbps or 56Kbps. Even an ISDN connection can only manage somewhere up to 128Kbps.
As for the client end of the network, almost without exception, the user has a modern PC with plenty of local storage space, and spare horsepower available, so the browser can afford to do more and more of the processing at its end. Even the downside of system maintenance, upgrades and configuration is less of a problem. At least, on the Internet as a whole, it's the user's problem now, and not the network administrator's. In a corporate Intranet environment this isn’t the case, but standardization on one browser does tend to make the job a great deal easier.
So, having seen some of the background to client/server development, let's move on to look at what it offers in the environment of the Web. Client/server on the Web is exciting, because it solves many problems that are making traditional client/server projects expensive, overdue, and hard to maintain. More specifically, Web-based client/server solves the problems of:
Distribution: Distribution is automatic, because new copies of the pages (the components of our application) are downloaded to the client machine whenever the local client cache says they need updating. No more walking round the building installing software, or expecting your Web site visitors to download and install it themselves.
Flexibility: The automatic distribution and installation means that applications can be updated much more easily. This is a huge benefit if the environment requires quick turn around on changes to the specifications or just bug fixes. Even 'Interface du jour' could be implemented, where different interfaces and content are deployed daily—of great interest to marketing departments when selling products.
Central Control: With the deployment of PC’s and local installations, the system administrators lost control, and help desk costs for maintaining non-standard desktops increased. Being able to control the applications at the server end is highly cost effective.