So having justified the case for client/server, we need to investigate further what this enticing new technology actually is. This is a question that has many different interpretations. The reason is that client/server has become a buzzword that every new product must contain. In its simplest form, we can use this definition:
Client/server computing is the splitting of a computing task between client and server processes.
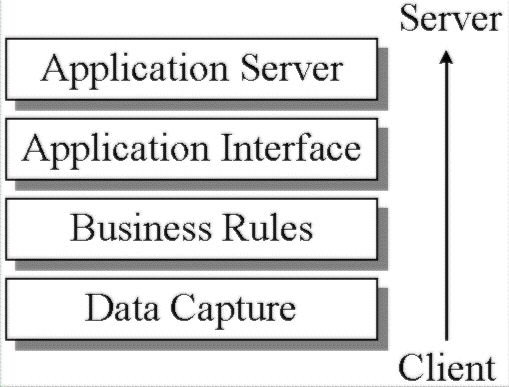
This literal definition is very vague, however, there are more concrete definitions. For example, the following diagram is more specific. It states that there are four layers to a client/server system.
These four layers are from the classical model of client/server design, and can show up in various different forms. But to be able to develop a client/server system you must be able to understand the four layers.
The first layer is called Data Capture. This means that the data is captured and converted from a human representation to a computer representation. The previous sentence could be more easily termed as punching in the data. However, using that type of definition implies that the user has something that they can actually punch—such as a keyboard. The more precise definition is better, because it sums up all possibilities. For example, in the future, input devices could use voice, gesture, or neural transmitters. Coming back to reality, current input devices may be a mouse, keyboard or virtual reality interface device. The only limit is human imagination.
The reverse of input is output, and the statement also applies in this context. Examples of output devices are monitors, printers, or tape drives. Programming operations that are acceptable in this layer would be filling or reading the contents of a list box or a combo box, and then packing the data into a pre-defined structure.
However, it's important to note that this layer is only responsible for the translation of the data from one form to another, human to computer or vice-versa. The actual contents of the data are not verified for correctness or accuracy here.
This layer is responsible for applying the Business Rules to the data captured in the first layer. It is responsible for converting the data to a business context, and adding information about the business rules. The user does not interact with the software in this layer at all, however this layer is critical because it validates the data to make sure that it is in the correct form—and is applied to the data that is both coming from or going to the server. The business rules must only be rules, they must not process the data.
Consider, for example, the implementation of a mortgage loan application. The business rule layer would filter the input first for completeness, then apply any other validation. A valid rule would be granting loans only to people who are at least 18 years old. However, a rule that denied a mortgage application just because the applicant did not earn enough for the property at a specific price would not be a valid business rule. In reality, denial of a mortgage is more complicated than a simple rule could cover. And while rules like this could be expressed in computer terms, they tend to contain too many and's, if's, and but's.
A business rule should nest within other business rules, otherwise this layer becomes too fat, and requires too much processing. Neither should it depend on any data coming from higher layers—it needs to be self-supporting in all cases. In programming terms, the rules should be able to be stored in a small local file or, even better, coded within the program.
The third layer is called the Application Interface layer. This is responsible for converting the data from a business context to a technology context. The technology context is whatever the final layer, the Application Server layer, requires.
Going back to the mortgage example, the application interface might convert the request and associated data into an SQL statement, and then pass that to the final layer. By convention you would not to put any business logic into this layer, to allow for future expandability.
The final layer is called the Application Server layer. This layer has the task of processing the data, which is now in a technology context, and the process is not dependent on the actions of the user interface. Neither does the processing need to be logical in human terms. This layer is all about the storing of data and calculation of results.
For example the equation y=x/
is a mathematical reality, and can be computed for all values where b
is not zero. However, when b
is zero, the results are undefined in mathematical terms and an overflow error occurs. Yet in our own human terms, the result still has sense of reality—it's just a very big number. The point is that in this layer the data is manipulated as something only mathematics, science or computers can fully understand. Our conceptions of the result will often be wrong.b
As another example, take an SQL statement that we generated in the previous layer. While we would understand the plain English definition of the query, and probably have a good idea of what the SQL statement actually meant, we would have no conception of what actually went on inside the database while the query was being processed. It is considered to be a 'black box'.
These four layers form a definition of client server computing in a nutshell, and are of interest to anyone who needs to develop corporate solutions. But they prompt the questions 'Why do we really care about these layers at all?' and 'Why don’t we just create programs and let the layers sort themselves out?'
In fact, the whole purpose of the layer definitions is to help us understand how we divide up, or partition, our client/server applications. We ultimately have to define the split between the client and the server, in other words decide which layers will be on either side of the network connection. This is the subject of a great deal of industry debate. Typically what has happened in the past is that the layers one, two and three were on the client, and the fourth layer was on the server. This is the infamous fat client, plagued with problems of poor performance, complex maintenance, and high costs.
A second problem with corporate client server architecture, running on the company network, has always been how the client and server communicate with each other. The technical term for this is middleware—the software that makes it simple to abstract the communication. Every vendor has a solution, and they are not always compatible with each other. This causes many network headaches, and solving it would make client/server development that much easier.
However, we won't be delving into the details of which other architectures are acceptable and workable in this book, but instead we'll focus on the single architecture that interests us—Web client/server. The Web solves the communication layer problem because the HTTP protocol it uses provides a common base for all applications. What we do need to do is decide how we are going to partition our applications in this environment.
To end our look at the theory of client/server computing, We'll go through how a typical application would be partitioned under the Web client/server architecture. Layer one is the human to computer interface, and it would typically be a HTML based browser. There may be some client side controls or scripts to add to richness to the user interface, but this is purely optional.
Layer two is the business rule layer, and is generally handled on the client by the scripts and controls in the HTML page. However no parts of the rules are hard-coded into the browser, they only exist in the pages themselves. There is an argument that this can pose a security risk because the rules then need to pass across the network. However the use of Secure Sockets Layers (or Secure Channel Services) can help to reduce the risks. We'll be discussing all these topics in Chapter 9. So in some cases, either to enhance security or because a rule requires features that aren't available on the client, all or part of the business rules layer may reside on the server.
Layer three, the conversion from a business context to a technological context, occurs on the server. It could be that an HTTP request triggers a routine that creates a structure of data, or that ASP converts it to a new representation ready for the final layer.
Layer four, the application server layer, is again located on the server, and is the 'back end' that actually does the processing and produces the results. This may be a database or other business object, and the result might be retrieval of information for return to the client, or just storage of data sent from it.
So in our Web-based model, layers one and two are on the client machine, and the server contains layers three and four. We have a more balanced and better performing system, with one exception—the middleware.
At the time of writing there was no standard middleware based on the HTTP protocol. There is new software that is showing some promise of being accepted, however for it to become reality, a standard method of tunneling protocol needs to become freely available.
Tunneling is the process of securely embedding one protocol within another, so that information can be sent directly from one client/server layer to another across the 'Net, within the HTTP packets.
This ends our theoretical, and perhaps rather dry look at client/server. However, it should have indicated that there is more to the subject than just script and components. We need to think seriously about how we design our applications to conform to the accepted standards, and to get the best performance—in terms of processing, usability, and security. The remainder of this chapter looks at different aspects of designing an application that will combine Active Server Pages and some of the other technologies that are relevant. At the same time, we'll be setting the scenes for the remainder of this part of the book and the case studies that follow.