We looked at what ADO is at the end of Chapter 1, and we saw how we can connect to a database, or a non-relational data store, using a connection string. Earlier in this chapter, we also looked at a way that we can insert these connection strings into ASP pages as Server-Side Include files, to make managing them easier. There are a couple of other topics that we didn't spend time on in Chapter 1, and we'll briefly cover here before we move on to see how we can use ADO in our ASP scripts.
To use ADO in our scripts, we establish a connection with the data store using appropriate driver (or data provider) software. This driver can usually store the connection for reuse later on by another page, after our page has finished with it. Making a connection is a time-consuming business for the driver, so it makes sense to reuse them wherever possible.
However, if we use a different connection string each time, they cannot be reused. A common example of this is where we have lots of different users accessing the data, and so we create a connection string (and hence a specific connection) that contains their individual username and password. If we used the same username and password for all data accesses instead (or a limited number of different username/password combinations), the driver can reuse the connections on a more regular basis (it does this behind the scenes, without any intervention from us). Of course, if you need to have different access permissions for all your users, then you have no choice.
Connection pooling is automatically enabled in IIS4 with the SQL Server and the Oracle ODBC drivers, but is not automatically enabled in IIS3. In the latter case, you can enable connection pooling by editing the Registry.
Make sure you have backed up any data on your machine and the Registry itself before editing it. Also, make sure you do not change or delete any existing entries other than the one you intend to edit.
You enable and disable connection pooling by editing the StartConnectionPool value. In the HKEY_LOCAL_MACHINE section of the Registry, edit the value of the entry:
\System\CurrentControlSet\Services\W3SVC\ASP\Parameters\StartConnectionPool
Set it to
(one) to enable connection pooling, or 1
(zero) to disable it. The time-out before the connection is dropped from the pool can also be set in the Registry by editing the key:0
\HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBCINST.INI\SQL Server\CPTimeout
This is the number of seconds that connections will be held while idle before being destroyed. IIS sets this to
by default. In both cases, you will need to restart the Web server for the new settings to take effect60
You should not attempt to use connection pooling with the Microsoft Access (Jet) ODBC 3.5 driver, as it is not thread-safe. However, the limitation should disappear with forthcoming releases of the Microsoft MDAC 2.0 data access tools.
We've mentioned the Remote Data Service (RDS) a couple of times in the book so far, and should take a more detailed look at what it is. We'll be using it to create some administration pages in Chapter 6, and you'll see more about its application there. For the time being, in case you haven't come across it yet, here's basically how it works.
When we access data using ASP on the server we create a recordset, and normally we'll use the contents of this recordset to create HTML pages to send to the client. This means that we need to recreate the recordset on the server, build a new HTML page, and send it across the 'Net every time the viewer wants to see a different view of the data. This might be with it sorted in a different order, or showing different columns from the records.
Instead, Remote Data Service lets us do the whole thing more efficiently. When we use RDS in a Web page, the server extracts the data from our data source as a recordset—just as it would with ASP in the previous example—but this time it packages up the recordset and sends it across the 'Net to the browser, where it is cached on the client's machine. Now, they can view, sort, and play around with the data to their heart's content without us having to keep creating recordsets on the server and bundling them up in HTML pages.
This can result in a far more efficient use of bandwidth, depending on the size of the dataset. With RDS it's obviously important to limit the number of records that we include in the dataset as much as we can, because this reduces the bandwidth we absorb in sending it to the client. If we have a large dataset, and the client only wants to view a couple of records, using ASP on the server to create an HTML page is going to be far more efficient than sending a large recordset across the 'Net.
In Chapter 6, you'll see RDS in action when we build some remote data administration tools. RDS just needs an HTML page (no ASP required) with some simple script code, and IE4+ as the client browser. And, yes, there's the hitch—at present it only works with Internet Explorer 4 or better.
Depending on the features we build into the Web pages that we use with RDS, the viewer will not only be able to view the data in a variety of ways, but also update it. The changes they make to any or all of the records can be flushed back to the server and can automatically be used to update the source data. This does present some security risks, especially when combined with the fact that RDS requires the data store connection string to be present within the client HTML page.
Once a user has obtained the connection string and details of the table name and field names from the code we have to include in an RDS page, they can create their own RDS pages to access our database. They might also use the connection string to try and access the database using a tool like Microsoft Visual InterDev or Access (both of which provide a great working environment for manipulating remote data as we'll see in Chapter 6), or directly with the SQL Server client-side utilities. This means that we must choose our user accounts carefully when working with RDS, and set appropriate permissions for all databases that we provide access to.
On the Web, most access is anonymous (as far as the user perceives), and we won't know which user we are dealing with (because generally they won't log on to our Web server). This means that, in most cases, we can use a single account to access our data store, and hence get good connection pooling performance. It's only when we force users to log on as a validated NT user when entering our site, or when actually accessing the data, that we need to worry about individual usernames and passwords. We'll be looking at this situation in Chapter 5.
However, even with anonymous data access, we still need to think about protecting our data. If we have a table that all visitors can view, we'll probably want to allow read-only access to it in our database's security system. Even though visitors can’t update the contents using the ASP pages we provide, there are still risks. In particular, as we've just seen, if we use the Remote Data Service our users will easily be able to obtain the connection string details and could access the data in ways we hadn’t allowed for.
Alternatively, they might even have a go at connecting to our SQL Server using the SQL client-side utilities that are supplied with SQL Server, and thereby get access to all the databases on our server.
So it's obvious that we need to implement some level of security on the databases we are going to connect to from our Web server. We use Microsoft SQL Server as the database for our examples, and chose to use the Standard security model where the details of all user accounts for the database are stored within SQL Server. The main reason for this is that we actually need only a very limited number of user accounts, or logons.
Our site uses several databases, including one that contains almost all the data required for all the working examples on our site. Other databases hold all the user and hit logging information, and the details of all the books and site links shown on the site. There are also databases for the reference tools (an on-line glossary of terms, the HTML Reference Database and IE4 Reference Database), and one to hold the results of the regular site questionnaires we run.
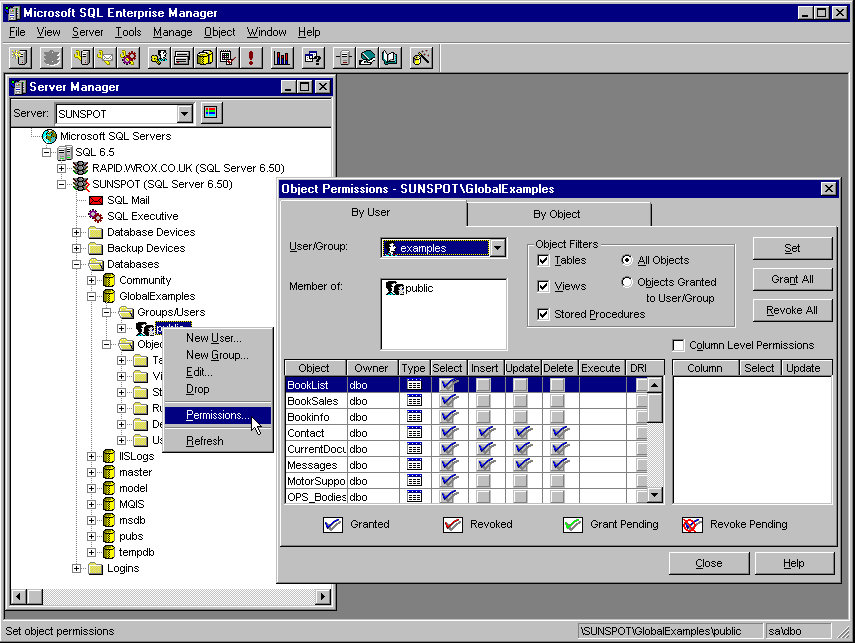
For all these, we only have three logons defined in SQL Server. The one you'll come across in this book is called Examples, it has no password, and has permissions only in the GlobalExamples database that is used by the book samples that run on our server. Here's the Permissions dialog for the GlobalExamples database, which is available in SQL Enterprise Manager by right-clicking on the public entry in the Groups/Users section of the database in the tree view and selecting Permissions:
There are other logons that provide read-only and read/write access to the other databases at two levels. One provides access suitable for anonymous users, mainly read-only, so that they can use the reference tools and view the graphical traffic reports. The other is an administrator account used to maintain the data in all the applications. The default sa (system administrator) account has a long and complex password, and is never used for normal data access purposes.