Two of the great strengths of the Internet are its anonymous nature and the lack of any central access control. As we discovered back in Chapter 5, most users (via their browsers) will expect to be able to connect to our site and access the contents without having to identify themselves. There is still a powerful tendency amongst users to consider the entire Internet as a 'free resource'. Although this is generally still the case, the number of sites that are charging for content in a range of ways continues to increase. Many services that were free when they first appeared now charge per visit or per resource.
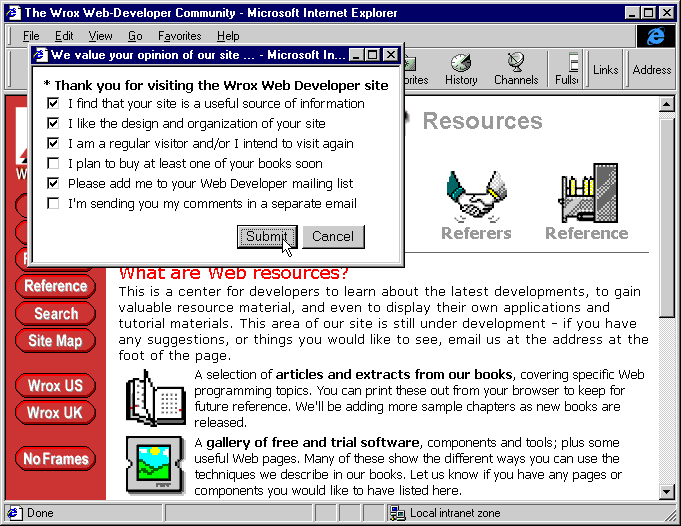
However, many sites (such as our Web Developer site) do provide useful information and resources without charge. This is because they are designed to promote products that are charged for—in our case the books we produce. By offering free access to useful resources and information, we can tempt visitors to return and thereby keep them up to date with the books we would like them to buy. You saw one way that we can measure our visitor's opinions and intentions in Chapter 7. To see if we are hitting the mark, we use a pop-up 'survey' window with a few simple questions:
Analyzing the results of a survey is useful, and can provide some vital feedback on what your visitors think. However, it's no substitute for hard statistics, and these are what our financial director will be looking for. No doubt you're aware that almost all Web servers can record visitor activity automatically, and this can provide us with the hard statistics that we need. We'll look at two techniques for collecting information; file access logging (usually referred to as hit logging), and session information (details about a user when they first enter our site).