You can build a very simple database by creating records and storing them sequentially in a large file. The problem, of course, is that it is difficult to find your records quickly. Typically, the solution to this is to build an index. An index is a file which is sorted by whatever value you are indexing. In theory an index could duplicate all the values in a file, sorting them in the particular way desired (e.g. by name or by date). This would be tremendously wasteful, as you wouldn't want all that data duplicated for every index. Thus, an index is typically implemented as a file containing a single table with two fields, the first field is the sorted value (for example, the name), and the second field is an offset into the data file, pointing at the complete record.
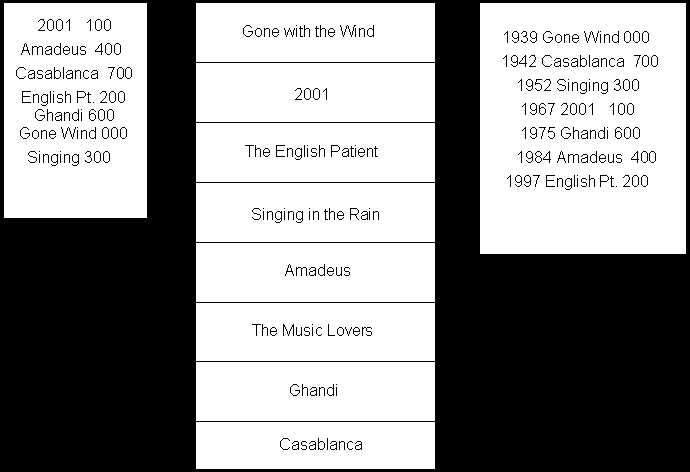
For example, suppose you are building a database of video tapes for the VideoMagix system. You might have a data file with one record for each video tape, and you might have an index file which lists the titles alphabetically. Note, the index file does not duplicate the entire data record, it contains only the sorted field (title) and the location of the corresponding record in the data file. Thus, from the title, you can find the entire data record in the data file.
Your data file would consist of a set of fixed-length records. Each video tape record might include entries for the title, the actors, the release date and whether or not it is available. Each record would begin at an offset, which is a multiple of the size of the record. Thus, if the record were 100 bytes, the fifth record would begin at offset 400. The nth record would begin at an offset of (n-1)*100. Your index file might consist of much smaller data structures, holding nothing more than the title and the offset into the data file. You might have another index file that listed the release dates, the title and the offset, so that you could quickly find all new movies or all vintage flicks.
The index file allows you to sort your main data on many different fields, without having to duplicate all the information. For example, by using these indexes, it is as if you had sorted the entire data set both by title and by release date. When the customer chooses a title (e.g. "Ghandi"), the system can quickly locate it in the index and find the offset into the data file (600). It can then jump to that offset and find the data record.
This is fast because of two underlying technologies: binary searches and seeking.
In a binary search, you look halfway into the file and decide if your target data is before or after your current record. For example, if your target is "Ghandi" and you search the index sorted by names, half way in will bring you to "English Pt". You know that "Ghandi" is after this record, so you search half way through the remaining records, which brings you to "Gone Wind". "Ghandi" is before this, so you then search half way through the remaining records. The advantage of a binary search is that when your files grow, the number of searches you need to conduct grows far more slowly. For a file containing n records, you need, on average, to search only log2(n) records. If, on the other hand, you were to look at every record in the original database you'd have to examine an average of n/2 records.
With a database of 65 536 records, brute force searching would average 32 768 searches, but a binary search would average 16 searches — a significant performance enhancement! In addition, the 32 thousand searches must each read in the entire data block while the 16 searches may read in the much smaller index records. There is simply no comparison in performance.
Once you know the offset of the record you require, you can seek directly to the record and read it into memory as a block. This is a very fast operation.