Each data member must be preserved during the process of transformation from objects to tables. This includes all "simple" attributes (native types, such as
or int
), attributes aggregated in sub-objects, and pointers to associated objects. Note that this also includes data members from all of your ancestors in the static object model.char
Mapping each attribute to a database table column can dramatically slow the performance of the system. In this one-to-one mapping model, each record is built by setting the value of the column corresponding to a particular attribute to the value of that attribute. For many attributes, the value must be transformed to match the requirements of the database. For example, a date may be stored differently in the database than it is in your object.
An alternative method is to store the entire object as a binary stream of bytes, known as a blob. Key values are stored as attributes in columns, but the bulk of the data is undifferentiated. The database cannot manipulate or sort on that data, but by using the keys, it can retrieve the blob, which can then be reconstituted in the application.
The decision of which fields to put in the blob is critical. This decision changes as the physical design of the database is modified during the development and maintenance cycles. Indexes can only be put on columns, not on a part of a blob — because the blob is just binary bits to the database. This forces us to decide once and for all time which fields to key on. The decision to add new keys requires a change to the definition of the table as well as a redefinition of the blob — an expensive maintenance decision.
This makes the design more viscous— it is harder to change as requirements shift. For this reason, many developers don't use a blob; they just make columns for their data and accept the trade off in performance. You can "throw money" at performance issues by buying bigger and faster machines, but it is more difficult (and often more expensive) to try to solve maintenance issues with cash.
In C++, we use pointers to name one object in the description of another object. This is done, for example, to capture associations. In mapping to database tables, this naming function is provided by object identifiers (OIDs). An OID is typically generated by the persistence framework as each object is saved for the first time to the database.
An OID is typically implemented using a database type, such as a
or a long
, where char[N]
is between 6 and 12. OIDs should be unique, but how unique? Arguably, they should be unique across the system, but ought they be unique across time? That is, can deleted OIDs be reused? Further, should they be unique across instances of the program (can two processes use the same OID to refer to different objects?) Should they be unique across all machines on the network? What if the network is the Internet?N
An OID that is absolutely unique is very hard to create. In theory, it would be unique across the world and across time. Microsoft offers such OIDs, called Globally Unique Identifiers (GUIDs). These are used to create unique identification for classes, interfaces and any other object. Microsoft GUIDs are 128-bit unique numbers generated by a complex algorithm, which is statistically unlikely to create duplicated numbers any time soon.
This algorithm, however, could end up creating the year 3400 problem. While I'm told you can use Microsoft's GuidGen.exe to create enough unique identifiers to name every atom in the universe, there is a known problem in their design. Each GUID includes 60 bits for the timestamp, representing the count of 100-nanosecond intervals since 00:00:00.00 on October 15, 1582. This clock will rollover in the year 3400. Watch for books on the Y3.4K problem, appearing in your bookstores early in the fourth millenium.
Each data member that is mapped to a column in a database table is represented in C++ as a primitive data type, a user-defined type or a pointer or reference to an object. Each of these must be mapped to a type that is native to the database.
Typically, the RDB will support various integer and floating formats, but they may not be the same as the ones supported by the C++ compiler you are using. The database type may be best implemented using a user-defined class in C++. Database vendor-specific code needs to be written to support these translations. Translators can be implemented by following the Strategy Pattern.
The Strategy (or Policy) Pattern (Design Patterns, Gamma et al.) is used when you may have a number of implementations to accomplish a single goal. In this case, a number of vendor-specific implementations must support the goal of translating between the C++ objects and the database itself.
The Strategy Pattern separates the translation work from the object that is doing the translation. The class responsible for translation has a
object. Translator
is an abstract base class from which you can derive concrete classes to encapsulate the specific translation algorithms for the different databases you might use. You can then plug in the appropriate derived translator object into any class that needs to interface with the database. Translator
Character strings typically come in fixed-length and variable-length formats in databases, and you may find yourself using both types. Fixed length strings are fast, but they can waste space. Variable length strings don't waste space, but they bring some overhead that can slow performance. The usual heuristic is to use fixed length strings for strings which are within narrow size limits, and then to use variable length strings for memos, notes and other fields of unpredictable length.
Databases typically support the notion of a
field. This is a field whose value is unknown. Note that there is a difference between an empty string and a NULL
character string — one says that we have a value and it is of zero length, the other says we have no value at all.NULL
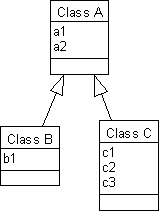
The diagram below defines class
and two subclasses A
and B
:C
The next diagram shows the memory layout for these classes:

Note that the attributes defined for class
, in this case A
and A.a1
, are part of any object of class A.a2
or B
. Thus, the question is this — how do we define our tables for the objects of our base class and our derived classes? It turns out that there are three schemes that tradeoff disk space and database performance. These options are:
C
ABCBCAABCNULL
The first approach corresponds to one class mapping into one or more tables. The diagram below shows the layout of the tables for classes
, A
, and B
under this approach. Note that the OID of the base class is captured as a column (or foreign key) in each of the tables that represent the derived classes. A join must be then done to recreate the object from the tables. This approach uses less space than the flat table approach because there are no extraneous C
fields — the fields of each table map to each attribute of the corresponding object. The approach, however, runs slower than the other two due to the joins.NULL
| Table A | Table B | Table C |
|
|
|
|
|
|
|
|
|
| Date of Creation | Date of Creation | |
| // other attributes | // other attributes | |
| Date of creation | ||
| // other attributes |
The layout of the tables for the classes
, A
and B
under the second approach is shown below. In this case, one class maps into one table. Note that the attributes defined directly in the base class are captured as columns in each of the tables that represent the derived classes. No join is required to recreate the object from the tables. This approach uses less space than the flat table approach, and runs faster than the earlier approach, because there isn't a join.C
| Table B | Table C |
|
|
|
|
|
|
|
|
| Date of Creation | |
| // other attributes | |
| Date of Creation | |
| // other attributes |
The final diagram shows the layout of the table for classes
, A
, and B
under the flat table approach — that is, more than one object maps into just one table. Note that all of the attributes defined for all of the classes are represented in the table definition for the derived classes. No join is required to recreate the object from the tables. This approach uses more space than the other two approaches but may run faster because they are always loaded. On the other hand, it may run slower, as the tables are larger in this case, and may require more disk I/O. There will be many extraneous C
fields. For example, an object NULL
stored in this table would have to leave A
all the fields for the attributes NULL
, b1
, c1
and c2
.c3
| Flat Table |
|
|
|
|
|
|
|
| Date of Creation |
| // other attributes |
How we represent the relationship between two objects depends on the multiplicity of the relationship. That is, one-to-one relationships are represented differently from one-to-many or many-to-many. You find this multiplicity in the object model and must implement it in the database.
There are two ways of mapping the relationships between the objects into the database. In the first approach, a relationship between two objects is mapped into the database by using the OID of one object as the value of a column in the table that represents the other object. In the second approach, a separate table is used to capture the relationship information. The decision on which approach to use in a specific case is based on:
If we were representing a one-to-one bidirectional relationship, then the table definition for each object should include the OID of the other object as a "pointer" to the identity of that object. For example, suppose you have a
object and a transaction
object. Each receipt
has one transaction
and each receipt
represents a single receipt
. If you modeled the transaction
as one record and the receipt
as another record, you would put the ID of the transaction
into the receipt
record and the ID of the transaction
into the transaction
record.receipt
On the other hand, if it is a one-to-one unidirectional relationship then the object that is being pointed to has the OID of the object doing the pointing. This seems backwards. What is going on here is that we have to search the table defining the pointed-to objects, in order to find the one that has the OID of the pointing object in it. Thus, the rule is that the pointer goes "the other way" in the table.
Assume, for example, that the
object needs to find the receipt
, but there is no reason for the transaction
to find the transaction
. In this case, you have a one-to-one, unidirectional relationship (from receipt
to receipt
). You might expect that the transaction
would have the ID of the receipt
, but in fact it goes the other way — that is, the database representation of the object being pointed to (the transaction
) has the OID of the object doing the pointing (the transaction
). Thus, you can ask the database to find the receipt
with the OID of the transaction
.receipt
This rule about unidirectional relationships makes much more sense when you are looking at a one-to-many relationship. For example, assume you have a
which has many actual VideoTitle
s. The VideoTape
points to each of the VideoTitle
objects (and, for whatever reason, you model that as a one-way relationship — the VideoTape
sVideoTape
never need point back to the
). In this case, it makes sense for the object being pointed to (VideoTitle
) to have the OID of the object doing the pointing (VideoTape
). Now you could query the database for every tape that has this title in its target field.11VideoTitle
Let me give you another example from VideoMagix. Imagine a club that some customers might belong to, the most frequent borrowers, perhaps. We could model this using a one-to-many unidirectional relationship between the club and the customers. To keep things simple, let's assume that a customer can belong to one and only one club. The record for each
object would keep the Customer
as an entry in its record, whereas if it were the other way around, then the record for the club would have to store many ClubID
s.CustomerID
If it is a many-to-many bidirectional relationship, then putting the OID of either object as the value of a column in the other object will not work. In this case, a separate table, known as a join table, is used.
Many
s will rent each Customer
, and each VideoTape
will rent many Customer
s. It wouldn't work to store every VideoTape
in every CustomerID
, nor does it work to store the ID of every VideoTape
in every VideoTape
(who knows how many values we'll need). It is therefore much more efficient to create a join table, which joins Customer
to Customers
, where each entry corresponds to a single VideoTapes
and a single CustomerID
.VideoTape
There are two reasons that collections are generated from the database. The first way is in the representation of associations that are not one-to-one. In this case, the object on at least one end of the association needs a collection to represent the set of objects on the other end of the association.
The second way that collections are used is as a representation of the results of a query. Queries typically result in a collection of objects, or a collection of strings that describe these objects. Each of these sets of resultsshould be represented in the return value of the query function with an instance of a collection class.
In the MFC, queries produce
s. The RecordSet
is an iterator over the set of records that satisfy the query. The actual collection of the records is hidden behind the interface to the RecordSet
; you use the RecordSet
to iterate over each record in turn.RecordSet
If you are writing your own collections to manage the results of queries, you'll want to store the results in a collection and provide an iterator for that collection. The typical implementation will use an STL collection and an STL forward iterator. Member functions will also be needed, if only to append to the collection, add by position, delete from the front or back, delete by position and get the length etc. These collections can typically be implemented as template classes, as all of the objects that satisfy a query are of the same type or are all descended from a common base type.