Getting transaction processing right is not a trivial exercise. While you can certainly write your own transaction processing software, it is often a better design decision to purchase this technology from a vendor who specializes in these issues. Creating a robust transaction processing system which operates in a multi-tasking environment is not for the faint hearted.
Most commercial TP systems consist of:
Transaction processing systems are often called Transaction Management systems, and commercial systems that integrate all of the transaction management mechanisms are called TP Monitors.
Requirements for a good TP system are stringent:
Transactions are the "unit of work" in a TP system. The application programs bracket their work with transactions. More formally, a transaction is the execution of a program that performs a function for a user in an atomic, consistent, isolated and durable fashion. A transaction typically updates a permanent store or resource, such as a database.
TP systems support the style of client/server processing that On-Line Transaction Processing (OLTP) requires. It provides services to users, programmers and administrators.
On-Line Transaction Processing is defined as a soft real time system that processes transactions
The API for a transaction monitor must support the following capabilities:
startcommitabortThe application programmer is also given tools to develop applications for this environment. These include compilers, debuggers, transaction trace displays, database browsers and object browsers.
System administrators have their own display interfaces and applications. TP-systems often provide service to users in distributed geographic locations using a variety of equipment. Modern TP systems provide an open environment for system administration, often using standard protocols such as SNMP (Simple Network Management Protocol) to administer their devices.
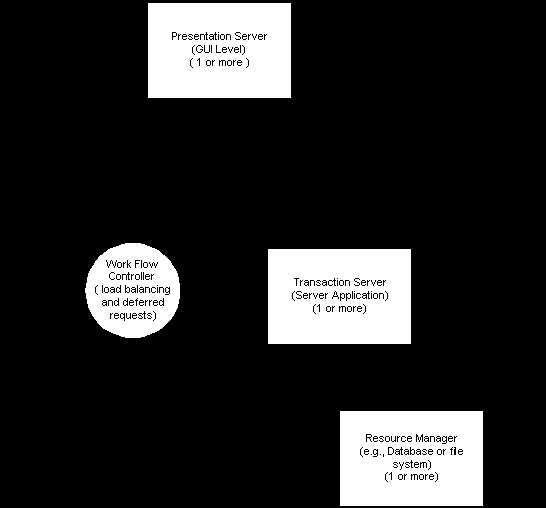
Commercial TP Monitors come in two flavors. There is a two-tier TP monitor, consisting of a presentation layer and a database server, but the most popular is a three-tier solution.
A three-tier TP monitor consists of:
The back-end programs are known as the transaction servers. The transaction server will interact with one or more resource managers. In addition, the transaction servers contain the business objects and implement the business logic as directed by the workflow controller.
The workflow controller routes requests to the transaction servers. It also provides standard services, such as lock management and log management. The application programmer supplies the logic that maps a request to a series of transactions processed by specific transaction servers.
A diagram illustrating the architecture of a 3-tier TP monitor is shown below:
TP monitors are nothing new, and were originally implemented using procedural programming techniques. There are a few views emerging on how this functionality can be mapped to the constructs used in the object world. The views vary in whether they put the business rules in the workflow controller or in the transaction servers. A workflow-centric view is expressed by architecture in which the workflow controller supplies the business logic and the transaction servers supply the business objects. Business objects, like
and Customer
, are reusable in many circumstances. So the workflow controller contains the logic required to exercise the business object's capabilities in support of the user's specific requirements. Account
The client of the TP Monitor is known as the presentation manager. Classic TP systems included the presentation manager as part of a bundled solution, but modern TP systems are open systems, that is, they are designed to work with various databases and on a variety of operating systems, in which the programmer designs the UI.
The presentation manager is typically divided into two components — the front end UI and the infrastructure needed to package the request into a standard form, and to manage the communications with the workflow controller.
Presentation managers require many of the capabilities of vanilla client/server support:
In addition, presentation managers require geographic entitlement. Geographic entitlement is authentication which maps the user's actual network location (the specific computer in use) in addition to identification and password.
Usually you try to validate the user's data entry in the presentation manager, as opposed to letting the server software catch any errors. Users want their errors to be caught as soon as possible, so that they don't waste time filling in fields that might have to be erased when their error is caught. This means that either we have to validate on the client, or we have to send each field (or each "significant" field) back to the server to be validated. The network traffic this implies may cause the system to miss its performance goals.
Validation can be strictly syntax-based, context-free or context-based:
Syntax-based validation and context-free validation can typically be done directly in the presentation manager. However, it may be too expensive in network traffic for context-based validation to be done on the client machine. This depends on the degree to which business model is exposed in the presentation manager. If DCOM or CORBA style architecture is used, then every relevant business object will have a proxy on the client. In this case, the data is "available" to do the context-based validation directly on the server. Depending on the scheme used to cache business object data members in the proxy, running the validation may or may not add a significant amount of network traffic.
The alternative is to do some or all of the validation on the server. This means either that the user has to wait until the form is submitted to see his errors, or that network bandwidth will be allocated to validating user input as it is entered. One way to do this is to use a set of rules to determine when to send data to the server application. This can be done with a rule interpreter in the client. A simpler solution is to mark display fields with a send-immediate flag: the presentation manager would format and send a validation request to the server whenever one of these flagged fields is entered.
The back end of the presentation manager takes the input from the form and formats the request. It then submits the request to the server using the vendor-supplied communications mechanism. Responses from the server are forwarded to the presentation component for display to the user.
The back end of the presentation manager is responsible for formatting the request. The request usually includes an identifier for the user and for the presentation manager (perhaps the network address), the request type and the request parameters. As we saw in the previous chapter, this is the type of information that is needed for any IPC request. The
, begin
and commit
commands are typically issued by the workflow controller or the transaction servers, not the presentation manager.abort
Workflow is nothing more than a sequence of steps required to accomplish a complicated task. The workflow controller is responsible for balancing the load on the transaction server; it encapsulates knowledge of which steps must be accomplished in what order.
The workflow controller is a "store and forward" object — it exists to limit the number of communications sessions required. Without the workflow controller, communication between n clients and m servers would require n*m connections. With 5 000 clients and 40 servers, that would require 200 000 direct connections.
By using a workflow controller, you can reduce that to n+m. The n clients each link to the workflow controller, and the workflow controller then links to the m servers. Thus we can reduce the 200 000 connections to 5 040.
This is a classic hub architecture, in which all the clients and servers are on spokes, and the workflow controller sits at the hub as a central point of communication and switching. You see this architecture implemented in the phone system (where each central office is a hub), in the FedEx delivery system (all packages go into one site from which they are all dispatched) and in the mail system (where each post office is a hub).
The workflow controller also provides a façade to the back end of the TP system. This includes the transaction servers as well as four other components:
There are three approaches to writing workflow programs.
One issue that is of significance is exception handling. A transaction server or even the whole computer system may crash. This will cause the transaction to abort. Some systems allow the application programmer to supply an exception handler that runs after the system has restarted. The exception handler is passed a description of what caused the transaction to abort. If the chained model is used, a transaction is automatically started for the exception handling. If the unchained model is used, the exception handler usually brackets its work with transaction boundaries. STDL, for example, supports automatic exception handling in its own transaction.
One idiom that has evolved for workflow programming deals with lost requests. The problem is that, if the transaction aborts, the user may never receive any information on what happened. The user would have to manually resubmit the request. This can be finessed by ensuring that the TP monitor receives the request message within the transaction boundary. Then, if the transaction aborts, the request is replayed.
This wasn't a problem in classic TP systems, because they polled their clients. The client/server paradigm has the client submit the request to the server instead. Modern TP monitors support message queues (discussed later in this chapter) as a solution to this problem. The manager of the queue is a resource manager that supports the commit or abort of transactions like any other resource. If the transaction includes an explicit fetch of the request from the message queue then the request will be restored to the queue by the queue manager following an aborted transaction.
The lock manager is the system component used by the resource managers for managing locks. It stores all of the locks in a memory-resident lock table and has exclusive access to this table. The lock manager API typically includes functions to lock an item in a given mode (for a given transaction), to unlock a lock on an item for a transaction and to unlock all items for a transaction.
The lock manager grants a request if there are no conflicting locks. Otherwise, the request for the lock is added to the list of transactions waiting for a lock on that data item, and the transaction is suspended. When locks are changed or dismissed on the data item, the list of waiting transactions is examined. Any locks that are now compatible with the (revised) set of locks for the data item are now granted.
When a transaction is committed, all of its effects on the resources are made permanent and all of its locks are released. This has to be done in the correct order to be effective and safe. When a transaction is aborted, all of its effects are rolled back and all of its locks are released. This also has to be done in a well-defined order. Additionally, after the system recovers from a system crash, the effects of all committed transactions should be durable, and all uncommitted and aborted transactions should have no lasting effects.
The most popular way to provide these capabilities is to use a log file to record the effects of each transaction. Protocols are defined that regulate the interaction of resource writing, log writing and lock operations. The log file is also involved in the procedures that are used to recover from a disk crash.
Classic TP systems provided a log manager to manage the log file, and a transaction manager to coordinate the actions of the resource managers for commit, abort, system restart and media recovery activities. Modern TP systems bundle all of this under the rubric of the recovery manager, with one exception: transactions that update more than one resource require the services of a transaction manager.
Consider a transaction that updates two databases. The protocols that are used to commit the updates must ensure that both resource managers are able to commit the changes that either resource manager is asked to commit. Otherwise, it is possible that one resource manager may be able to commit the updates, while the other is not able to do so. In this case, the transaction would not be atomic — it will have been durably updated one database and not the other.
TP systems define a transaction manager that is responsible for coordinating the resource managers using a protocol that respects this requirement. The protocol is called two-phase commit, because it first asks each resource manager if it is able to commit and only then, in a second phase, does it ask each resource manager to commit the changes. The two-phase commit protocol is discussed in more detail later in this chapter.
Transaction servers can be replicated to improve system availability and system performance (response time and throughput). The replication architecture determines the type of improvements. For example, many servers are intimately tied to a resource, such as a database. If we replicate the server, but do not replicate the resource manager and the resource (the database), the result is that we improve availability, but do not improve performance. Most systems therefore replicate the resource and its manager, as well as the transaction server.
Replication can be synchronous (all replicas are updated at the same time), or asynchronous. Synchronous replication adds a significant load to the transaction environment and so is not used very often. If the transactions are posted asynchronously to different servers, however, the effects of the ordering of the transactions must be preserved.
This ordering requirement contributes to the complexity of replication algorithms. This is exacerbated by the requirement that when replicas fail, they should provide a recovery mechanism guaranteed to process any missed transactions, again, in the right order.
As if that wasn't bad enough, servers may mistakenly think other replicas have failed due to a communications failure. This can partition the network into two or more sets of servers, each of which think they are the only ones servicing the transactions. These sets of servers may each update a shared resource, such as a database. Eventually, the network will be reconnected and the various resulting inconsistencies must be resolved.
Replication can be done by designating one copy of the transaction server as the primary server, directing all processing to the primary server, and then updating the secondary servers. This is called single-master replication.
Another technique is to allow all of the transaction servers (that is, the replicas) to update in parallel. This is called multiple-master replication and is used when nodes may be disconnected from the system. For example, an insurance salesman may disconnect his laptop computer when visiting clients. The salesman will update his local database when he sells a policy. At some point, these updates must be resolved with the master database. One variant of multiple-master replication designates one server as the primary. Another variant, called distributed multiple-master replication, implements replication without a primary.