Users of databases will be familiar with the idea of extracting important data out of a large database by use of a query. Users of event-driven systems would be familiar with extracting important data out of a large flood of events using a filter. In both cases, a reduction method is available to expose only the interesting data. For HTML host objects in JavaScript, collections are the equivalent approach. A collection is just a group of related objects, which in JavaScript translates into an array of objects.
Therefore the DOM offers two ways of accessing host objects: by navigating the object hierarchy directly which might be quite a lengthy process, and by extracting a collection of interesting items from the hierarchy and then looking at them directly.
Often the script writer will know exactly which object is wanted, and will extract a collection from the hierarchy that reduces to the single object desired. At other times, a collection might be extracted that contains a group of matching items. Occasionally the scriptwriter might see fit to go poking through the hierarchy in detail if some complex analysis is required of the document. So both approaches have their place.
If a collection object is changed, the hierarchy is updated as well, and vice versa. The objects are the same in both cases, so the system is fully coordinated.
The DOM standard describes the important objects that are used to represent an HTML document inside a program such as a browser. Unfortunately, it does not yet (at this time of writing) describe the gory details of how this is to work in client-side JavaScript, nor is the standard complete or even ratified. So it is a bit early to be labeling browsers as compliant or non-compliant to the DOM.
What is easy to say is that Internet Explorer 4.0 is the first available browser to include support for the central, important features of the DOM. At this time of writing it is the only such browser. Since the DOM standard is yet to be completed, it is hard to claim that Internet Explorer 4.0's implementation is compliant to that standard.
The DOM has two key things to say: all the tags in an HTML document must be accessible as objects and it must be possible to retrieve the HTML source that those tags objects originate from. Only Internet Explorer 4.0 provides extensive functionality for both.
Meanwhile, the more obvious objects available to JavaScript in earlier versions of browsers still exist, such as forms and images. However, these are now considered separate to the 'main event'—the DOM. Of course, they still represent a convenient and compatible way of achieving a range of tasks within the browser.
For Internet Explorer 4.0, locating an arbitrary tag's object revolves around the document.all property, which is itself an object. 'All' means all the tags in the document, but there's a catch: a few tags are missing. These are the <HTML> and <HEAD> tags, and all the tags used inside the head. So 'all' really means "all the parts of the body of the HTML document". Any <SCRIPT> tags in the head can be retrieved another way via the scripts collection.
This example appeared earlier, but here its <HEAD> is missing, and each body tag has an ID attribute:
<HTML>
<BODY ID="page">
<H1 ID="intro">Think Pink!</H1>
<BLOCKQUOTE ID="quote">
All marshmellows, azaleas, but <STRONG ID="extra"> not </STRONG> panthers welcome.
</BLOCKQUOTE>
</BODY>
</HTML>This JavaScript illustrates a number of points about tag object access:
var tag_object;
tag_object = document.all.page; // The <BODY> tag
tag_object = document.all["page"]; // The <BODY> tag
tag_object = document.all[0]; // The <BODY> tag
tag_object = document.all.extra; // The <STRONG> tag
tag_object = document.all.quote; // The <BLOCKQUOTE> tag
tag_object = tag_object.children.extra; // ... the ID="extra" sub-tag
tag_object = tag_object.parentElement; // ... back to <BLOCKQUOTE>
The three lines at the top show that the all object is an array-style object, similar to the document.forms or window.frames objects in the browser. It has two crucial differences. Firstly, its properties are named after the ID attribute of their respective tags, not the NAME attribute. Secondly, all the document's tags appear in the array, not just the top-level tags, as the middle line of the example shows. This is because the all property is a collection.
The last three lines illustrate how to move around the object hierarchy. Every tag object has these properties that hold the object hierarchy together and make navigation through it possible:
children—an array of the tags immediately contained within this tagparentElement—a simple property pointing back to this tag object's parent tag objectall—an array of all the tags contained directly or indirectly within this tag
The first two properties, plus the children.length property (recall it is an array) are enough to step through all the tag objects in the hierarchy. The hierarchy is a 'tree' structure, and since the tags are added to the hierarchy in the order they are discovered in the HTML source document, you can find all the tags by stepping through all the children arrays, and the children's children, and so on. In computer science terms this is a 'pre-order traversal' of the hierarchy.
There's not much point navigating the object hierarchy if there is nothing worth having in there. Therefore each tag object has four further properties: innerText, outerText, innerHTML and outerHTML. Each of these properties contains a different variant on the tag's contents. This table explains which to choose:
| Content only | Content and HTML tags | |
| Include markup used by tags | outerText |
outerHTML |
| Exclude markup used by tags | innerText |
innerHTML |
'Content only' means the script writer only wants to see that which is marked up by HTML tags and not the tags as well. 'Include space used by tags' applies mostly to replacing the HTML source—it means that the piece of document to be replaced should include the tags that mark the beginning and the end of the piece (such as <DIV> and </DIV>). You replace HTML source by assigning a string to one of these properties.
The alert boxes for this example are shown below:
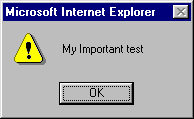
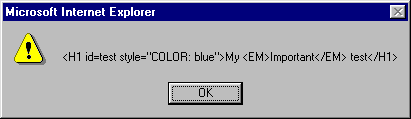
<HTML><BODY>
<H1 ID="test" STYLE="color:blue">My <EM>Important</EM> test</H1>
<SCRIPT>
alert(document.all.test.outerText);
alert(document.all.test.innerText);
alert(document.all.test.outerHTML);
alert(document.all.test.innerHTML);
</SCRIPT>
</BODY></HTML>

It is not until you try to change the document using the outerText/innerText properties that a difference appears between those two properties. The outerText case removes the delimiting tags as well as their content.
There is a further subtle effect at work in this example. Notice that the last two alerts do not retrieve the HTML source exactly as it appears above—there are spaces missing, and the quotes around 'test' are gone. The HTML source is actually reconstructed from the browser's understanding of the document. This is slightly different to the 'View Source' window that shows the original HTML document verbatim. Usually no meaningful information is lost. Note that retrieving the source of a JavaScript script or a JavaScript function does not suffer from this problem.
If you set innerText or outerText properties, the text you supply will appear literally in the browser. If you set innerHTML or outerHTML, any tags in the new text will be interpreted before display.
Reading and setting the source for an HTML tag object is not very convenient if you are only interested in a single feature of that tag, such as an event handler or a tag attribute. There is a better way—each tag object has properties for all the valid tag attributes. This is consistent with the older-generation objects such as form text field objects, and works in exactly the same way.
A tag may have an attribute that isn't in any standard—recall that HTML is only an advisory markup language—or may have an attribute value that doesn't make sense. Such detail might be meaningful to some specific Web server or HTML editor, even if browsers pass over it. It's hard to anticipate unknown attributes, so properties on the tag object aren't created for them. Tag objects support three special method properties that give access to these unknowns:
getAttribute()—extract any attribute's literal value.setAttribute()—set any attribute to any value.removeAttribute()—throw an attribute for a given tag away.
Finally, the style property of a tag object is itself an object. Its own properties match any CSS1 or CSS-P attribute for that tag. Stylesheet names translate to JavaScript property names directly, except that hyphens are dropped in favor of a capital letter. So color becomes color, but background-color becomes backgroundColor. These properties of the style property aren't as all encompassing as you might think, but Internet Explorer 4.0's features are sufficient to make them very powerful when used. The features are:
STYLE attribute in the tag can be read.<STYLE> tags is available elsewhere, not in the tag object.
Sometimes the scriptwriter isn't interested in a whole HTML documents structure; just a slice of it. A typical example is user input via HTML forms. Usually you don't care how many nested <OL> tags surround the form—you just want to get at it. In JavaScript, a collection means an array object, and the like-minded objects are stored one per array element.
If it wasn't for object collections, the Navigator 4.0 browser would have very little dynamic HTML capability. Even Internet Explorer 4.0 would lose some important flexibility.
Using a collection is the easy part: access the correct array element, or a conveniently named property of the collection object, and you have the same object that you would have found if you had gone poking through the object hierarchy for it. For tag objects, this means access to the style, innerHTML, getAttribute() properties and so on, as described above, but beware! most of these properties are specific to Internet Explorer 4.0.
The trick is to find or make the collection in the first place. There are several sources of collections.
Some objects are so useful that they are always available from JavaScript. It's tempting to call them 'built-in' collections, but that term already means 'native JavaScript features' in ECMAScript language, so it is best not to overuse it.
An obvious example of a readily-available collection is the document.forms object. Clearly this is a collection of <FORM> tags in the current document. Similarly, the document.images array is a collection of <IMG> tags, and the document.form[0].elements array is a collection of <INPUT>, <SELECT> and <TEXTAREA> tags (assuming there is at least one form present in the document). Viewed from the DOM perspective, you can say that all JavaScript-enabled browsers provide some DOM collections, but only one (Internet Explorer 4.0) supports the DOM hierarchy directly. For the rest, the DOM hierarchy is 'invisible'.
For Internet Explorer 4.0, a further example is the document.styleSheets object which is an array/collection of objects, one per <STYLE> or <LINK> tag present in the document. Each of the collection elements has a property rules, which is an array/collection of the individual CSS rules. Internet Explorer also has a scripts collection for all the <SCRIPT> sections in the document. Of course, document.all is the most useful pre-created collection for that browser.
For Netscape Navigator 4.0, there are three collections that contain style information: ids, tags, and layers. It is the third of these, layers which provides much of the Dynamic HTML functionality for that browser. The layers collection contains an object for every tag that has an absolute or relatively-positioned style. It also contains every instance of the <LAYER> tag. Each object in the layers collection contains properties matching all the CSS-P style attributes. The other two collections are mostly used for (statically) specifying JavaScript style sheets (JSSS).
With all these pre-created collections, you might wonder if there is a 'CSS Object Model', 'Script Object Model', or worse still a 'Collections Object Model' that describes a hierarchy of pre-created collections. There are some remarks in the DOM draft standard about support for the collections present in the 3.0 browsers, but beyond that you are mercifully spared another standard.
A few collections are bundled up inside the DOM object hierarchy itself. Since only Internet Explorer 4.0 has the DOM hierarchy, they are specific to that browser:
children—for each tag object, all the tags directly contained in this one.filters—for each tag object, any style filters applying to this tag.You might prefer to see the style property of each tag as a collection, but technically it's not an array object, since there's no length property.
The most useful form of collection for complex HTML documents is the one you make yourself. Internet Explorer's DOM features provide two ways of extracting a collection:
var id_collection = document.all.item("id23");
var tag_collection = document.all.tags("P");
The first case draws out the tag objects for all of the tags in the document that have ID="id23" as an attribute. The second case draws out all the tag objects from the document that are <P> tags.
Each tag object is referenced as an ordinary array member. There is also a shorthand notation for the item() method which allows a single tag object to be extracted. This script fragment illustrates both cases:
var all_headings = document.all.tags("H2");
all_headings[0].styles.color = "blue"; // 1st H2 now looks blue
var third_checkbox = document.all.item("boxlist1", 2); // get the 3rd checkbox