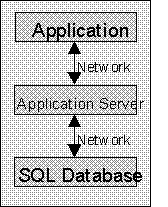
Over time it has become apparent that two-tier client/server is simply not powerful enough or flexible enough to handle many larger applications. Since each client workstation maintains a dialog with the central database server, the network traffic can be quite high. Furthermore, the central database server can become a performance bottleneck - as many users try to access the same resources at the same time.
Three-tier client/server helps address these issues by putting another physical server between the users and the database. This central application server can more efficiently manage network traffic and the load on the database server.
Better still, it is typically much easier to add more application servers than it is to add more database servers. Adding a database server would require us to split our data between the database servers, whereas adding an application server should just require some relatively minor changes to parts of our application:
Just like two-tier client/server, the data processing is handled primarily on the database server. However, we now have an application server that can do a lot of work. This means that we can move a substantial part of our application off the user's workstation and onto the application server.
There are a number of benefits to distributed processing, including:
How much processing is moved to the application server may vary. It depends on many factors, but mostly we need to decide how much work we want our client workstations to do. Designs range from having the client workstation do virtually nothing to the client workstation doing almost everything. We'll discuss the pros and cons of each approach in Chapter 2.
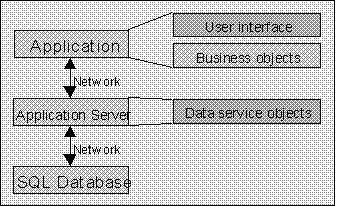
As I've shown it in this diagram, much of our business logic remains on the user workstation. In Chapter 2, we'll explore why it can be very beneficial to have the business objects on the client workstation as shown here.