| January 2000 |
by Dianne Siebold
Reprinted with permission from Visual Basic Programmer's Journal, January 2000, Volume 10, Issue 1, Copyright 2000, Fawcette Technical Publications, Palo Alto, CA, USA. To subscribe, call 1-800-848-5523, 650-833-7100, visit www.vbpj.com, or visit The Development Exchange.
SQL Server includes ten simple but powerful aggregate functions that prove particularly useful in reports that require summary information (see Table 1). However, the power of these functions derives not from their individual functionality, which is modest if considered in isolation, but from the way you can combine them to create complex queries.
|
In this column, I'll explain what each of SQL Server's aggregate functions does, as well as how to use each one. All the examples use the SQL Server Northwind database, so you can cut and paste any of the code and test it yourself. The ten aggregate functions include six general functions and four statistical functions (see Table 1). These functions are simple in themselves, but how you implement them and how you handle nulls and distinct values can vary your results.
Before diving into the functions themselves, let's go over the language you use to implement them. You use Structured Query Language (SQL) to communicate with a SQL Server database; Transact-SQL (T-SQL) is Microsoft's version of SQL. For example, you might use SQL commands to communicate with a database through an application, perhaps using ActiveX Data Objects (ADO) to send a SQL statement to query a database. Or, you might use T-SQL interactively by calling a stored procedure from inside SQL Server's Query Analyzer. T-SQL is a full-featured programming language, and its syntax contains the standard SELECT, INSERT, UPDATE, and DELETE commands. This language also includes conditional logic statements and syntax to create cursors. T-SQL's functions fall into one of three categories: rowset, aggregate, and scalar (see Table 2). I'll concentrate solely on aggregate functions in this article.
Aggregate functions have two characteristics: They operate on multiple values or rows, and they return a single summarizing value. For example, the AVG function takes the values from a column and returns the mean value. You can use aggregate functions in a COMPUTE BY clause, a HAVING clause, or in the return list of a SELECT statement. You cannot use aggregate functions in a WHERE clause, although you can create a WHERE clause to restrict the number of rows the function acts upon. The AVG function returns a mean value in a standard SELECT statement. For example, this code returns the average UnitPrice of all records in the Products table:
SELECT AVG(UnitPrice)FROM ProductsThis function includes all rows in its computation by default, but the DISTINCT keyword limits the values AVG acts on to only the unique instances of a value. For example, this query returns the average price of all distinct beverages in the Products table:
SELECT AVG(DISTINCT UnitPrice)FROM ProductsWHERE CategoryID = 1---------------------48.4687This query returns the mean price of all beverages in the Products table:
SELECT AVG(UnitPrice)FROM ProductsWHERE CategoryID = 1---------------------37.9791Using DISTINCT in the first SELECT statement changes the nature of the query completely. Also, some functions don't support DISTINCT when you use the CUBE and ROLLUP commands. You can use the AVG function only on numeric columns; these columns have a defined datatype of int, smallint, tinyint, decimal, float, real, numeric, money, or smallmoney. The AVG function's returned datatype value depends on the expression's datatype. For example, any integer expression returns a value of type int. But you get a different result if the expression contains two datatype values:
SELECT AVG(UnitPrice * Quantity)FROM [Order Details]--------------------- 628.5190The UnitPrice column has a datatype of money, while the Quantity column has a datatype of smallint. SQL Server follows the rules of data-type precedence in this case. Datatype precedence converts the second value to the value type with the greatest precedence (see Table 3). Thus, the return value is of type money in this example.
Aggregate functions become more powerful when you use them with the GROUP BY clause, because you can employ them to return multiple summary figures. The GROUP BY clause restricts the rows returned in a resultset, permitting only a single row to be returned for each group value. Consider another query, where you group the Order Details table by OrderID, so only a single row is returned for each OrderID. The aggregate functions provide a summary for each group. This query returns the OrderID and the average order amount for each order:
SELECT OrderID, 'OrderAvgPrice' = AVG(UnitPrice * Quantity)FROM [Order Details]GROUP BY OrderIDOrderIDOrderAvgPrice -------- -------------10248146.666610249931.700010250604.333310251223.6000102521243.3333Note that you must calculate the order amount for each order from the UnitPrice and Quantity columns before you average the order amount.
Another consideration when using T-SQL functions is how they handle columns with nulls in them. You might expect that a function returns null if the expression column contains null values, but all aggregate functions except for COUNT ignore nulls. This is a tricky issue. If you use an aggregate function with the results from the COUNT function, your results might vary because of the way they each handle nulls.
The AVG function serves as a good model for other aggregate functions. For example, you implement T-SQL's MAX, MIN, and SUM functions much as you do AVG. MAX returns the greatest column value in a range of records:
SELECT MAX(Quantity)FROM [Order Details]------ 130You can use the DISTINCT keyword with MAX, but Microsoft left this keyword in only for backward compatibility; it doesn't change how the MAX function works. You can use MAX with columns of any datatype except bit, text, and image. Using MAX with character columns prompts it to find the greatest value alphabetically. For example, MAX returns def if you have the values abc and def. Note that this function is case insensitive.
Conversely, MIN returns the smallest column value in a range of records. You can use it with numeric, character, or datetime columns, and it also ignores nulls. The SUM function returns a total of all the expression values. Specifying DISTINCT causes SUM to return the total of all unique expression values. Unlike MAX and MIN, SUM works only with numeric columns. You can use SUM and a table join to return totals for each customer (see Listing 1).
You can use all four functions discussed so far together. For example, you can create a query that finds the largest order amount, the smallest order amount, and the average order amount for each employee (see Listing 2).
The COUNT function behaves slightly differently than other aggregate functions. The COUNT function evaluates a given expression and returns the number of items in a group. You can use COUNT in several different ways. For example, using COUNT(*) returns all the items in a group; unlike other aggregate functions, it includes null values and duplicate values. COUNT(*) doesn't take an expression because it returns all rows in a table that match your criteria:
SELECT COUNT(*)FROM Orders----------- 831SELECT COUNT(*)FROM OrdersWHERE EmployeeID = 4----------- 157You can use the DISTINCT keyword with COUNT to return the number of records that have non-null, unique values. For example, this query returns the number of unique EmployeeIDs in the Orders table:
SELECT COUNT(DISTINCT EmployeeID)FROM Orders----------- 9You can also combine the COUNT function with other aggregate functions in this manner:
SELECT COUNT(*) AS Orders, SUM(Freight) AS FreightTotalFROM OrdersWHERE CustomerID = 'ALFKI'OrdersFreightTotal ------ ----------6225.5800Like other aggregate functions, COUNT can be used with the GROUP BY clause:
SELECT ShipCity, COUNT(*) AS OrderCountFROM OrdersGROUP BY ShipCityORDER BY ShipCityShipCityOrderCount----------- ----------NULL1Aachen6Albuquerque18Anchorage10Århus11Barcelona5The aggregate functions for returning statistical standard deviations are STDEV and STDEVP. Standard deviation is the average amount that a number varies from the average number in a series of numbers. STDEVP returns the standard deviation for all a given population's expression values. You can use both functions only with numeric columns.
The other two statistical functions, VAR and VARP, return the variance of all expression values and the variance for all a given population's expression values, respectively. A variance is the square of a standard deviation.
You can use all aggregate functions in stored procedures because you write them in T-SQL. The same holds true for triggers, a type of stored procedure that executes when you perform an INSERT, DELETE, or UPDATE operation on a table. For example, you might want to restrict the value in the Freight column so it's always greater than the average freight amount when the user updates the table:
CREATE TRIGGER TU_Orders ON [Orders]FOR UPDATE ASdeclare @ValidCount int--Check to see if this col is updatedif update(Freight)begin--Get a count of recordsselect @ValidCount = COUNT(*)from inserted--where the new value is greater--than the table averagewhere inserted.freight >(select avg(freight) from Orders)--If the new value isn't greater--than the average, roll backif @ValidCount <>1beginrollback transactionendend
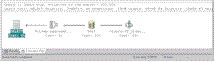 | |
| Figure 1 Fine-Tune Your Queries. Click here. |
One thing remains: You might want to run the Index Tuning Wizard if you have complex queries that use aggregate functions or return large resultsets. Run this wizard by opening the query in the Query Analyzer and selecting Query, then Perform Index Analysis. The wizard suggests table indexes that can optimize a query's performance. Of course, it's a judgment call as to whether you should go ahead and create the index, because it might affect other indexes or queries. For example, compare this query's performance when run with and without indexes (see Figure 1):
SELECT ShipCity, COUNT(*) AS OrderCountFROM OrdersGROUP BY ShipCityORDER BY ShipCity For example, compare this query's performance when run with and without indexes (see Figure 1).
About the Author: Dianne Siebold is a consultant and author specializing in Visual Basic and SQL Server programming. Reach her by e-mail at dsiebold@earthlink.net.