Everyone seems to know that ADO provides connection pooling, and that it must be a good idea, given all of the fuss about it. Fewer people seem confident about using it in their applications. Rob Macdonald has been exploring just how connection pooling works-both for traditional client/server and for newer n-tier/ASP applications.
There are certain givens about database connections: They're expensive to create, and they're expensive to maintain. Ever since developers have been writing programs that connect to servers, we've faced a dilemma about how to manage connections:
It's a classic "rock and a hard place" dilemma. Neither option is ideal. What we really need is something in between that doesn't require too much work on our part. When we're using a connection frequently, we want users to perceive response as virtually instantaneous, yet when server demand is light, we want server resources to be managed conservatively. This is especially true of n-tier applications where business objects or ASP code might be handling multiple users and the concept of a "session" starts to break down, but it's also true of traditional two-tier apps that have a lot of users.
Connection pooling is designed to solve this problem. With ADO, we can have a pool of connections managed on our behalf. The size of the pool is "demand-sensitive," meaning that it will be empty when nothing has happened for awhile, but that it might contain several live connections in a busy middle-tier application or associated with a Web site. When you ask for a new connection, if a pooled connection matches your requirements, it will be given to you; otherwise, a new connection will be created. When you release a connection, it will be pooled and will remain pooled until either it's reused or released from the pool because there's insufficient demand to justify keeping it open. All of this pool management is handled automatically, so programmers really don't need to think too much about it.
Although the idea of pooling is simple enough, many people have been put off by the practical details, which are complicated by a number of factors:
Let's begin by looking at the different technologies and their terminology. ODBC introduced connection pooling in ODBC version 3.0-although making it work required either making Registry changes or using Microsoft Transaction Server (MTS). By version 3.51, however, ODBC connection pooling was easily configurable using the ODBC Control Panel Applet, and it could be easily monitored via the NT Performance Monitor.
In OLE DB, Microsoft introduced the term "session pooling" (sometimes called resource pooling) to highlight the fact that OLE DB providers could provide all kinds of services aside from database connections. However, in ADO terms, it still means creating pools of connection object resources. Session pooling became part of ADO with version 2.0, but it continued to use ODBC connection pooling whenever ODBC drivers were used from ADO. This changed with ADO 2.1, so that session pooling was used instead of ODBC connection pooling. However, ADO session pooling can still be disabled where it still makes sense to use the ODBC approach.
MTS, however, provides genuine resource pooling. It can manage pools of many different kinds of resources. Under Windows 2000 and COM+, this can include any ActiveX component that uses an appropriate threading model. Resource pooling works differently from session pooling and connection pooling, and the difference affects the way we write code for any ASP applications, or VB components running under MTS.
Whichever technology is being used, I'm going to be using "ADO connection pooling" to refer to pooling in general unless I specifically want to address one of the three technologies mentioned previously. All of my examples are using ADO 2.1, so ODBC connection pooling is out of the picture. There are four key points to keep in mind about ADO connection pooling:
In the examples that follow, I use SQL Server 7 and monitor the number of connections using the Performance Monitor. Note that most other databases have their own ways of monitoring the number of live connections. I'm going to consider two common scenarios:
Two-tier programs traditionally create a connection object at startup and hold onto it until they're closed. However, by exploiting pooling, we can make our applications more resource-efficient. Many users keep applications open all day, although they might use the program in intensive bursts, with periods of inactivity lasting anywhere from a few minutes to a few hours. Connection pooling means that the pool will release the connection during these periods of inactivity. The price is the one-time connection overhead when activity first starts up. Let's see how this works.
The following code represents all of the code you need for a complete ADO application. I've added a time delay of eight seconds into the function to make it easier to interpret the Performance Monitor trace.
Private Sub cmdDoSomething_Click()Dim rs As New RecordsetDim dTime As Doublers.Open "select * from Authors",
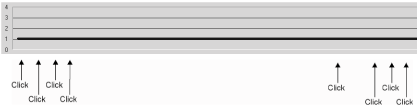
"Pubs"dTime = TimerDoLoop Until Timer - dTime > 8rs.CloseEnd SubClicking the cmdDoSomething button eight times in five minutes produced the graph shown in Figure 1, which shows the number of live connections on my otherwise unused server (vertical axis) against time (horizontal axis).
It's very clear from this trace that no connection pooling was taking place! Each request started a brand-new connection object that was closed when the request completed. A standard response is to believe that ADO connection pooling doesn't work and to change the code as shown here:
Dim cn As ConnectionPrivate Sub Form_Load()Set cn = New Connectioncn.Open "Pubs"End SubPrivate Sub cmdDoSomething_Click()Dim rs As New RecordsetDim dTime As Doublers.Open "select * from Authors", cndTime = TimerDoLoop Until Timer - dTime > 8rs.CloseEnd SubThis, of course, is the traditional approach of "hogging" a connection all through the application session-as you can see in Figure 2.
To make pooling
work, we have to apply Rob's Rule Number 1 of OLE DB session pooling: To keep a session pool alive, you must
maintain a reference to an ADO connection object for the lifetime of your
application. This connection does not need to be kept open.
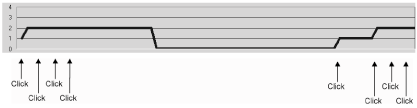
In other words, you need to "prime" the pool and then keep it live with a dormant connection object. In the following code, look carefully at how the Form_Load procedure creates and then closes a connection, but leaves the global variable intact, without setting it to Nothing. As you can see in Figure 3, this keeps the pool primed with an object containing the required connection properties.
Dim cn As ConnectionPrivate Sub cmdDoSomething_Click()Dim rs As New RecordsetDim dTime As Doublers.Open "select * from Authors", "Pubs"dTime = TimerDoLoop Until Timer - dTime > 8rs.CloseEnd SubPrivate Sub Form_Load()Set cn = New Connectioncn.Open "Pubs"cn.CloseEnd SubHere, the total number of connection requests was four, and we averaged about one connection over the five-minute period. It's a fact that ADO connection pooling prefers having two connections open rather than just one. For two-tier applications, you need to balance the connection cost over the lifetime of a typical application session. When the application is in use, it's quite likely that two connections will be live. However, in those long dormant periods, the pool will be empty. With ADO 2.5, it will be possible to control how long a pool keeps connections open. The default will be 60 seconds, but you'll be able to change this on a provider-by-provider basis. With current versions of ADO, you can't change the default.
You can also control whether or not your connection should be pooled by including "OLE DB Services" as a keyword in the connection string. A value of -1 ensures that pooling is enabled, -2 that it will be disabled.
Pooling differs in one big way when your code is running under MTS. This, of course, includes any ASP page or component running under IIS4. Rob's Rule Number 1 of OLE DB session pooling does not apply here because MTS provides its own resource pooling. Consider code for the simple ASP page:
<HTML><BODY><%set rs = Server.CreateObject("ADODB.RecordSet")rs.Open "select * from Authors",
"DSN=Pubs;"Response.Write "<BR>"rs.MoveFirstwhile not rs.EOFResponse.Write
rs("au_fname") & "
" & _
rs("au_lname") & "<BR>"rs.MoveNextwendrs.Close%></BODY></HTML>This uses a server-side connection to generate a Web page. Figure 4 depicts the trace that results if I simulate 10 concurrent requests for the preceding page-followed by the same burst of activity about two minutes later.
One trap that developers can fall into is believing that it makes sense to store connections or Recordsets in ASP session objects. This is rarely a good thing to do. By adding the following code into the Web page shown previously, the trace changes to the graph shown in Figure 5:
Set Session("rs") = rsCompare the different scale of the two graphs. This large number of connections will remain open until the ASP sessions time out.
When using ADO connections in an MTS environment, both resource pooling and session pooling are in use. By switching off the latter, you can explore the different ways in which the two technologies work. For example, for the graph on the right in Figure 6, I've changed the connection string to the following to disable session pooling:
rs.Open "select * from Authors",
"DSN=Pubs;OLE DB Services=-2"In both cases, I was testing low usage level, requesting the page once every 10 seconds.
Resource pooling doesn't have session pooling's habit of wanting at least two connections open.
As you've seen, ADO connection pooling is very easy to use and is generally safer and more efficient than any other tricks or techniques available for managing connections. Most of the problems experienced with connection pooling result either from code that's not releasing resources when it should, or from failure to keep a primed pool where it's needed.
There are some implications of pooling to be aware of. Connections coming from a pool might be used by other users (in n-tier applications), and there's no guarantee that you'll always get the same connection:
ADO connection pooling provides us with a "demand-sensitive" way of conserving connection resources while minimizing connection requests. When we use connection pooling, we should release connections as soon as possible. When resource pooling isn't available (via COM+ or MTS), it's important to prime a connection pool. Connection pooling can be a benefit both to standard desktop applications as well as n-tier DCOM and Web applications, and it also means that we can create standalone Recordset objects without the overhead of creating a new connection each time.
Download sample code in pooling.txt
Rob Macdonald is an independent software specialist who's based in London and southern England. In addition to consulting and training in Windows, client/server, VB, COM, and systems design and management, he also runs the UK ODBC User Group and is the author of RDO and ODBC: Client Server Database Programming with Visual Basic, published by Pinnacle. +44 1722 782 433, rob@salterton.com.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}