This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
January 2000
|
Active Directory Doesn't Just Manage Network Resources, It Can Manage Your Data Too
|
|
Shawn Wildermuth
|
| Microsoft has provided a convenient way to manage its own object models by using the Active Directory services. Active Directory promises to simplify the lives of system engineers everywhere by providing a distributed catalog of domains, users, computers, printers, groups, and so on. |
|
This article assumes you're familiar with Visual C++ and COM |
|
Code for this article: MSJADSI.exe (14KB)
Shawn Wildermuth is an independent consultant specializing in helping companies scale Web applications. He can be reached at http://swildermuth.ne.mediaone.net.
|
|
This article is based on Windows 2000 beta 3 and Release Candidate 1. Specific details of Active Directory may change once Windows 2000 is in commercial release. |
As developers, you are often encouraged to think in terms of objects. Object-oriented design and UML are both paths toward this goal. But when you get deep enough into design, you hit the roadblock of data storage. Typical databases do not look like hierarchical object models. Relational databases are used for persistence for most applications these days, but since it's difficult to think of databases in terms of objects, you probably resort to writing relational-to-object-model translations, or business objects. Wouldn't it be great if you could store data the way you think about it?
Luckily, Microsoft has provided a convenient way to manage its own object models by using the Active Directory™ services. Active Directory promises to simplify the lives of system engineers everywhere by providing a distributed catalog of domains, users, computers, printers, groups, and so on. It would be great if you could use this same facility to store your own hierarchical data—and you can.
Directory services are powerful tools, but to the uninitiated they can be a bit daunting. In the first part of this article, I will explain why and where to use directory services, specifically Active Directory. Then I will explain how to define your own objects in the directory. Also, I will walk you through an actual example of creating, searching, and retrieving your directory objects using the Microsoft® Active Directory Service Interfaces (ADSI), and how to search using ActiveX® Data Objects (ADO). Finally, I will explain how to take advantage of Active Directory in the world of Windows NT® 4.0.
Directory Services and Relational Databases
Directories have distinct roles and are not meant to replace traditional relational databases. Directory services have evolved from simple phone and e-mail directories to what you have today: large-scale object storage. And directory services have real benefits over relational databases, but these benefits come at a cost. I will start by explaining the differences between directory services and relational databases so you can make better decisions about when to use each.
Directories are tuned for reading. You must be aware of data volatility; directory services are not an appropriate place to store data that changes often or is time-sensitive. A limitation of directory services is that they cannot guarantee when the data that has just been written will be available. Therefore, systems that rely on reading data immediately after writing are doomed to fail if the data is stored in a directory service, which is better at storing long-lived, fairly static objects.
For an illustration of this, let's look at what Microsoft decided to put in the Active Directory services: Users, Groups, Printers, Computers, and so on. All of these objects have in common the fact that they are relatively static. Users probably only change their passwords or permissions occasionally. Printer names and default settings rarely change. The point is, the Active Directory services should be used to store objects that don't change often. Examples of other data types you could easily store in directory services include document repositories, alternate user databases (such as in Microsoft Site Server), product catalogs, and phone or e-mail directories.
Also crucial to the success of directory services is that they store data hierarchically. Storing data in this way allows you to create trees of related objects. This way you can have objects of different types living in different places within the hierarchy. To understand the directory mentality, look at the directory structure you use every day—file directories represent a standard method of displaying hierarchical data. Directories store files and folders, and folders can contain files and folders, but files cannot contain folders. This is classical hierarchical storage.
|
 |
|
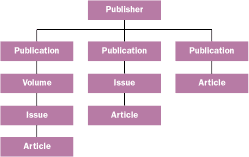
Figure 1 Publication Information Tree
|
Let's look at a more complicated example. Say you decided to store publication information—publishers, publications, articles, and so on—in a directory. You could store the publication information within a tree, as shown in Figure 1. Notice that the Article object can reside anywhere in the tree. If a particular publication uses the entire tree structure (Publication, Volume, and Issue), the Article will reside all the way down the hierarchy. On the other hand, if the publication is simply a book of unrelated articles or a one-time magazine issue, then the Volume and Issue are not needed. If this were stored in a traditional database, you would have to create a dummy Volume and Issue for the Article. But with directory services, this is unnecessary.
 |
|
Figure 2
|
Relational databases, on the other hand, are made to hold static structures that are defined in advance. They can write and read data at similar speeds, and the data is usually available immediately after being written. Relational databases were made to meet the needs of high-volume enterprise systems, and do a great job of showing one-to-one and one-to-many relationships. For example, the accounting tables shown in Figure 2 hold these types of static structures. The database maintains a direct one-to-many relationship between the Invoice table and the Invoice Items. There would be no need to store the Invoice Items directly under the Customer.
Lightweight Directory Access Protocol
Directory services have been around for years. They are primarily used for e-mail and phone systems, handling a hierarchical directory of all users in a particular organization's e-mail or phone system. With this goal in mind, the designers built monolithic systems that would handle the deluge of data they were to deliver and receive. X.500 OSI is still one of the major standards for building these directories. The problem with the X.500 interface standard is that the APIs are very complicated.
To address the need for a streamlined approach to interfacing with directories, a team at the University of Michigan came up with the Lightweight Directory Access Protocol (LDAP). This protocol allows you to modify and search known directories using a standard interface to retrieve information about directory objects and a simple query language for searching a directory structure. Later, it was realized that you could build whole scalable directories based upon LDAP alone. This is the basis of directory services in Windows®.
Within LDAP, each object is identified by two names: a relative distinguished name (RDN) and a distinguished name (DN). A DN consists of the RDN and all of its ancestors. For example, the RDN of an object could be cn=swildermuth, but its DN could be \c=US\o=Microsoft\ ou=members\cn=swildermuth. This DN represents a unique name across the directory service. This can be best illustrated via the file directory example described earlier. A file or folder name must be unique within a folder, but the uniqueness of the file or folder name is based upon the fact that the file or folder exists under a specific branch of the file system hierarchy.
You may have noticed that each RDN has an identifying moniker tacked onto the front of the name. This moniker is used to identify the category of the object. For example, the organization class uses the moniker o, so you can determine that the Microsoft object in the previous example is an object in the organization category. The most common moniker is the common name (cn). Most objects below an organizational unit in a hierarchy use this moniker. Figure 3 provides descriptions of the most common monikers.
Let's look at a full LDAP path:
|
LDAP://braves.com/c=us/o=timewarner/ou=braves/cn=tglavine
|
In this example, LDAP is the protocol (just like http:// or ftp://). braves.com is the domain or LDAP server. It may be appended with a port number like a standard URL. For example, LDAP://braves.com is just as valid as LDAP://braves.com:1005.
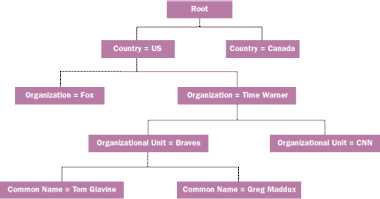
These elements are followed by a delimited list of RDNs that make up the DN. In other words, you are looking for Tom Glavine's object within the organization unit of the Braves that is located within the organization called Time Warner, that is located in the United States, and it all is stored in the braves.com domain. Figure 4 illustrates this object's hierarchy.
|
 |
|
Figure 4 Atlanta Braves Object Hierarchy
|
Keep in mind that the slash, backslash, and comma are all valid delimiters. In other words,
|
LDAP://braves/c=us/o=tm
LDAP://braves/o=tm, c=us
LDAP://braves\c=us\o=tm
|
are all semantically the same. You may also notice that in these different syntaxes the object order is reversed. With the formats based on slash or backslash delimiters, the objects are ordered from the top of the tree to the node; in the comma-separated style, the objects are ordered from them node to the top of the tree. The reversed order of the comma-delimited format is a convention, not a requirement.
Please be aware that the following characters are reserved and cannot be used with common or LDAP names: comma (,), /, \, +, =, ", <CR>, <, >, #, or ;. Spaces cannot begin or end a name and there can be no more than one sequentially embedded space within a name. With this in mind the following object names are not valid: "Smith, Mike", "A/P", "C:\file.me", "We're#1".
Active Directory Services
With the release of Windows 2000 Server and Advanced Server, Microsoft now offers an integrated solution to directory services via Active Directory services.
The Microsoft solution provides tools to use Active Directory for managing networks. Storing network resources in Active Directory lets you manage them across the enterprise. This is perfect for system administrators and engineers, but developers need a solution geared toward specific data storage problems.
In Windows 2000 Server, Microsoft changed the way
network domains are handled. Windows NT 4.0 used Primary Domain Controllers (PDCs) and Backup Domain Controllers (BDCs). The domain system information (users, groups, permissions, and so on) could only be changed on the PDC. Eventually the data was replicated to the BDCs, but there was no guarantee that the replication would happen in a timely manner.
With Windows 2000, there is no distinction between a server with Active Directory services and a domain controller. There are no longer PDCs and BDCs; either it's a domain controller or it isn't. Each domain controller can belong to a domain tree, and domain trees can also belong to domain forests. Trees and forests have trust relationships with each other and allow for secure data sharing within these trusted relationships. The domain forest also contains a global catalog—the Active Directory services—from which data is replicated (and optionally partitioned) throughout the forest. This allows for the directory services to be as far from the client as necessary.
This means any objects you store in the Active Directory services will be visible from any trusted domain, assuming the security rights are available. This is especially useful for directories that must be shared within an enterprise.
Let's get Active Directory working so you can take a look at the possibilities. I'll assume you are using Windows 2000 Server or Advanced Server as a domain controller. All of the examples shown here were tested with Windows 2000 Advanced Server, Release Candidate 1, Build 2072. You can find the documentation for installing the Active Directory services at http://www.microsoft.com/windows/server/Deploy/directory/default.asp. The Configuring Your Server wizard is also available to help you get started.
Security
Every object within Active Directory has an Access Control List (ACL) associated with it. All of the code in this article conveniently skirts the issue of security by letting the Active Directory services create default ACLs based on the logged-in user. This is fine for development, but please be aware that security in Active Directory is a serious matter. For instance, later you will see where I create new schema objects in Active Directory. Authentication to the domain must allow access to the schema. If not, no work can be accomplished.
This article is far too short to cover the Windows 2000 security model, even trivially. I suggest seeking other sources, such as Keith Brown's MSJ Security Briefs column, his Web site (http://www.develop.com/kbrown), or MSDN™ (http://msdn.microsoft.com).
Directory Objects
Let's look at some objects that Microsoft has defined: Users, Groups, and Computers. To access the Active Directory Users and Computers snap-in for the Microsoft Management Console (MMC), open MMC and create a new console. You will need to be in author mode to add a new console and snap-ins. You can set this by selecting Console from the menu and then choosing Options. From the Options dialog, select the console mode and author mode. Also, you will want to select Advanced Features from the View dropdown menu. Go to the file menu and pick Add/Remove snap-in. From there, click the Add button and select Active Directory Users and Computers snap-in. Don't forget to save this console; you will use it again later.
Figure 5 shows the Users and Computers snap-in. Notice that under twain.local (my domain), there are folders that contain different object types. I am going to concentrate on Users for this example. Select Users, and pick any user. I selected Administrator for this example.
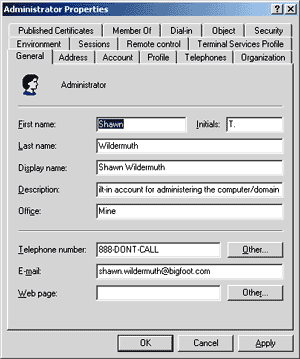
Notice the type of object shown in this list. This type really relates to object class. When you double-click on a user, you get a properties dialog, as shown in Figure 6. All of these items about a user are stored in the directory as attributes of the object. This type of object manipulation allows you to directly manage these objects without any real knowledge of how the data is stored, which is a very useful construct.
|
 |
|
Figure 6 Administrator Properties
|
The MMC provides a nice mechanism to write user interfaces for your custom objects. But before you start creating your own directory objects, you must first define a schema.
Directory Schemas
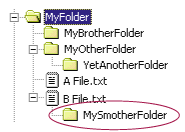
Directory services are much like the file directories in Windows. If you think of files and folders as two different object types, the hierarchical nature of the storage is quite simple. But notice that there are some rules about storage; a file can be located under a folder, and a folder can be located under a folder, but a folder cannot be located under a file. Figure 7 shows a simple file directory structure that violates the rules. Windows won't let you get away with this.
 |
|
Figure 7 Invalid Hierarchy
|
In addition, files and folders can have one of several attributes: read-only, system, hidden, and archive. There are also other, more obvious attributes such as name and extension. These relationships and definitions are called a schema. Each object in a directory is directly tied to an object type, and that object type must follow its own rules. Structural rules such as the allowed relationships between files and folders will also be described in the schema.
The schema consists of class definitions and attribute definitions. Within a class, you can specify what attributes you want to support, and you can classify attributes into two categories: optional and mandatory. Also, you identify where the class can live in the hierarchy. These rules are defined as attributes of the class object.
 |
|
Figure 8
|
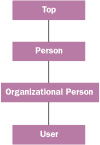
In the Active Directory services, classes follow a simple inheritance model. When defining a class, you must declare a parent class. This class defines what attributes are implicitly inherited from their parent class. Figure 8 shows an example of a class hierarchy. Notice that the class at the head of the hierarchy tree is an object called Top, and that this class is the only one without a parent.
When defining a new class, remember that each class must specify a class category and an object category. The class category describes how the class is to be used in the inheritance tree. The three valid choices for the class category are structural, abstract, and auxiliary. The structural class category allows a class to have instances in Active Directory. Structural classes are the only classes that can be stored within the directory. Abstract classes are used to define sets of attributes that may belong to a common set of classes, but are not creatable themselves. Auxiliary classes, on the other hand, are similar to include files in C. They define a set of attributes that can be attached to a class in order to add a specific set of attributes. In this way, the use of abstract classes and auxiliary classes provides a simple multiple inheritance model in the Active Directory services.
In contrast, the object category defines a base class association in the hierarchy tree that is used for cataloging and searching. Defining the object class allows for the Active Directory services to better index the directory to allow for faster searches. For example, the User object in Figure 8 has a simple derivation, but the object class of the User class is Person. This way, when cataloging people in Active Directory, the Users get cataloged along with all other people in the system.
Attributes, on the other hand, define data to be stored with the class. They are defined as entities themselves and may exist in one or many different classes. Attributes have a simpler model and have a relatively small number of components, and they require you to define several characteristics:
- The syntax (or data type)
- Minimum and maximum value
- Whether the attribute is multivalued (an array)
- Whether to index this attribute
- Whether to replicate this attribute
- Whether the attribute is required or optional
Object Identifiers
Classes and objects often reference an Object Identifier (OID), which is a unique numeric value that is usually issued by an organization such as ANSI or IDT. OIDs are a throwback to the days of LDAP and X.500. Each piece of a schema must be uniquely identified and must remain unique. In this way, OIDs are similar to GUIDs. The OID is made up of numbers and periods that describe a particular branch of the identifying tree. For example, the OID 1.2.840.113556.1.5.4 breaks down to:
- 1—ISO, the root authority
- 2—ANSI
- 840—USA
- 113556—Microsoft
- 1—Microsoft Active Directory
- 5—Microsoft Active Directory: Classes
- 4—Microsoft Active Directory: Classes: Built-in-Domain
To add a schema, you must obtain a root OID from which to build the schema (like 1.2.840.113556 for Microsoft). This is a complicated process that involves paying someone like ANSI a fee. Luckily, Microsoft helps you out by letting you use part of their OID space for your objects. Windows 2000 is expected to provide a utility called OIDGEN.EXE. This tool will generate two root OIDs that can be used for your own schema, one for classes and one for attributes. If you are developing against a version of Windows 2000 Server that does not include OIDGEN, (beta 3 and RC1 didn't), you can send e-mail to oids@microsoft.com and they will issue you a set of OIDs.
To view your schema, you must use another MMC snap-in, the Active Directory Schema snap-in. Unfortunately, this one is a little harder to find; it is included as part of the Resource Kit and must be installed separately. This article is based on Windows 2000 Server RC1, which did not include the Resource Kit. Fortunately, the beta 3 Resource Kit schema tools work with RC1.
Once the Resource Kit is installed, launch the MMC console you created earlier and add the Active Directory Schema snap-in. This will bring up the screen shown in Figure 9. Notice that the schema is broken down into classes and attributes. If
you double-click on a particular class, you'll see all its different properties. Figure 10 shows the properties for the User class.
|
 |
|
Figure 10 User Class Properties
|
Before you can start modifying a schema, you must tell the Active Directory service. To do this, right-click on the Active Directory Schema snap-in and pick Operations Master, then select "The Schema May Be Modified On This Server" checkbox.
At this point you may want to try adding a couple of attributes and classes interactively. This should be straightforward from the dialogs in the snap-in. Note that once you create a schema it cannot be deleted. Please do not take this lightly. I would suggest using a dummy or developer machine to test out your schema before corrupting your production domain server.
ADSI Basics
Microsoft has an API set called Active Directory Service Interfaces (ADSI). This should be your primary mechanism for changing objects and schema within the Active Directory services. The interfaces are script-friendly and highly optimized to reduce the number of network round-trips.
ADSI is a set of COM interfaces that allow you to access LDAP-compliant directories. ADSI has been available on Windows NT for some time, and if you have managed membership services in Site Server, you're probably already familiar with it. The ADSI object model is centered around IADs and IADsContainer interfaces. There are several objects that objectify common system objects, such as IADsUser, IADsPrinter, and IADsGroup. I will not be discussing these specific interfaces. Instead I will concentrate on the IADs interface.
The IADs interface is described in Figure 11. You get an IADs from an Active Directory path (ADsPath). For example, if the Tom Glavine object described earlier was a Users object, it's ADsPath would be LDAP://braves.com/CN=tglavine,CN=Users or LDAP://braves.com/CN=Users/CN=tglavine. Also, Active Directory supports a serverless notion of LDAP where the braves.com server designation is broken into tree nodes. In this case, both pieces (braves and com) are domain name identifiers. You can see this illustrated in the following snippet of VBScript code:
|
Set o = GetObject("LDAP://CN=tglavine,
CN=Users,DN=braves,DN=com")
|
Notice the GetObject call. Now that you have a node object (the IADs interface), you can look at that object's attributes by using the Get method. Conversely, you can change or add attributes (assuming they agree with the schema) via the Put method.
The IADs interface is designed to reduce the number of network calls the object has to make. To do this, it relies on the SetInfo method of the IADs object. This method is like a database commit call. All of the properties set for an object before this call are kept in a property cache in a proxy object. The flush to the actual directory storage is made along with the SetInfo call. Because of the latency of the SetInfo call, all validation is done at that time. Since there is no communication with the LDAP or Active Directory-based server until the SetInfo call is made, validation can't be handled on each Put. You should be aware that this complicates the debugging process.
The IADs object is great for getting a single object, but most often you will be retrieving the container or top of your particular hierarchy. To make creating new objects and navigating through containers within the hierarchy an easier task, ADSI provides the IADsContainer interface, which I'll take a closer look at later.
Here is a simple VBScript example where you can see how the IADs interface is used. It simply adds a phone number for every user:
|
Dim UsersObj, UserObj, phone
Set UsersObj = GetObject("LDAP://CN=Users,
DC=twain,DC=local")
' Put in the Company Telephone Number in All Users
' if Blank
For Each UserObj In UsersObj
' if it is a user
If UserObj.Class = "user" Then
UserObj.Put "telephoneNumber", "212-555-1212"
UserObj.SetInfo
End If
Next
UsersObj = Nothing
|
Notice that the code uses the For Each VBScript construct. This gets the UsersObj's IADsContainer interface and gets the IENUMVariant interface from the IADsContainer interface's get__Enum method. VBScript hides this complexity from you, but later you'll see this done explicitly in C++ code when displaying objects you've created.
The IADs interface manages objects easily and is not tied to any particular object class. IADs support specialized interfaces to handle Users, Groups, Computers, and so on. I will not be covering those interfaces.
All of the code in this article has been written with the ADSI 2.5 SDK. This is the version installed by default with Windows 2000. When writing C++ code, you will need to link with the lib files and the newer headers that are delivered with this SDK. Also, the SDK comes with a debugging utility called ADSVW.EXE, which is very useful for debugging ADsPaths and LDAP queries. It allows you to look at the directory natively through LDAP, not through the Active Directory services. The SDK is available from http://www.microsoft.com/windows2000/library/howitworks/activedirectory/adsilinks.asp/.
Adding Schema Extensions
Now it's time to design the objects. For this example I will create a publishing hierarchy model containing a Publisher, a Publication, a Volume, an Issue, and an Article. Figure 12 outlines my new objects and their attributes, identities, and rules.
The first thing to notice is that the common name (cn) for all the objects starts with a common prefix, MSJ-. Microsoft is attempting to thwart the problem of common name collision by suggesting naming conventions for common names and LDAP display names. The suggested common name standard is made up of an abbreviation of your company name (MSJ for Microsoft Systems Journal), an abbreviation of the product space (DR for Document Repository), and the object type. The LDAP display name is similar, but usually the first letter of any LDAP display name is a lowercase letter.
In addition, the LDAP display name often removes extra hyphens and combines a product space and description into one section. If you do not specify the LDAP display name, Active Directory will generate one by removing all hyphens and uppercasing all letters that used to follow the hyphens. This makes the LDAP display names fairly unreadable, so I recommend specifying the LDAP display names yourself to ensure their readability. You will notice that some of the attribute values in Figure 13 are bold. These signify new attributes that I'll create as well.
The PublicationItem class is designed to hold all the common attributes for the publication classes. You can accomplish this in one of two ways: create an abstract class that defines these attributes or create an auxiliary class that holds the attributes. I decided to create an auxiliary class because I did not want to worry about the parent of the classes or imply that there was some parent relationship with these items. It also allowed me to use a built-in class for my parent (in this case, container).
Notice I am enforcing a hierarchy, but it is a loose one. The Possible superiors class characteristic tells Active Directory where the class can be contained. This allows you to design the directory to manage its own hierarchy.
You really have four options for updating the schema with my new attributes and classes. First, use the MMC snap-in interactively and add in all the schema items, attributes, and classes. Second, you could write code to add in the schema. Third, you could use a comma-separated value file (CSV) that contains your entire schema and use the Microsoft CSVDE command-line utility to install the schema. Fourth, you can use LDAP Data Interchange Format (LDIF) scripts to update the schema. CSV has an advantage over LDIF in that CSV supports Unicode and LDIF does not. Approaches two through four are useful if you need to update the schema on multiple servers or within the install of a shrink-wrapped product. I will not cover these options, but Microsoft has a good example of them, which you can find at http://msdn.microsoft.com/library/psdk/adsi/glschema2_9s4z.htm. Here, I'll assume that you've added the schema interactively.
The wizard that Microsoft provides for adding attributes and classes does not have some of the characteristics that you'll want to set. To fill in these attributes and classes, add them with the wizard and then go back and double-click the object to edit other characteristics.
Creating New Objects
It's time to write some code. My sample Visual C++®-based project, called MSJADSI, can be downloaded from the link at the top of this article. This project includes examples of creating new objects, searching for objects, and retrieving data from my projects—all utilizing the Publisher's object hierarchy.
Now that the schema has been defined, creating the new objects is relatively simple. The first thing you need to do is get the container object that will hold your objects. Get the domain object and create a top-level container object to hold all of your hierarchies, in this case the Active Directory root address (LDAP://twain.local). The code that adds these items can be found at the link at the top of this article. I didn't use the scriptable IADsContainer for creating my objects. Two interfaces in the ADSI interface collection are not scriptable (in other words, they're custom-only interfaces): IDirectoryObject and IDirectorySearch. Here, I used the IDirectoryObject interface and some ADSI functions at my disposal.
Now you need to get an instance of this directory (CMSJADSIDlg::OnBtnOpenContainer). There are three methodologies here. You can use the ADsGetObject function to get the interface with standard security credentials. Alternatively, you can use the ADsOpenObject to specify your credentials. Finally, you can QueryInterface from an earlier received IADsContainer object. All three approaches are equally credible as long as the security model will
get you the rights to the required objects.
Now that you have an IADsContainer object, you can create the root object (CMSJADSIDlg::OnBtnCreateObjects). First, you need to get an IDirectoryObject interface. To do this you QueryInterface the IADsContainer interface you received before.
To create your root object (CMSJADSIDlg::AddDocRepo), set up an array of attributes for the object. This array is of the ADS_ATTR_INFO type. ADS_ATTR_INFO specifies a structure of type information that ultimately points to individual ADSVALUE structures. The code is a lot simpler than it looks. Once the array (ADS_ATTR_INFO) is defined, you can set up the ADSVALUE with their appropriate values to complete the attribute array. At this point,
call the CreateDSObject on the IDirectoryObject interface to complete the object. This call fills in an IDispatch pointer, so you must QueryInterface an IADs interface if you
need to use the object again. In this case you don't need to reuse the object, so simply release the IDispatch pointer.
Here is where it gets a little tricky. All the objects must be created with IDirectoryObject pointers that point to the containing object for your objects. So in this case, when you create the root object, you QueryInterface for the IDirectoryObject of the root object so the next set of objects will be created under the root object. This behavior continues down the line of objects that you are creating. When you're finished running through the objects, you end up with the hierarchy shown in Figure 13. The ADSIEdit MMC snap-in provides you with editing capabilities of the entire Active Directory services. This is at a low level and does not provide you with any object-specific user interfaces. However, the snap-in is very useful in debugging your objects and system objects when you want to look at all attributes that the traditional MMC snap-ins hide from view.
How do you get access to the hierarchy of objects so you can manage or modify them? Some simple IADs interface code that iterates through the publishing hierarchy takes care of it (see Figure 14). Opening existing objects is quite simple if you know the DN, much like knowing the full path to a file. If you know where to find it, then it gets really simple to open the file.
Using a recursive function, the code takes a container and uses its IENUMVariant interface to get all the objects within an IADsContainer object, and simply writes out the description and name to the log window. Now comes the interesting part. The code gets the schema object for the item and checks to see if it is a container object as well. The criteria for a container object is that it can parent other objects. If the schema object turns out to also be a container object, then you send it back into the recursive function to list all of its members.
Searching
Unfortunately, in most cases you don't know where your object exists in the hierarchy. With ADSI and LDAP, however, it's simple. To search a branch of Active Directory, you simply need to use the IDirectorySearch interface to do an LDAP query. The biggest hurdle in getting all of this to work is learning the new search language that LDAP uses. The most common LDAP queries take the form:
|
(&(cn=Administrator)(objectClass=user))
|
This query is made up of two criteria (cn and object class) placed within parentheses and an operator that encapsulates it all within another set of parentheses. The & character signifies an and clause. So in effect, this query is asking for an object with the common name of Administrator and the objectClass of user. The parentheses are used for grouping. This should become clearer as I discuss the code.
Figure 15 uses the new IDirectorySearch interface. Please be aware that I'm using this interface in C++ because it is only available to early-bound languages (C++, Visual Basic, Java, and so on). Scripting languages cannot use this interface at all. Later, I'll discuss how to search in scripting languages by using ADO with the ADSI provider.
The IDirectorySearch interface works by allowing LDAP queries to be sent to the server while recordsets or the like are returned. Let's walk through this particular code. First, you QueryInterface the IADsContainer object to get your IDirectorySearch object. Next, set up a search preference. Search preferences include characteristics such as timeout, maximum rows returned, asynchronous or not, and (in this case) the search scope. Tell the IDirectorySearch object that you want to search your current node and the entire subtree below. Since you're looking for objects you've just created, the entire subtree is accurate. If this is not the case, you can set the preference to search this object only one level down the tree.
Next, you execute the search. The code retrieves the search criteria from an MFC dialog, so you will not see any particular criteria specified here. If you download the code, you will notice that I have defaulted the search to:
|
(&(objectClass=mSJ-DRArticle)(cn=Intel Chips))
|
This search criteria tells the server to look for an object that has the class of mSJ-DRArticle and the name of Intel Chips. We could use the | character to signify an or operation, instead of the & character used for an and operation. Be aware that in this syntax the * character is a wildcard. Also note that substring searches do not seem to work for objectClass, though it seems to work fine for ou and cn. The following search would find all your objects:
|
Once you've executed the search, you'll go through each row and get the requested columns. The row and column objects are like recordset field objects, but getting this information is more difficult than in traditional database recordsets. Most of the time you use the search capabilities, you will simply get the ADsPath property of the searched objects; so you can call GetObject on the ADsPath and perform whatever work you need to do with the objects.
ADSI and ADO
ADO, the Microsoft database access layer, uses a provider paradigm to specify how objects will query their data. With this in mind, Microsoft created a provider to fill in
a gap in ADSI and to provide new functionality at the
same time. With ADO, you can query Active Directory using SQL syntax.
|
SELECT cn, ADsPath, description
FROM LDAP://twain.local/cn=users
WHERE objectClass = "user" AND cn = "a*";
|
This is helpful for those who have invested time in learning the SQL syntax, and will shorten the learning curve for querying Active Directory. The other benefit in using the ADSI provider with ADO is that you can (and are required to) use ADO from scripting languages if you need to query Active Directory. You probably realize by now that by using the IDirectorySearch interface, you were tied to an early-bound COM language (Visual C++, Visual Basic, and so on). Scripting languages have no access to the IDirectorySearch interface, but do when using the ADSI provider for ADO.
What About Windows NT 4.0?
At this point you may be thinking, "This is all fine and good for the future when everyone will be running Windows 2000, but what about now? I have to ship products for Windows NT." Most of the solutions here are available for Windows NT, but only through third parties. Companies like Novell, Netscape, and others offer directory servers. Most of what I have discussed here is LDAP-compliant.
Windows 2000 provides some real benefits in an enterprise-wide global catalog to store your objects, but if you can live without these benefits, most directory servers will do an adequate job in maintaining your objects. In fact, most of what I have described here started with Site Server 4.0 and its LDAP server. There are some exceptions to this. The Active Directory services introduces the concept of auxiliary classes, which does not exist in other LDAP implementations I have used. In other implementations you would have to create the classes with all the attributes you need, without regard to using similar objects.
It is important to point out that Active Directory is a server component. This means that the client can always be Windows 2000, Windows NT, or Windows 9x. The ADSI and ADO SDKs work fine with these clients. The Active Directory services can be used within a mixed domain of Windows NT and Windows 2000, but the replication is limited.
Conclusion
The Active Directory services will not design your systems for you or provide an instant replacement for relational databases, but it does solve a particular problem: long-term storage of fairly static objects in hierarchical storage. Active Directory services provides an enterprise solution for sharing a global catalog of information and tools to manage that information. The ADSI interfaces provide a way of managing your directory objects in a simple yet robust way.
Now you know when to use directory services. I've shown you how to define, create, search, and retrieve your own directory objects. And you have discovered that using the Microsoft ADSI interfaces simplifies the interaction with directory services. You've also learned how to use the ADO Active Directory Service Provider to query data from your directory in SQL. Finally, you have seen that using directory services is not limited to Windows 2000. There are usable solutions in the Windows NT 4.0 world that provide many of the same benefits as Active Directory.

|
From the January 2000 issue of Microsoft Systems Journal.
|