FOCUS
Which is Faster: Index Access or Table
Scan?
Use these tips to get the best performance from your
database
It can be difficult to determine whether a table scan or an index will provide better query performance. The answer depends, in part, on the percentage of rows returned, but another important factor is whether you use a clustered or a nonclustered index. The SQL Server 7.0 query optimizer doesn't always choose the fastest method. I've done some testing to determine when to second-guess the optimizer, and I share my conclusions here.
Index access is an access method in which SQL Server uses an existing index to read and write data pages. Because index access significantly reduces the number of I/O read operations, it often outperforms a table scan.
In a table scan, SQL Server sequentially reads the table's data pages to find rows that belong to the result set. SQL Server 7.0's use of Index Allocation Map (IAM) pages significantly increases table scan performance. (For more information about IAM pages, see Inside SQL Server, "The New Space Management," April 1999.) SQL Server 7.0 reads IAM pages to build a sequential list of disk addresses, which lets the database system optimize I/O performance when it uses large sequential read operations. In earlier releases of SQL Server, data pages are in a double-linked chain and SQL Server reads each page individually to move the pointer to the next page, resulting in a series of single-read operations.
When you use the NONCLUSTERED option in a CREATE INDEX statement, you specify a nonclustered index (it's also the default). A nonclustered index has the same index structure as a clustered index, but with two important differences. Nonclustered indexes don't change the row's physical order in the table, and the nonclustered index's leaf level consists of an index key plus a bookmark.
Generally, a bookmark shows where to find the row that corresponds to the nonclustered index key. The bookmark of a nonclustered index key can have two forms, depending on the table's form. If a clustered index exists for other columns of the table, the nonclustered index's bookmark points to the b-tree structure of the table's clustered index. If the table doesn't have a clustered index, the bookmark is identical to the row's Relative Identifier (RID).
SQL Server uses a nonclustered index to search for data in one of two ways. If you have a heap (a table without a clustered index), SQL Server first traverses the nonclustered index structure and then uses the row identifier to retrieve a row. If you have a table with a clustered index, however, SQL Server traverses the nonclustered index structure, then traverses the index structure of the table's clustered index. When SQL Server uses a clustered index to search for data, it starts from the root of the corresponding b-tree structure and usually after three or four read operations, it reaches the leaf nodes where the data is stored. For this reason, traversing a clustered index's index structure is usually significantly faster than traversing the index structure of the corresponding nonclustered index.
From this information on table scans, index access, and clustered and nonclustered indexes, you can see that answering which access method is faster isn't straightforward. One of the most important factors to determine whether an index provides better query performance than a corresponding table scan is SQL Server's choice between a clustered and a nonclustered index.
The following examples use the orders table in the Northwind database, but for performance reasons, I slightly modified the table. First, I use only a subset of the original table's columns because you don't need all the columns in the orders table for this example. Second, you need to increase the number of rows in the table to show any significant differences between the performance of the different types of operations. Listing 1 and Listing 2, page 42, show the queries to create and load the table, respectively.
You first create the nonclustered index with the following Transact SQL (T-SQL) statement:
CREATE INDEX i_orders_orderid ON orders(orderid)For the second test, you first drop the existing nonclustered index, then create the clustered index with the following T-SQL statements:
DROP INDEX orders.i_orders_orderid
CREATE CLUSTERED INDEX c_orderid ON orders(orderid)My tests show that a table scan often starts to perform better than a nonclustered index access when at least 10 percent of the rows are selected. I also found that the optimizer switches from nonclustered index access to table scan prematurely (i.e., when nonclustered index access still shows better response time than the corresponding table scan). In many cases, the optimizer forces a table scan for queries with result sets of approximately 5 percent, although the table scan becomes more efficient than index access at selectivities of 8 to 10 percent.
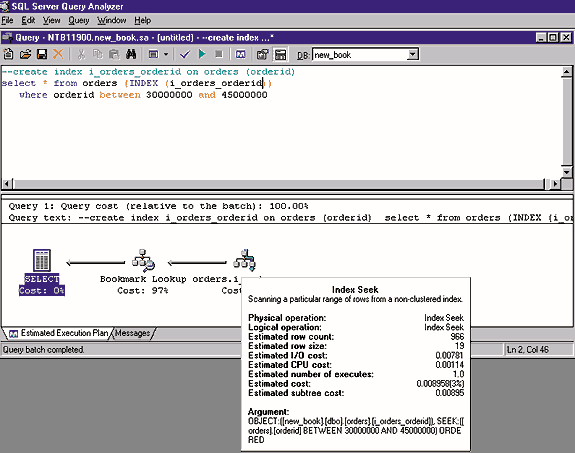
You can use the INDEX query hint to improve performance. (SQL Server supports several query hints that you can use to force the optimizer to use a particular index.) The T-SQL statement with the INDEX(i_orders _orderid) query hint forces SQL Server to use the existing nonclustered index i_orders _ orderid, as Screen 2 shows.
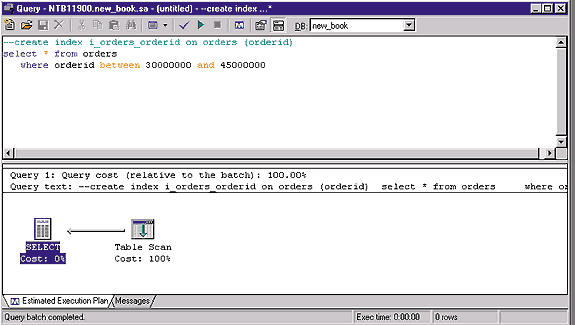
Screen 1 shows the execution plan with the table scan; Screen 2 also shows a typical execution plan for the nonclustered index with the Bookmark Lookup step. (Recall that a nonclustered index's leaf level consists of an index key plus a bookmark that shows where SQL Server has to look to find the row corresponding to that key.) The optimizer first uses a table scan; after I applied the INDEX query hint, it used the index access. The selectivity of both queries was approximately 10 percent.
The response time of the query that executes by using the indexed access was slightly better than the other query's response time. The optimizer decided to perform the table scan although SQL Server defined the nonclustered index, as Screen 2 shows.
For these reasons, you can expect a clustered index to perform better than a table scan even when selectivity is low. (Low selectivity means that the percentage of returned rows is high.) My tests confirmed the assumption that when selectivity is 75 percent or less, a clustered index access is faster than a table scan. However, my tests showed that the optimizer continues to use clustered index access in the cases where selectivity is greater than 75 percent.
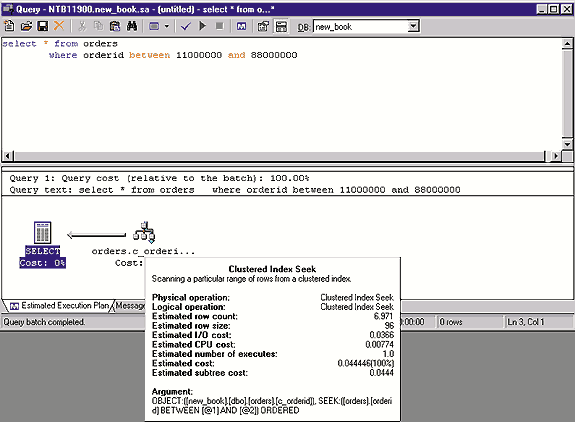
Screen 3 shows the query that has about 80 percent selectivity. Although my tests show that this query's table scan performs slightly better than the corresponding clustered index access, the optimizer chooses the existing index. Therefore, if you have an existing clustered index and selectivity of a query that uses the index as 75 percent or more, I recommend that you test to determine whether a table scan will perform better than clustered index access. If the table scan performs better than the corresponding clustered index access, use the INDEX(0) query hint to deactivate clustered index access and force the use of a table scan instead. The following T-SQL statement forces the use of a table scan for the query in Screen 3:
SELECT * FROM orders (index (0))
WHERE orderid BETWEEN 11000000 and 88000000Generally, the query optimizer chooses the fastest execution plan, but the optimizer isn't perfect. For frequently used and complex queries, you need to test within specific selectivity ranges to determine whether the optimizer's decision is correct. For a clustered index, if the query's selectivity is greater than 75 percent, compare the index access and table scan execution times to see which is faster. For a nonclustered index, compare the nonclustered index access and table scan when the query's selectivity is between 5 percent and 10 percent to see which is faster. You'll find these tips will help you achieve the best performance from your database system.
SQL Server Magazine
Bugs, Comments, Suggestions Subscribe
Copyright Duke Communications Intl, Inc. All rights reserved.
{kind=link}
{kind=link}
{kind=link}