|
Scalable, distributed applications support large numbers of clients by servicing their requests concurrently using a group of servers. To minimize response time and maximize use of processing power, client work should always be submitted to the server that is currently least busy. Deciding which server to send work to must be done at runtime, and the process of making this decision is called load balancing. Microsoft® AppCenter Server is scheduled to include Component Load Balancing (CLB) among its runtime services. CLB complements the two clustering features of Windows® 2000—Network Load Balancing (NLB) and Windows clustering—by addressing load balancing on the middle (business logic) tier. The first part of this article will explain how the new CLB service works, and the second part will show you how to implement it for use with COM and Microsoft Transaction Server (MTS) today.
Architecture
|
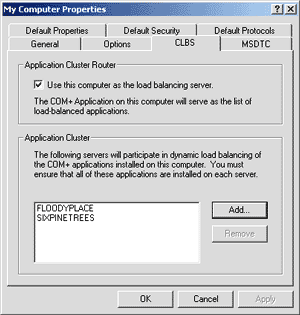 |
| Figure 1 CLBS Options |
|
You also have to give the CLBS a list of servers to forward object creation requests to. You can do this by adding more hosts to the listbox at the bottom of the same property page. This collection of servers is called an application cluster, and there is no documented limit to its size. The CLBS machine is always included in the cluster and cannot be removed, so it must be prepared to create objects locally. These simple changes have a profound impact on the behavior of the CLBS. In addition to running RPCSS (the service that houses the SCM), the CLBS will run COMLBSVC, the load-balancing service. The load-balancing service maintains a list of usable servers in shared memory, and the SCM consults this list to decide to which server it will forward a given object creation request. The list of servers is kept sorted and to keep the impact on creation time to a minimum, the SCM always tries to use the top-ranked, least-busy server. If the request for creation fails for some reason, the SCM will switch to another server instead. The load-balancing service continually updates the ordering of servers on the list to reflect the current load of the target machines, as shown in Figure 2. |
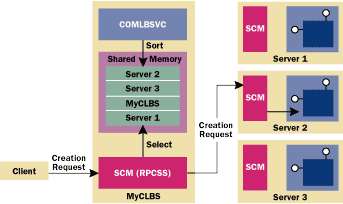 |
| Figure 2 Component Load Balancing Architecture |
|
Configuring Classes
In order to keep its server list sorted, the load-balancing service needs to know the load on each server in the application cluster. This information is gathered via interception. Recall that calls to objects running in the COM+ environment can be pre- and post-processed by a runtime-provided interceptor, otherwise known as the stub. Under MTS, the interceptor tracked how many calls into objects of a given class were currently in progress. COM+ extends this functionality and collects method-timing data as well. The load-balancing service on the CLBS creates a thread for each server in the application cluster and the threads harvest timing data by periodic polling. A little NetMon work in a simple three-machine test environment shows this happening roughly 25 times per second (or one update every 40 milliseconds). Figure 3 shows this architecture. How the data is maintained on each server and how the load-balancing service accesses it are undocumented. |
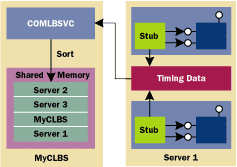 |
| Figure 3 Method Timing Architecture |
|
Timing all method calls to all objects would be expensive, so COM+ allows you to configure this behavior on a per-class basis. You can do this by checking the "Component supports events and statistics" checkbox on the Activation page of the selected class's property pages in Component Services Explorer. Data on calls into instances of classes configured with this option will be displayed in the Explorer at runtime. To keep the Component Services Explorer backward-compatible with the MTS Explorer, this option is turned on for all classes by
default. Whether this data is used for load balancing is a separate option, controlled by the "Component supports dynamic load balancing" checkbox on the same property page (see Figure 4). Once this option is set, timing data for calls to instances of the class will be aggregated into the machine-wide data and returned to the CLBS when it is requested by the load-balancing service. |
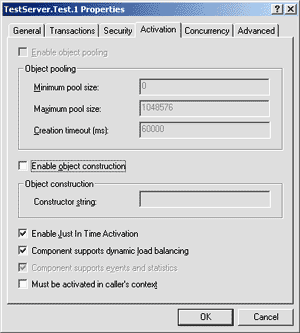 |
| Figure 4 Supporting Load Balancing |
|
After you've set up an application with classes that support load balancing, you need to install it on the servers in the application cluster, including the CLBS. Once they're deployed, you shouldn't reconfigure the declarative settings for classes on individual servers. The CLBS views the servers in the cluster as duplicates of one another, and if you modify the behavior of one or more of their classes you may get some unexpected results. For example, if you change the access permissions on a class on a single server, a given client may not be able to use an instance of the class depending on whether the CLBS forwarded the creation request to that server or to another server.
Configuring Clients
|
|
|
This code shows a client using a COSERVERINFO structure to target the CLBS explicitly. You can also set a RemoteServerName entry in the registry, or use any number of other techniques, including installing a client application proxy generated by exporting the desired application from the CLBS. As is always the case, once an object is created and a reference returned to the client, the SCM steps out of the picture and further client communication goes directly to the object (and the interceptor, which is measuring method invocation times). That's it! COM+ load balancing is now working hard for you—assuming, of course, that you're already deployed on Windows 2000 and are using AppCenter Server.
What about COM and MTS?
The Basic Idea
|
|
|
Notice that this implementation stores a CLSID as a data member so that it can be used with any number of classes dynamically. CreateInstance is the workhorse method of ClassObjectShim, shown previously. Here's its implementation: |
|
| If an implementation of this class object were registered for a given CLSID, it would forward the creation request to SomeServer. All that's needed to achieve this is a simple executable server. Here's an example: |
|
|
If this executable were pre-started on a server, MyCLBS, all client requests to create Balanced objects would be serviced by the instance of ClassObjectShim initialized with CLSID_Balanced. Based on the implementation of CreateInstance shown previously, the requests would be forwarded to the SCM on SomeServer and serviced there locally, as shown in Figure 5. If the Balanced class was registered on MyCLBS and the LocalServer32 key pointed to the LoadBalancer.exe shown in the previous code, the server would auto-start as well. This implementation is slightly slower than the mechanism in COM+ because an extra LRPC call from the SCM on the CLBS to the COM server providing the forwarding class objects is necessary. But this is a small price to pay for a load-balancing infrastructure that works with MTS. |
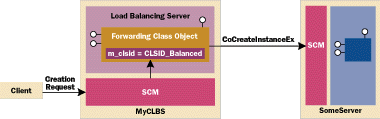 |
| Figure 5 Shim Class Object Architecture |
|
The Problem with CoCreateInstance
If clients create objects by calling CoGetClassObject and IClassFactory::Create-Instance, the approach I just outlined works great. For example, this client code will end up calling to an instance of Balanced running on SomeServer: |
|
| If, however, the client code were rewritten to use CoCreateInstance[Ex], it won't work. |
|
|
Unfortunately, the current implementation of CoCreateInstance[Ex] doesn't support returning an object reference to an object living on a server other than the one targeted by CoCreateInstance[Ex]. In other words, if a client on a user's machine calls CoCreateInstance[Ex] with the remote server name MyCLBS and the class object running on MyCLBS attempts to return an interface pointer to an object it created on SomeServer, the client's call will always fail and return RPC_E_INVALID_OXID, "the object exporter specified was not found." An OXID is a machine-relative identifier of an apartment in which objects live. When an interface pointer is marshaled for transmission between contexts, it's represented by a low-level data type called an OBJREF, which is context-neutral and can be passed on the wire. Most objects rely on the standard COM marshaling plumbing to do the right thing when their interface pointers are passed between contexts. When their interface pointers are marshaled, the resulting standard OBJREF includes their OXID, as shown in Figure 6. When an OBJREF is unmarshaled into a destination context, the receiving machine translates the OXID into a set of RPC string bindings by calling back to the machine where the OXID exists, the address of which is also encoded in a standard OBJREF. The string bindings can be used to build an RPC binding handle that can be used to make remote calls back to the OXID's process on the original machine. |
 |
| Figure 6 A Standard OBJREF |
|
The server side of CoCreateInstance[Ex] (it is a cross-context call) checks to ensure that the OXID in the OBJREF it is returning is valid on the machine where it is executing, which is also the machine that the client originally targeted with its call. If the OXID isn't on that machine, CoCreateInstance[Ex] complains it is invalid, hence RPC_E_INVALID_OXID. While there are undoubtedly good reasons for the implementation to work this way, it feels incorrect to the COM philosopher because all object references should be equal. Since it is valid for a class object to return an object reference from another context on its own machine (this is how you do round-robin single-threaded apartment thread pools in MTS, ATL, and Visual Basic®), it should be able to return an object reference from a context on another machine. But it can't, and this fact isn't going to change any time soon. This wasn't a problem when a client used CoGetClassObject because that method returned an object on the machine the client called. Unfortunately, the vast majority of COM clients are written using CoCreateInstance[Ex], or new in Visual Basic, the Java language, and scripting languages, so the fact that CoGetClassObject works is largely irrelevant. Bearing in mind that I didn't want to modify client code, I turned to the Academy of Motion Picture Arts and Sciences for a solution.
The Envelope, Please
|
|
|
I modified my special class object's implementation of CreateInstance to hide the object it wants to return in an envelope it creates locally, as shown in Figure 7. If the envelope used standard marshaling, CoCreateInstance would succeed because the envelope lives in a context on the machine the client called. Clients, however, would end up with references to objects of the wrong type (envelopes) running on the wrong machine, in this case the CLBS. What clients want, of course, is a reference to the underlying object (the letter) running on the ultimate destination server, SomeServer. This can be achieved through the use of custom marshaling. |
 |
| Figure 8 A Custom OBJREF |
|
The first thing the remoting layer does when it attempts to marshal an interface pointer is check to see if the object implements custom marshaling by calling QueryInterface and asking for IMarshal. If the object implements this interface, the remoting layer delegates to it the task of writing its context-neutral OBJREF. The format of a custom OBJREF is shown in Figure 8. The envelope could custom marshal and carry as its payload the standard OBJREF for the remote object living on SomeServer, as shown in Figure 9. |
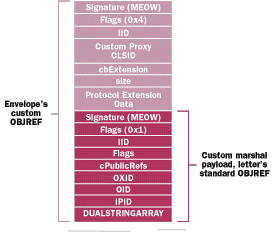 |
| Figure 9 Envelope's OBJREF |
|
If the envelope uses custom marshaling, CoCreateInstance will still succeed because it only checks OXIDs for standard-marshaled OBJREFs, but clients will still end up with objects of the wrong type (that is, envelopes), although now they'll be running inside the clients' processes. This problem can be solved using some clever sleight-of-hand. When an object custom marshals, the remoting layer asks it for a CLSID identifying a class that is capable of interpreting the payload it will write into the custom OBJREF. When a custom OBJREF is received in a destination context, an instance of this class is instan-tiated and asked to interpret the data and return a reference to an object. While it is often the case that the object interpreting the custom payload returns a reference to itself (typical when implementing marshal-by-value), this isn't a requirement. The object doing the unmarshaling can return a reference to any object it likes, and therein lies the key. If the envelope custom marshals, when it unmarshals back in the client's process, it can strip itself away simply by unmarshaling the standard OBJREF it hid in its payload and then return a reference to the resultant proxy for the real remote object. This is why the IEnvelope interface shown previously uses a write-only property. (I always wondered if there would ever be a legitimate use for such a thing.) There's no need for a propget method because the envelope opens itself. An ATL-based envelope implementation is shown in Figure 10. Notice that the class implements both IEnvelope and IMarshal. Also note that it stores a reference to the real remote object as a data member, m_pUnk, which is initialized via a call to put_Letter. The envelope returns its own CLSID in GetUnmarshalClass to indicate that another instance of this class will interpret its custom payload. In GetMarshalSizeMax and MarshalInterface the envelope uses the marshaling APIs to delegate to the letter, which standard marshals, so it will write a standard OBJREF as the custom marshal data. In UnmarshalInterface, which is called in the client process when the envelope is returned from CoCreateInstance[Ex], the envelope unmarshals its payload and returns a reference to the resultant object, in this case a proxy that refers to the real remote object, wherever it runs. Making the envelope trick work requires registering the envelope class on the CLBS machine and on each client machine. This is an additional burden, but a very cheap price to pay for making CoCreateInstance[Ex] work with the forwarding class object. Actually, there is one additional cost. The custom marshaling interface IMarshal includes the method ReleaseMarshalData, which is called by the remoting architecture if it fails to unmarshal the custom payload in the receiver's context. This method call gives a custom-marshaling object a chance to clean up any extant server-side resources. If, for instance, an object was custom marshaling using sockets to pipe data, this would give the object a chance to close the socket it set up in MarshalInterface. Unfortunately, with objects that marshal-by-value (like the envelope), this method isn't called because the server-side copy of the object has already been destroyed. For most marshal-by-value objects this is not a big deal because they don't carry references to objects. But the envelope does carry an object reference, and if it fails to unmarshal, the reference will leak. Luckily, the COM garbage collector will kick in and clean up these leaked references within six minutes, so this shouldn't be a problem.
Algorithms
|
|
|
Assuming there is a precreated instance of an implementation of this interface, the forwarding class object's CreateInstance method can be rewritten as shown in Figure 11. It is up to the specific implementation of ILoadBalancingAlgorithm to decide how to implement CreateInstance. Given a list of available servers (m_rgwszServers) and a count (m_nCount) as data members, a random algorithm could be implemented this way: |
|
|
The implementation of the round-robin algorithm is similar, but I really wanted COM+-style load balancing, so the algorithm I wanted was method timing. Remember that on Windows 2000, method timing is built into the interceptors that wrap each object executing in the COM+ runtime environment. Achieving the same thing on Windows NT 4.0 requires reaching deep down into the COM bag of tricks.
Timing Methods
|
|
|
which it stores in thread local storage (TLS). Whenever a call comes into the server, the channel hook's ServerNotify method is called. It creates a new CALLINFO structure, initializes it with the current time and causality (in essence the logical thread ID, which is available to channel hooks under Service Pack 4) and adds it to the stack in TLS. Whenever a call is about to leave the server, the channel hook's ServerFillBuffer method is called (actually ServerGetSize is called, but because it specifies a nonzero size, ServerFillBuffer is called). The ServerFillBuffer implementation pops the top CALLINFO off the stack and searches the remaining nodes to see if there is another CALLINFO with the same causality. If it doesn't find one, the CALLINFO it just popped off the stack represents a top-level call, so ServerFillBuffer calculates the difference between the CALLINFO's tStart time and the current time and aggregates this data into two global variables, g_nCount and g_nTime (more about these later). If ServerFillBuffer does find a CALLINFO with a matching causality, the one it just popped off the stack represents a nested call, so it is ignored. The time the nested call took to complete will be automatically included in the time it took its top-level call (represented by the CALLINFO with the same causality deeper in the stack) to complete. For this implementation of method timing to work, the channel hook has to be loaded into a server process. Since I didn't want to make any changes to server code, I opted to load the channel hook via a proxy/stub DLL. This does require a minimal amount of work; proxy/stub code has to be linked against some additional code that provides a new DLL entry point called NewDllMain (see Figure 13). NewDllMain creates an instance of a class called Loader, which is implemented by the channel hook DLL. Creating the object causes the hook DLL, which must be registered on any machine where the proxy/stub DLL is registered, to load. In its implementation of DllMain, it creates and registers the channel hook object. Once that's done, the loader object is released; there is no need to hold it because the channel hook DLL's implementation of DllCanUnloadNow always returns FALSE. The last thing this code does is delegate to the DllMain function provided by the proxy/stub infrastructure in the dlldata.c file generated by the MIDL compiler. This function must be called to give the proxy/stub DLL a chance to initialize itself. The /entry linker switch is used to remap the proxy/stub DLL's entry point to the NewDll-Main function in place of the original DllMain, as shown in Figure 14. The makefile also compiles and links MethodTimeHookPS.cpp, which contains the code for the new entry point. By default, dual and oleautomation interfaces rely on the Universal Marshaler to build proxies and stubs on the fly based on the information in their typelibs. These interfaces can be made to work with the method-timing channel hook simply by building a standard proxy/stub DLL for them instead. ATL makes this easy because the wizards emit interface definitions outside the ATL-created IDL file's library statement. The MIDL compiler generates proxy/stub code for any interfaces defined outside a library, so the code is already there, just waiting to be used. Visual Basic generates typelibs directly, but the IDL can be reverse-engineered using OleView or an equivalent tool. At installation time, dual and oleautomation interface proxy/stub DLLs need to be registered after the servers with embedded typelibs so that typelib registration doesn't overwrite their registration. All of this grungy proxy/stub work can be avoided simply by linking the method-timing channel hook DLL directly into a server process, but this requires inserting the key portion of NewDllMain into the server's startup sequence, which I was trying to avoid. |
|
|
The Method-timing Algorithm
|
|
|
This means the data stored in g_nCount and g_nTime is shared across all processes that load the channel hook DLL on a given machine. Retrieving this information from a particular server is simply a matter of instantiating an object in a process on that server that loads the channel hook code. The object could then return the data in response to a method call. The Loader class exposed by the channel hook DLL is designed to do this. Here's its interface, ILoader: |
|
|
To allow a Loader object to be created remotely, I configured the channel hook DLL to support activation using the standard COM surrogate process, dllhost.exe. The implementation of the MethodTiming class uses remote Loader objects on each server in an application cluster to collect timing data. Each time the data is retrieved, the algorithm uses the new information about each machine's current state to decide which one to send work. It sends all creation requests to that machine until it finds another with better timing statistics. All this work is done on a separate thread to not slow down the handling of client creation requests. The actual process of analyzing timing data and selecting a machine deserves a little more attention. I wasn't able to find a documented algorithm for load balancing based on method timing, so I cooked one up on my own. It isn't as tuned as I would like it to be, but it is better than what I started with. In essence, the Loader object cooks the timing data to return "task-seconds" per interval, where task-seconds is the total time of all measured COM calls ending in the interval. The interval is controlled by the algorithm object's thread, which sleeps for half a second between polling the servers. The Loader also changes the signal slightly as the data is represented as longs, and the implicit integer division means fractional values would be dropped. The code in Figure 15 shows the GetAverageMethodTime method. (The mutex used in this code and in the previous channel hook code is shared with all processes that have loaded the channel hook DLL.) As noted previously, all the data collection and analysis work is done on a separate thread so as not to interfere with client creation requests. This separate thread is started when a MethodTiming object is initialized and executes the MethodTimeMonitor function. The function is passed a pointer to the MethodTiming object that created it. Every half second the thread wakes up and polls each of the machines in the object's list of servers. The list is maintained as an array of HostTimeInfo structures, each of which contains a machine's name, a reference to a remote Loader object running on that machine, and a current average method time value. |
|
|
The thread walks the array (m_rghti), calls to each server's Loader to get the latest timing data, and stores the lowest value as an index (m_phti). (A more sophisticated implementation would do this polling on separate threads.) The code for the MethodTimeMonitor thread function is shown in Figure 16. Notice that it softens the impact of dramatic timing changes by only applying a quarter of the delta between the current timing value and the value from the previous reading. When a forwarding class object calls to a MethodTiming object's CreateInstance method |
|
|
the creation request is forwarded to the server that is currently least loaded, as identified by the m_phti pointer. Figure 17 shows this entire architecture. |
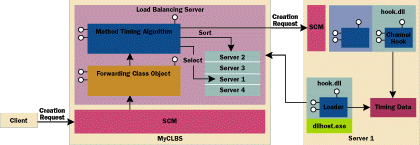 |
| Figure 17 Method Timing Algorithm Architecture |
|
All the decisions I made about frequency of polling and my recipe for cooking the data are based entirely on simple empirical study on my set of hosts using my test client and server. Mileage in other situations may vary.
Making it Real
|
|
|
(Routing Server was the earlier name for a CLBS.) Sub-keys under the RoutingServer key specify servers in the application cluster. The DefaultAlgorithm named value specifies the ProgID or CLSID of a class that implements ILoadBalancingAlgorithm. Four implementations are provided: random, round-robin, method timing (which I described), and CPU load (based on Performance Monitor statistics gathered via the Performance Data Helper library). For more information, see Gary Peluso's article, "Design Your Application to Manage Performance Data Logs Using the PDH Library" in the December 1999 issue of MSJ. Finally, because it needs to make calls to remote machines, the load-balancing service can't run as System. It must be configured to execute as a discriminated user account instead. As with COM+, classes must be configured to support load balancing. Classes indicate their desire to be load balanced by registering on the CLBS under a new class category, Load Balanced Classes. The classes must also be registered as having the same AppID as the load-balancing service to avoid problems with activation identity. If they aren't, the service's attempts to register class objects will succeed, but client attempts to access the class objects will fail, returning CLASS_E_CLASSNOTREGISTERED. As with COM+, clients must be configured to send creation requests to a CLBS where the load-balancing service is running. Note that this infrastructure is a prototype—it's not ready to be deployed in a production environment (a list of known issues is provided with the code). Its purpose is simply to explore an approach to creating a load-balancing service for COM and MTS, and to document some interesting obstacles and how to get around them. This prototype is only guaranteed to take up space on your hard drive. Use of this infrastructure for any other purpose is undertaken at your own risk. That said, the code is available from the link at the top of this article.
Other Balancing and Clustering Technologies
What about JIT Activation?
Summary
|
|
For related information see: Redeployment of COM+ Load Balancing (CLB) at: http://msdn.microsoft.com/library/techart/complusload.htm. Also check http://msdn.microsoft.com for daily updates on developer programs, resources and events. |
From the January 2000 issue of Microsoft Systems Journal.