January 1996
![]()
The DAO of Databases: Using Data Access Objects and the Jet Engine in C++
Michael Mee, Peter Tucker, and John McCullough
Michael Mee is the program manager for DAO at Microsoft. Peter Tucker is the test lead for DAO and John McCullough wrote much of the code that comprises the DAO SDK.
Click to open or copy the DAOSAMP project files.
The growing success of Microsoft® Access has made its MDB file format a standard way to store and manipulate data on the desktop. More and more institutions are building database apps based on Microsoft Access, and increasing numbers of programmers are using Microsoft Access, Visual Basic®, and even Microsoft Excel to write custom MDB-based apps. But C/C++ programmers have been left out in the cold. The only way to access MDB files from C/C++ is to use the ODBC driver for the Jet engine, and using ODBC to access the Jet engine is a little like trying to suck cake through a straw. ODBC is geared more for SQL-based client/server type databases; it doesn't expose the ISAM operations fundamental to Jet operation, such as Set Index and Seek. Ironically, when it comes to writing MDB apps, Microsoft Access 95, Visual Basic 4.0, and Microsoft Excel 95 offer more programming ease and power than C++. Until now, that is. Starting in version 4.0, Visual C++ ships with an OLE automation server called DAO that gives C/C++ programmers full access to the Microsoft Jet engine.
In this article we introduce you to the features that DAO provides and demonstrate their use in the sample app that ships with the DAO SDK. We assume you're familiar with databases (and C++) but haven't necessarily used a Microsoft database product.
DAO (Data Access Objects) is a set of OLE objects that simplifies database programming. There's a Database object to represent-what else-the database, which contains a collection of Tabledef (table definition) objects, each of which in turn contains a collection of Field objects. Each object has properties and methods that expose pertinent functionality. Figure 1 shows the object hierarchy.
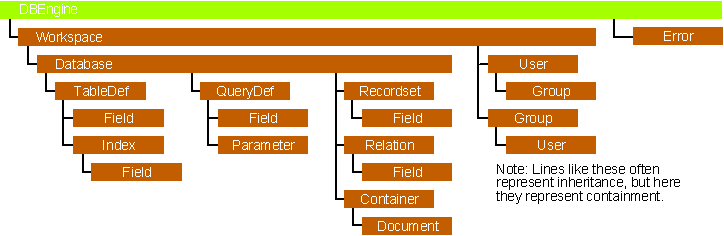
Figure 1 DAO Object Hierarchy
DAO uses a set of DLLs called the Jet engine (see Figure 2). Together these DLLs provide access not only to MDB files, but also to other database formats including Xbase formats such as dBase and FoxPro®, the Paradox DB format, spreadsheet data from Microsoft Excel and Lotus 1-2-3, and common text file formats such as fixed-width and comma-separated text. Jet even provides a route to ODBC sources.
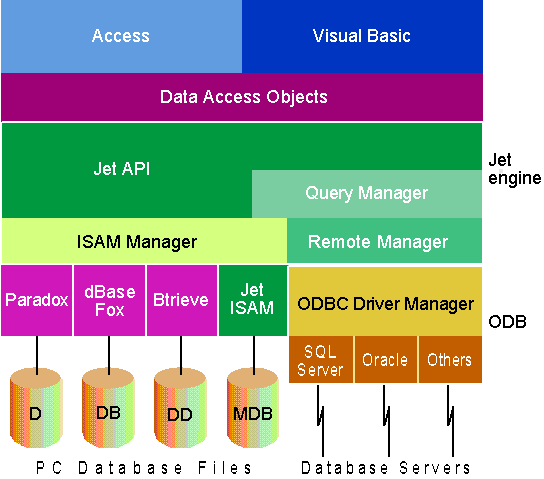
Figure 2 Overview of DAO and Jet
Jet includes a powerful query processor that makes complex operations easy. For example, you can query an MDB table joined to a SQL Server table and update the resulting view. The ability to create stored queries (equivalent to a SQL view) that in turn reference other queries, all of which are still updatable, is quite powerful. It removes much of the application development burden: you can change your app simply by modifying your queries, without editing a single line of code! It's beyond the scope of this article to describe Jet in its entirety, so take a good look at the Microsoft Access documentation. We cannot stress too highly how much coding and design time you will save if you have a solid understanding of database techniques in general and Jet in particular.
Data Access Objects are implemented as OLE automation dual interfaces (see the sidebar, "OLE Automation"). The DAO DLL, DAO3032.DLL, implements an in-process 32-bit OLE automation server that in turn calls the private DLL entry points found in the Jet engine, MSJT3032.DLL. The same DLL supplied with Visual C++Ş is used to provide all programmatic access to data in Microsoft Access 95, Visual Basic 4.0, and Microsoft Excel 95. The DAO DLL includes a type library that describes all the interfaces it contains. Both ANSI and Unicode versions of the interfaces are supplied; external support such as MFCANS32.DLL is no longer required. The DAO OLE automation server provides one of the first examples of a complex OLE automation component. Indeed, much of the upgraded OLE automation functionality first found in Windows NT™ 3.51 and now in Windows® 95 was prompted in part by the parallel development of DAO.
The DAO interfaces exposed by the type library are defined in the header file DBDAOINT.H. Figure 3 shows a fragment of the top-level DBEngine object definition. DBEngine has five properties: Version, IniPath, DefaultUser, DefaultPassword, and LoginTimeout. IniPath and LoginTimeout can be set as well as retrieved. Four methods are also shown: CompactDatabase, OpenDatabase, CreateWorkspace, and CreateDatabase. The declarations in Figure 3 look simple enough; you can probably guess what most of the functions do. But there's a lot of behind-the-scenes plumbing required to use them. For example, since _DAODBEngine is an OLE automation dual interface, you must AddRef and Release it, just like any other OLE interface. And DAO uses OLE BSTRs instead of native C/C++ character pointers or MFC CStrings. (A BSTR is a character string with the length stored in the first DWORD and no /0 at the end.) Furthermore, many parameters are passed as VARIANTs, especially optional ones. Fortunately, MFC 4.0 provides some new classes to help smooth the way.
There are three ways you can program DAO from C++:
Naturally, each of these methods has advantages and disadvantages. Since programming directly through automation is fairly tedious, most people opt for either the MFC or DAO SDK classes. The MFC classes (CDaoXxx) are designed to have the same look and feel as the MFC ODBC classes (CDatabase), with some notable improvements such as the ability to specify field names at run time. If you're already familiar with CDatabase, CRecordset and the rest, the MFC DAO classes may be the quickest way to climb the DAO learning curve, since they're similar in name and operation to the ODBC classes.
If you're already using CDatabase and CRecordset to access MDB files or some other ISAM format, it's a simple exercise to convert your code to CDaoDatabase, CDaoRecordset, and so on. Your code will run faster and-with a little extra work-you can take advantage of new features like the ability to bind field names at run time, which has long been an annoying deficiency in the MFC ODBC classes.
Another set of classes, often referred to as the DAO SDK classes, comes with the DAO SDK, which ships with Visual C++ 4.0-though you must install it manually by running the SETUP program in the DAOSDK directory on your CD-ROM. The DAO SDK classes expose even more Jet functionality, and are designed to make programming DAO from C++ just like programming it from Basic. In particular, the DAO SDK classes make heavy use of C++ operator overloading (in violation of MFC's approach). More important, the DAO SDK classes map directly to the underlying automation objects.
The singular DAO SDK names represent single objects; the plural form is the corresponding collection. Thus, for example, CdbError represents a single error; whereas CdbErrors is the total collection of errors, in case there are many. You also get support classes like CdbBookmark, CdbLastOLEError, and CdbException, which don't map directly to any OLE object, but which make programming easier. As you can see, the DAO SDK offers many more classes than MFC. That's because DAO exposes areas of functionality such as security and complex table definition as well as Jet features like user-defined properties. (Jet lets you create your own properties for most of its objects.)
Freed from the backward compatibility constraints that the MFC classes face, the DAO SDK classes expose all the functionality provided by DAO. They have a distinctly different style, though, one that may seem unfamiliar if not strange to MFC programmers. For example, to retrieve property values with MFC, you call GetXxxInfo to fill a struct with information about an object, then examine the particular property you want. To retrieve the names of queries, you'd write:
// With MFC, you get all the properties (info)
// at once, then look at the one you want.
CDaoQueryDefInfo queryinfo;
int nQueries = pDB->GetQueryDefCount( );
for ( int i = 0; i < nQueries; i++ ) {
GetQueryDefInfo( i, queryinfo );
printf("query name is: %s\n", queryinfo.m_strName);
}Using DAO SDK classes, it would go like this:
// With the DAO SDK classes, you retrieve
// individual properties one at a time
CdbDatabase DB;
for (long i = 0; i < DB.Querydefs.getCount(); i++)
printf("query name is: %s\n",
DB.Querydefs[i].GetName());Which classes you use is up to you. You can even mix classes within a single app. You might use the MFC classes for routine forms and viewing, saving the DAO SDK classes for more specialized features like user-defined properties. Except where DAO is required for advanced features, the choice is more a matter of personal taste and experience than any technical merit, although in general the DAO SDK classes are more efficient since they map directly to the underlying objects and methods; whereas a single MFC call might translate into many DAO interface calls. For example, while the GetQueryDefInfo call in the above example may look better because you get all the properties at once, internally GetQueryDefInfo must get each property one-by-one, which is a waste if all you want is the name. (To be fair, MFC provides an optional flag you can set to retrieve partial information such as the query name only-but that's a little hokey.)
In this article, we'll focus on the DAO SDK classes, since they're more interesting and probably less familiar to you. But many of the concepts presented apply regardless of which classes you choose for your app. Figure 4 shows the relationship among the MFC ODBC, MFC DAO, and DAO SDK classes.
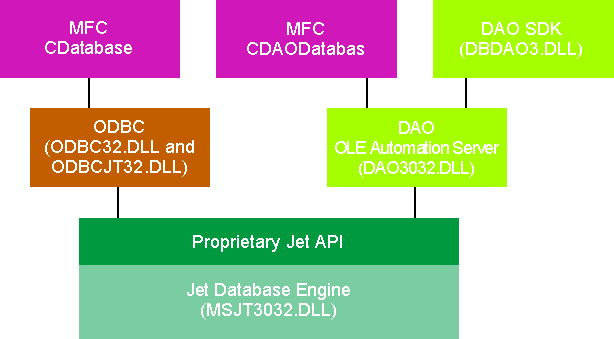
Figure 4 How Classes Use Jet
It seems that every database tool in the universe has an employee application, and DAO is no exception. The DAO SDK comes with a sample EMPLOYEE app that lets you add, modify, and delete rows in a single table in an MDB database. Figure 5 shows EMPLOYEE in action. The full source code lives in \msdev\daosdk\samples\employee, created when you install the DAO SDK. EMPLOYEE is an MFC SDI app that uses the DAO SDK classes, though it could easily have been written using the MFC classes. EMPLOYEE uses MFC's CFormView and the DDX (Dialog Data Exchange) mechanism to implement a form-based view of employee records. It also uses two classes that are new in MFC 4.0: COleDateTime, which formats the date, and COleVariant, which handles OLE automation VARIANT data types (see sidebar).
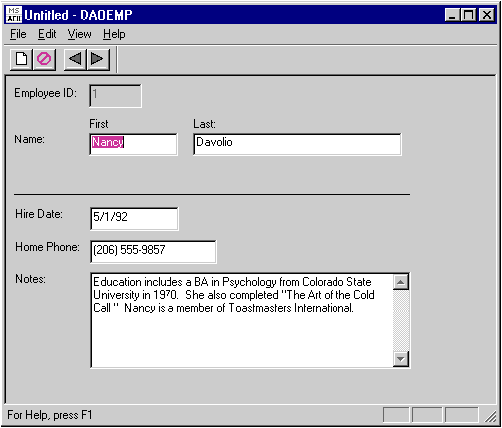
Figure 5 EMPLOYEE
The standard user interface model for MFC apps is the document/view model. You open a document (file), then view it. Unfortunately, this model doesn't always fit database applications that well. Usually, there's no identifiable document, but rather a collection of records culled from some collection of tables that may span several physical files-or none at all, in the case of talking to a remote server process. In database apps, the recordset plays the role of document. For some apps, it may be expedient to dispense with doc/view and simply embed the recordset directly in the frame window-but then you lose the ability to maintain multiple views of the same data.
MFC provides a convenient solution in the form of CRecordView and CDaoRecordView, which let you create views directly connected to an ODBC or DAO recordset. AppWizard even knows how to generate such apps. These classes integrate database operations into the MFC user interface framework. Unfortunately, the one thing lacking in the DAO SDK classes is tight integration with MFC. In particular, there's no DAO SDK equivalent to CDaoRecordView.
Instead, EMPLOYEE implements a document class CDAOEMPDoc (see Figure 6), which is really no more than a place to hold the database connection and recordset. As mentioned earlier, one of the advantages of using a document (instead of embedding the recordset directly in the frame) is that it makes writing multiple-view apps easier. Whenever a record is modified, all you have to do is call CDocument::UpdateAllViews and MFC will automatically repaint all the affected views.
When EMPLOYEE starts up, the first thing it does is create a new document, just like a normal MFC SDI app. The similarity ends there. OnNewDocument calls a helper function called CDAOEMPDoc::ConnectToDatabase to open the database (see Figure 7). The first thing ConnectToDatabase does is display a File Open common dialog to get the database file name from the user. Once ConnectToDatabase has the file name, it opens the database.
m_cEmpDatabase =
m_cDBEngine.Workspaces[0L].OpenDatabase(lpstrFile);Because the DAO SDK classes all have default collections defined, you can often omit explicit references to collection members. The following lines would accomplish the same thing with less typing.
m_cEmpDatabase =
m_cDBEngine[0L].OpenDatabase(lpstrFile);In other words, Workspaces is the default collection for CdbDBEngine. In C++ terms, CdbDBEngine.operator invokes CdbDBEngine.Workspaces(0).operator. Those of you familiar with DAO will recognize the following as also valid:
m_cEmpDatabase = m_cDBEngine.OpenDatabase(lpstrFile);OpenDatabase accepts optional parameters for an ODBC connection, read-only and exclusive flags, but EMPLOYEE doesn't use these.
Since the Employee database has only one table (the Employee table), CDAOEMPDoc opens the recordset at the same time as the database and leaves it open for the lifetime of the document.
m_cEmpRecordSet =
m_cEmpDatabase.OpenRecordset(_T("Employees"),
dbOpenTable);The most efficient way to open any recordset is as a table-type recordset (described later), so EMPLOYEE explicitly requests that type. This is not strictly necessary, since DAO would have chosen dbOpenTable by default as the most efficient form available.
What happens if something goes wrong in OpenDatabase or OpenRecordset? The DAO SDK classes use C++ exceptions to signal errors. It's your responsibility to handle them using standard C++ try/catch blocks. Figure 7 shows the gory details. You can see CdbException and CdbLastOLEError in action. To keep overhead as low as possible, CdbException contains only the HRESULT that triggered the error. HRESULTs are an OLE phenomenon: a LONG composed of several bit fields, one of which contains the DAO error number. You can use the DBERR macro to extract it. CdbLastOLEError retrieves the last system OLE error that was pushed. One of its more useful member functions is GetDescription, which returns a text description of the error. EMPLOYEE isn't too bright when it comes to handling errors: ConnectToDatabase displays a message, OnNewDocument returns FALSE, and the application terminates. In real life, you'd do something more friendly.
You can also retrieve error information from DAO's Errors collection. The error-handling code in Figure 7 could be rewritten as
wsprintf(szBuf, _T("Error %d : %s\n"),
m_cDBEngine.Errors[0].GetNumber(),
(LPCTSTR) m_cDBEngine.Errors[0].GetDescription());Usually, there's just one error, but sometimes there are more because multiple errors occur trying to execute a complex operation. This often happens with ODBC data sources. In the event of multiple errors, DAO pushes the most general error (such as "operation failed") as the OLE error, and stores the full list in the Errors collection, which you must analyze to determine what went wrong. DBDAOERR.H defines symbols you can use to test for specific conditions.
if (e.m_hr == E_DAO_DatabaseNotFound)
// try againThe E_DAO_Xxx symbols are #defined as HRESULTs so you can use them if you're programming directly to the DAO OLE automation interfaces. The #define statements use the same DAO error numbers that Basic users see.
#define E_DAO_DatabaseNotFound DBDAOERR(3004)This makes debugging easier if you're prototyping in Basic. If you'd rather work directly with DAO error numbers instead of #define symbols, you can always use DBERR to extract the error number-but experienced C++ programmers will probably laugh at your code:
if (DBERR(e.m_hr) == 3004) { // DB not found
// try again...
}To display records, EMPLOYEE uses a CFormView-derived view with members for each Employee table field.
class CDAOEMPView : public CFormView {
long m_nEmpNum;
CString m_strFirstName;
CString m_strHomePhone;
CString m_strLastName;
CString m_strNotes;
COleDateTime m_HireDate;
.
.
.
};These members are mapped via the standard MFC DDX mechanism to the actual table fields. But DDX requires that the data be in MFC-native formats such as long, CString, and COleDateTime. Since DAO retrieves field values as VARIANTs (see sidebar), the view must convert them to MFC types before invoking DDX, when the view is first created, and whenever the user navigates to a new record. This is pretty straightforward, if cumbersome. A couple of macros and a helper function ease the chore.
// Convert a variant to a string
// (only if it's a string variant)
inline void VarToCStr(CString *c, COleVariant *v)
{
if(v->vt==VT_BSTR)
*c = (LPCTSTR)v->bstrVal;
else
*c = _T("");
} #define VTOLONG(v) \
((v).vt==VT_I4 ? (LONG)(v).iVal:0L)
#define VTODATE(v) \
((v).vt==VT_DATE ? (CTime)(v).iVal:0L)Don't be tempted to blindly copy from the bstrVal tag of the variant union! It's perfectly legal for a string field to have a variant type of VT_NULL, assuming the underlying database column allows null values, as most do.
When the view gets an update message, it copies the new record data into its members (see Figure 8). The view uses the new MFC 4.0 COleDateTime class to convert the OLE variant to a date-that's one of the neat new features of MFC 4.0. The table fields are referenced through the #define symbols EMP_LAST_NAME, EMP_HIRE_DATE, and so on. These can be numeric indexes or the text name of the field. For example, EMP_HIRE_DATE could be #defined as 5 or as "HireDate." In general, most DAO collection members can be referenced by name or number. Numbers are of course marginally faster, but strings are less errorprone and easier to maintain, so EMPLOYEE uses them. The names must be Unicode or ANSI strings, as defined by your project settings. If you're building a Unicode app, use Unicode strings; if it's an ANSI app, use ANSI strings. The Windows _T macro makes your strings Unicode/ANSI-independent.
When the user presses the Next or Previous buttons, the document gets the command.
void CDAOEMPDoc::OnEditNext()
{
if(!OKToMove())
return;
m_cEmpRecordSet.MoveNext();
if(m_cEmpRecordSet.GetEOF()) {
MessageBeep(0);
m_cEmpRecordSet.MovePrevious();
} else
UpdateAllViews(NULL);
}CDAOEMPDoc first checks to see if the current record is dirty-that is, needs updating. Assuming it's OK to move, CdbRecordset::MoveNext does the work. CDAOEMPDoc checks the EOF property to see if an attempt was made to move past the last record. A more elegant implementation would gray the Next command button when there are no more records, but it's not always easy to determine when the last record is reached (for example, when moving through a forward-only recordset as described later).
If the current record is dirty, EMPLOYEE asks the user to confirm the update-and now I'm talking about updating the data records, not updating the screen as CDAOEMPView::OnUpdate does. If the user confirms, CDAOEMPView calls CDAOEMPDoc::UpdateEmpRec to update the recordset (see Figure 9). Since DAO doesn't support the MFC field exchange mechanism, you have to update the fields manually. Don't worry, it's no big deal. Most of the work is wrapping the C++ objects back into COleVariants for DAO.
To perform an update, the recordset must be in either Add or Edit mode, so UpdateEmpRec puts the recordset in Edit mode if it hasn't been previously set by Add. There's only one bit of subterfuge that requires explanation. UpdateEmpRec concludes by creating a bookmark to the last modified record and making that the current record.
CdbBookmark cBookmark =
m_cEmpRecordSet.GetLastModified();
m_cEmpRecordSet.SetBookmark(cBookmark);
This is necessary because the goal is to end up with the modified record as the current record. In the case of an Edit operation, the bookmark is unnecessary because DAO would leave the edited record as the current record anyway; but in the case of an Add operation, DAO positions the recordset on the record that was current before the new record was added-which is not what you want. In EMPLOYEE, when a new record is added, you want it to remain the current record. Hence the bookmark.
EMPLOYEE is a typical form-based application where interactive browsing and updating are the normal operations. When coded against an MDB or other ISAM file, EMPLOYEE is fast and efficient. But if the same code is used against an ODBC database, it won't perform as well. Reading and writing files is fast, even over a network, but talking to another process is fundamentally slower and requires special optimizations.
I'll describe three different kinds of recordsets you can use to speed things up: table-type, dynaset, and snapshot recordsets. The sample program DAOREAD (see Figure 10) that comes with the DAO SDK reads data using each of these methods and displays timing statistics. Figure 11 shows the function CDAOReadDlg::OnExecute, which does the work.
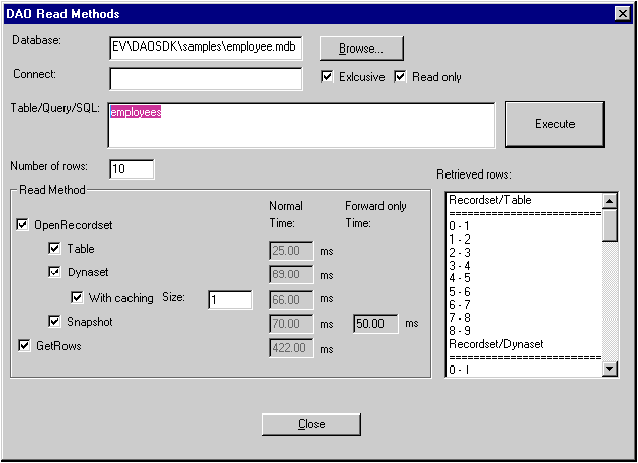
Figure 10 DAOREAD
If you know you're dealing with a real table (as opposed to a view or query), you can use a table-type recordset. Just specify dbOpenTable as the second argument to OpenRecordset.
RSetTable =
m_dbDatabase.OpenRecordset(m_strTableQuery,
dbOpenTable);You can only open actual tables native to the database. Any of the non-ODBC data formats will support this mode, as long as you open them first as a database and then with dbOpenTable. Trying to open a recordset on names of QueryDefs or attached TableDefs will fail. Data in a table-type recordset is writable as well as readable. To retrieve the data in the recordset, the DAOREAD sample program calls CdbRecordset::GetField and stores the value in a COleVariant. To navigate the records, DAOREAD calls MoveNext and GetEOF to determine when there are no more records to fetch (see Figure 12).
So far, this isn't much different from the way EMPLOYEE does it. The next method uses a dynaset-type recordset, which you get by specifying dbOpenDynaset when you open the recordset. You can open a dynaset on base tables, attached tables, QueryDefs, and even row-returning SQL statements. Like table-type recordsets, dynasets are read/write. The only major change to DAOREAD is the use of SetCacheStart and SetCacheSize, which are specific to ODBC. They set up an internal data cache for fast retrieval and cursor movement within a range of records. You give SetCacheStart a bookmark indicating the start of the range; SetCacheSize gets the number of records you want to cache. The cache is created and filled as you navigate the records, so subsequent reads in that range of records are fast. Dynasets are especially useful for reading data into the grid-type controls found in spreadsheets, as well as in other situations where you need to display several records at once. You must explicitly reposition the cache when you move outside its range (see Figure 13).
The third and final optimization uses a snapshot-type recordset (dbOpenSnapshot). You can open a snapshot-type recordset on a base table, attached table, QueryDef, or row-returning SQL statement, but a snapshot recordset is just that: a snapshot. The data cannot be modified, and if another process or thread modifies it after you've created your snapshot, the changes are not reflected.
Actually, DAOREAD uses a forward-only scrolling snapshot as well as a normal snapshot. Figure 14 shows the forward-scrolling version. As the name implies, you can navigate this kind of recordset in a forward direction only; attempting to move backwards triggers an error. Forward-only recordsets are typically faster than bidirectional recordsets, especially with ODBC data, because they eliminate the extra overhead required to support backward scrolling.
Browsing records one at a time is the sort of thing humans like to do, but programs often need to retrieve a whole bunch of data in one fell swoop. For example, you might want to visit every employee record to compute aggregate information like average age or salary. In such a scenario, accessing fields individually through the recordset is too slow. What you really want is bulk record retrieval.
By far the fastest way to retrieve large amounts of data is with CdbRecordset::GetRows or its more advanced cousin GetRowsEx. Both functions fetch multiple records into your program's buffers and, in the case of remote data, both use SetCacheStart and SetCacheSize internally for added speed. GetRows and GetRowsEx return the number of rows actually fetched, which may be less than what you requested: if you ask for ten records and there are only six, GetRows will fetch them all and return six.
If an error occurs retrieving data, GetRows will not usually throw an error. Instead, it returns with however many rows it was able to read before the error occurred, and leaves the recordset pointing at the row that caused the error. GetRows works this way for a couple of reasons. First, it's hard to provide rich error information through a single OLE HRESULT. Second, signaling an error when partial data has been fetched complicates error handling; memory may have been allocated that must now be freed. If GetRows returns an error, you're guaranteed that no memory was allocated that you need to free; if no error occurs, then you're responsible for freeing memory GetRows may have allocated on your behalf.
The bottom line is, it's up to you to examine the number of rows actually fetched and do the right thing. If GetRows fetched fewer rows than you requested, you've either run out of records or an error occurred fetching what is now the current row. You can call GetEOF to see if you reached the end of the recordset. If not, an error must have occurred, in which case you can either examine the Errors collection or retrieve each field in the current row and check the error that results.
GetRows takes only one argument: the number of rows to fetch. It returns all fields in the recordset as a single COleVariant object containing a two-dimensional "safe array" indexed by Field and Record. It's up to you to parse this array using the standard safe array functions. Figure 15 shows a fragment from CGetRowsDlg::DoGetRows in the GETROWS sample program that comes with the DAO SDK. GETROWS uses SafeArrayGetUBound to get the number of records actually fetched, and SafeArrayGetElement to get each value from the COleVariant. Be careful using SafeArrayGetUBound: the dimension requested and the value returned in lNumRecords is 1-based, unlike most C/C++ functions, which are 0-based. The upper bound returned in lNumRecords is the upper index bound, not the count-so you must either increment the count by one, or loop using <= instead of the usual <. There's great potential for off-by-one errors here, as we discovered the hard way.
GetRowsEx works just like GetRows, but it's much more powerful and consequently a little harder to use (but not much). Unlike GetRows, which always fetches all the fields in the recordset, GetRowsEx lets you specify which fields to fetch. In addition, GetRowsEx can read data into your own custom C struct, instead of returning it as one big array. GetRowsEx even converts to native C types automatically! Figure 16 shows the CGetRowsDlg::DoGetRowsEx function from GETROWS.
To use GetRowsEx, you first define a struct you want to receive data, and then a "binding structure" that tells GetRowsEx which table fields go where in your struct (see Figure 17). These paired declarations could go in a header file for inclusion throughout your app. You might even use several different structs for each table to minimize fetching of fields you don't always need. Once the structures are defined, all that remains is to call GetRowsEx.
LPEMP pEmpRows = new EMP[MAX_EMP_REC];
LONG lNumRecords;
TCHAR pBuf[MAX_EMP_REC * 15];
lNumRecords = m_cEmpRecordSet.GetRowsEx(
pEmpRows, sizeof(EMP),
&Bindings[0],
sizeof(Bindings)/sizeof(DAORSETBINDING),
pBuf, sizeof(pBuf),
MAX_EMP_REC);This code fetches Employee ID, Last Name, and First Name from the Employees table, and loads the data into the pEmpRows array of EMP structures. From there, manipulating the data is much easier, since it's already converted to native C types. Figure 16 shows the complete source, with error handling and everything else.
There's just one trick that deserves further explanation. Reading variable-length fields is often a pain-how much space do you allocate for each field? You might allocate an array of char[MAXNAMELEN]s to hold a name like "Howard Beaureguard Fitzsimmons Elsemerath III"-but then you'll have a lot of wasted space for names like "Po Li." You can always specify dbBindVariant as the bind type in your binding structure: GetRowsEx will retrieve a VT_BSTR or VT_NULL into your struct. But that's no fun! It fragments memory, and you have to free the Variant yourself when you're finished using it. What you really want is one big buffer to hold all the variable-length strings, nicely packed end-to-end so there's no wasted space. Well, GetRowsEx lets you do exactly that!
The pvVarBuffer parameter to GetRowsEx lets you pass a chunk of memory for holding variable-length data. If you bind a field with dbBindLPSTRING, GetRowsEx fills your buffer with variable-length data as it's loaded and sets the pointers in your data structure array to point to the start of each zero-terminated string in the buffer. Figure 18 shows how it works. The same trick works for binary data, but you must bind with dbBindBlob as the bind type and you must allocate two elements in your data structure, a ULONG to hold the length and an LPVOID to hold a pointer to the actual data itself.
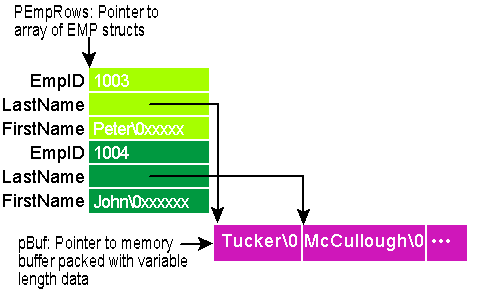
Figure 18 Variable-length String Allocation
We've covered a lot of topics and discussed some wonderful DAO details that should help you build good fast functional database apps. You could easily stop here and run to your keyboard to try everything out-but don't! Design your database first.
We can't emphasize this enough-before cranking up your favorite C++ compiler, build a prototype! Not a prototype of your application, but a prototype of your data. Before you write a single line of code, start by designing your database. Mock up the tables you'll need. Define the relationships between them, and the dependencies that will save code-like referential integrity constraints and cascading deletes and updates. Once you've done all that, build thequeriesyouthinkyou'llneedtoretrieveandupdatedata.
When you have a working database, load some data and run your queries. And not just a few records, but as many as you expect the final system to manage. That way, there won't be any surprises. All too often developers discover the hard way that what works well with 10MB can grind to a crawl at 100MB. If necessary, write a short program to generate gobs of artificial data. The effort will be well spent.
There are lots of good products you can use to build prototypes without writing any code. Since DAO works with many data formats, you're not restricted to Microsoft Access. For performance testing, however, you should use whatever format you intend to use for the real system. If you use Access Basic to test performance, you can be confident that the results you get from C++ will be as good or better. Another benefit to using Microsoft Access is that instead of doing queries the old way, by embedding SQL commands in your code, you can create your queries in Microsoft Access and invoke them by name from C++. It's a lot easier that way. The queries will execute slightly faster too, because they're already compiled. And if you ever need to change a query, you can do it without recompiling your code!
Since DAO is exposed in both C++ and Basic, you can use Basic as a rapid prototyping language. Just type your DAO code and go. No compilation, no linking required. It's a lot easier to explore DAO from Basic before you make the grand plunge to C++. You can also use Basic for debugging: if something doesn't work right in C++, you can run Microsoft Access to see how the equivalent Basic code behaves.
As a closing illustration of how the DAO SDK classes facilitate this development approach, Figures 19 and 20 show a simple Basic program and its C++ equivalent. The program combines many of the concepts discussed in this article: variants with date handling, error handling, bookmarks, and even some features we didn't mention, like FindFirst.
We've explored several key features of DAO. To get to know DAO, you should read the documentation and explore the sample programs that come with the SDK-though we will remind you that the place to begin is with a thorough understanding of database principles. Once you have that, DAO is guaranteed to keep your database in spiritual harmony with C++!
Unless you really have your head in the sand, you've probably heard of OLE automation by now, which-contrary to popular belief-has nothing to do with drag-and-drop, in-place editing, linking, embedding, or any of the other buzzwords usually associated with OLE. Rather, automation is a way to invoke code that lives within other COM (Component Object Model) objects that exist on your system.
You can think of OLE automation objects as typesafe DLLs. Just as a DLL exposes dynamically bindable entry points, so does an OLE automation object. The difference is that automation objects are self-describing. They provide a type library, or typelib, that describes all the entry points, parameters, and return types. Some programming tools such as Visual Basic use the typelib exclusively; other languages like C/C++ rely on a header file that's automatically generated by the typelib compiler, MKTYPLIB. The header file describes interfaces that are wrapped by the DAO SDK classes.
If you already know something about automation, you're probably thinking, "I know, automation is IDispatch and IDispatch is sloooow." Indeed, when automation was first introduced, IDispatch was the only way to invoke functions. But there have been some useful improvements recently, which you may not be aware of. Starting in Windows NT 3.51 and now in Windows 95, there's a new automation interface type called a dual interface. A dual interface supports both IDispatch and a normal vtable interface. The first seven functions in a dual interface are the normal IDispatch functions; the rest can be whatever you want, as long as the arguments are official automation types. Dual interfaces provide both the flexibility of run-time IDispatch binding and the speed of compile-time vtable binding. C/C++ clients and Visual Basic clients can call dual interfaces directly through the vtable, while still using late-bound IDispatch calls if need be. For a detailed look at dual interfaces, see Don Box's OLE Q&A in the December 1995 MSJ. Also, the section "Exposing OLE Automation Objects" in the latest Win32 SDK reference contains more information about dual interfaces, and Kraig Brockschmidt's article "Design Considerations for Implementing a Simple OLE Automation Controller" (MSJ, May 1995) provides helpful information about building an OLE automation server.
Much of the terminology associated with OLE automation derives from its Basic heritage. Here's a brief jargon primer for the uninitiated.
Methods As in C++, a method is just a function associated with a particular class of object. A method takes zero or more arguments and may or may not return a value. A methodthathasnoreturnvaluebehaveslikeasubroutine in Basic. Methods are only valid as rvalues in expressions.
Properties A property is an attribute of an object that can be retrieved or set. Unlike methods, properties don't have arguments, and they can act as lvalues as well as rvalues. That is, you can set as well as get them. For example, in Basic you can write
Elephant.Name = "Fred"
Name$ = Elephant.Namewhere Name is a property of Elephant objects. Properties are by convention implemented in C++ as a pair of methods: one to get and one to set the property. For example, the DAO Name property is implemented as two methods:
char* get_Name();
void put_Name(char *);Of course, this is a simplification. The actual declarations from DBDAOINT.H contain a lot of OLE macro gobbledygook.
STDMETHOD(get_Name) (THIS_ BSTR FAR* pbstr) PURE;
STDMETHOD(put_Name) (THIS_ BSTR Name) PURE;Collections A collection is a group of like objects gathered together for ease of reference. Collections provide generic group operations to retrieve individual objects by ordinal or name, get the count of objects, add and remove objects from the collection (often with the side effect of creating or deleting the object itself), and so on. OLE automation recognizes collections from the existence of a _NewEnum property. The value of this property, if it exists, is an IEnumVARIANT interface, which has methods to enumerate the objects in the collection.
Variants OLE automation defines a data type VARIANT, which is a tagged union of most common C types along with more complex types such as DATE, CURRENCY, and BSTR. Figure A shows the definition from OAIDL.H. Variants have several purposes. First, they provide a safe type to pass between OLE automation client and server with less chance of crashing due to bad pointers, especially for strings and arrays. Second, variants can be remoted across processes using standard remote procedure call mechanisms, thus avoiding the need to write custom proxy code for every interface. Thus, even though it was written as an inproc OLE automation server, DAO can be remoted not only across processes within a single machine, but also across processes on different machines. Variants take care of machine-dependent conversions for byte order, alignment, size, and so on-automatically. Last but not least, variants provide useful database semantics such as null values. In C/C++, it isn't possible to return NULL for a nonpointer type such as int or long, because in C, NULL is indistinguishable from zero; whereas database apps typically must distinguish between the legal value zero and the notion of "no value." Variants provide a special data type,VT_NULL,tohandlethis.Convertingfromvariants to native C/C++ types can be a nuisance, but MFC 4.0 hasanewclasscalledCOleVariantwithderivativesCOleDateTimeandCOleCurrencythatsmooththeprocess.
From the January 1996 issue of Microsoft Systems Journal.