February 1996
![]()
Write a Simple HTTP-based Server Using MFC and Windows Sockets
David Cook
David Cook is an independent software vendor who consults for Microsoft as a program manager in the Personal Systems Division. He can be reached at davepc2@oz.net.
Click to open or copy the WEBSTER project files.
Special thanks to Mike Ahern for his suggestions and encouragement in the writing of this article.
Everybody and anybody these days is navigating the vast reaches of the World WideWeb.Whenpeopleget excited about the Web, they usually think in terms of searching forinformationorbrowsinghome shopping catalogs. But what if instead of being a Web consumer, you want to be a provider?
You may be surprised how easy it is to write a Web server. While the server I'll present here, Webster, is without question a bare-bones "baby" server, you can nevertheless use it to present your very own personal home page that anyone on the Web can browse. You can use Webster to advertise your consulting services or your cousin's auto repair shop. More important, Webster illustrates some of the basic techniques of Internet programming. By the time you read this, you'll be a certified Webnerd, able to converse fluently about TCP/IP, HTTP, HTML, URLs, and UFOs (just kidding).
Before delving into Webster, let me give you a quick Web primer. Most of you have probably used a Web browser such as Netscape, NCSA Mosaic or the Microsoft Internet Explorer, which comes with the Windows 95 Plus! pack. You click here, click there, hopping from place to place to visit pages like the one in Figure 1. But what's going on behind the scenes to display those pages? Where does your computer get the page from? How does it arrive? What sort of information travels over the wire?
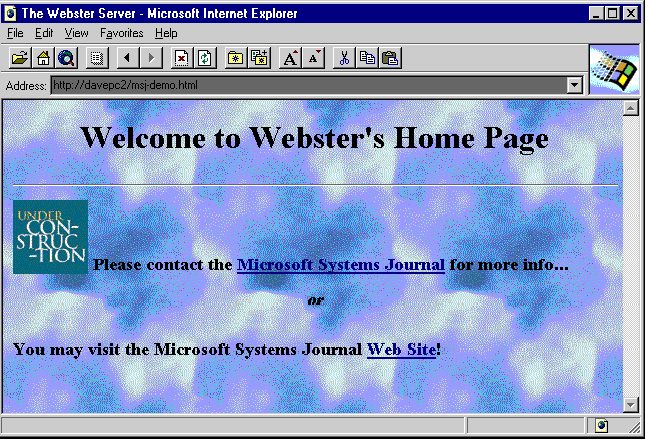
Figure 1 Webster's home page
The Web was designed as an easy visual interface for navigating the Internet. But this presents a communications problem, because as everyone knows, pictures require a lot more information than words. Even compressed, most imagestaketens,ifnothundreds of kilobytes. In the not-too-distant future, when everyone has their own ISDN line, bandwidth won't be a problem. But for now, many people are still surfing at 14.4 kbaud. So how do you get the pictures to the masses without making them wait until their hair turns gray?
To address this bandwidth problem, Web pages are not transmitted all at once, but are instead built from several transactions. The basic idea is to transmit the text portion of the page first, with information about what graphics go where and where to find them on the server. A browser can display the basic page quickly, then retrieve the graphics separately. Meanwhile, the user can read the page or jump to another one. If the user wants to visit another page before seeing all the images of the current page, the browser can simply forget about the graphics and go directly to the new page.
To see how this works in practice, let's step through a typical Web browsing session. When you crank up your Web browser and call up your favorite home page, your browser program initiates a transaction with another piece of software running on a computer somewhere on the Internet. For the purposes of this discussion, the browser program is the Web client and the software running on the other computer is the Web server.
The action begins when the client initiates a connection by attempting to contact the Web server on the host computer specified in the URL. URL stands for Uniform Resource Locator, which is a fancy name for an Internet address. You know, those names like http://msj.com/things.to.do/kill.barney.now. A URL is a string that fully identifies an information resource on the Internet. There are two basic elements to a URL: a scheme, followed by a "scheme-specific-part." The scheme identifies the method or service by which the scheme-specific-part is accessed. For Web pages, the scheme is HTTP-the message protocol that Web clients and servers use to talk to one another- which is why Web pages always have URLs that begins with"http:".OtherschemesincludeFTP, Wais, and Gopher.
The scheme-specific-part of the URL varies depending on the scheme. For HTTP, it normally contains a host HTTP server name and path to an HTML document on that server. Many Web servers support several schemes. Each of these information exchange schemes has its own protocols, but to provide "one stop shopping," many Internet sites run a single server that integrates all the services into one manageable facility. Each service on a multiservice server is assigned its own port number. By convention, HTTP clients connect on port 80. Any Web client seeking to contact a Web server on a given host system knows that this is the port number on which to make the connection. Other services use other ports; for example, Gopher uses port 70.
When the server acknowledges the connection, the client sends a request for information and waits for the server to reply. Typically, the client begins by requesting a home page on the server's host computer. Assuming everything goes smoothly, the server transmits the resource back to the client, then closes the connection. The transaction is complete. The server goes back to waiting for another connection request.
On the client side, things have just begun. Typically, the home page contains references to graphic images contained within the page. As the client processes the page, it may initiate more transactions with the server to get additional resources. For example, suppose your home page contains a bitmap image of your company logo. The Web browser will identify the reference to this element in the home page and understand that it needs to contact the server again to get the logo. The browser makes another request in the same manner, this time asking for the image file containing the logo. From the server's point of view, this is just another request for a file, no different from the first one. The server finds the file and transmits it back to the client browser, which draws the graphic in the appropriate location on the display. Figure 2 illustrates how the page is assembled in this fashion.
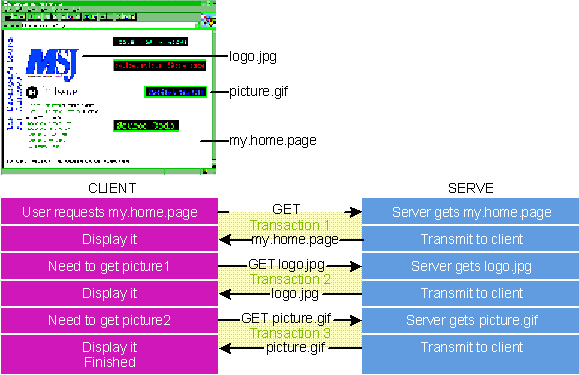
Figure 2 Assembling a Web Page Using Separate Transactions
The point is that the whole page isn't transmitted at once. A Web page may contain many graphics and other elements that consume hundreds of kilobytes, but the browser doesn't have to download the whole shebang to display something. Most Web browsers display the text of a Web page as soon as it arrives, then download additional elements as required. Meanwhile, you can read the page. And if you decide to jump somewhere else, you don't have to wait while the browser downloads 300KB. The browser can simply forget about the current page and start downloading a new one. That is, if it's a smart browser. Dumb browsers might make you wait. But either way, you can appreciate the clever scheme whereby Web pages are assembled using separate transactions with the server.
When the browser gets a home page with references to graphics instead of actual graphics, what does it actually get? What does the information look like that comes over the wire? What exactly are Web pages?
Simply put, a Web page is an HTML document. HTML (Hypertext Markup Language) is a special flavor of the more general SGML (Standard Generalized Markup Language), a generic document-description language that's been around since the 1980s. It's elegant in its simplicity, yet flexible enough to create powerful visual effects. Here's what the home page for Figure 1 looks like in HTML.
<html>
<head>
<title>The Webster Server</title>
</head>
<body>
<body background="sky.jpg">
<h1><center>Welcome to Webster's Home Page</center></h1>
<hr>
<h3>
<img src="uc.gif" alt="I'm under construction!" align="bottom">
Please contact the
<a href="mailto:msj-publ@mfi.com">Microsoft Systems Journal</a>
for more info...<p>
<center><i>or</i></center><br>
You may visit the Microsoft Systems Journal
<a href=http://www.mfi.com/msj/msjtop.html>Web Site</a>!<br>
</h3>
</body>
</html>Before I describe what it all means, look how small this file is: only 503 bytes! That's all the server has to transmit before the browser can display something. But despite its small size, this rather typical Web page illustrates some powerful HTML features. The line
<body background="sky.jpg">tells the browser to use the file SKY.JPG (on the current server) to tile the background. When the browser sees this, it requests the file from the server, then tiles copies of it on the background of the document window. Of course, the browser doesn't have to do that. You could write a browser with a configurable option like "Display background textures?", which, if the user set to No, would tell the browser to ignore background images and just display a flat background using the default window color (that is, GetSysColor(COLOR_WINDOW)). A little further down, the line
<imgsrc="uc.gif"alt="I'munderconstruction!"align="bottom">tells the browser to display the image UC.GIF bottom-aligned with the text that follows. The browser knows to initiate another server transaction to fetch the file UC.GIF. The alt= tag tells the browser to display the text "I'm under construction!"until the image arrives. Many browsers display a generic "image goes here" icon as a placeholder for images that haven't been retrieved yet.
The next two items of interest are references to other URLs. As you can see in Figure 1, the phrases "Microsoft Systems Journal" and "Web Site" have hotlinks. The first link
<a href="mailto:msj-publ@mfi.com"> refers to an email address. You can tell because the URL scheme is mailto, not HTTP. When the user clicks on "Microsoft Systems Journal," the browser knows to launch email with a new message to msj-publ@mfi.com. The second hotlink
<a href=http://www.mfi.com/msj/msjtop.html>refers to another HTML document at a completely different Web site. If the user clicks on "Web Site," the browser knows to initiate a transaction with the server www.mfi.com to request the file /msj/msjtop.html.
It's the browser's responsibility to underline or otherwise highlight the text associated with these references, detect when the user has clicked one of them, and take the appropriate action. HTML leaves room for browsers to interpret things. For example, the browser can use whatever font and attributes it wants to display both normal and highlighted text-or let the user choose.
I hope you can begin to see how powerful HTML is. You can create fairly sophisticated Web pages just using graphic images and hotlinks. The references can point to any kind of network resource, not just other HTML documents. There's a lot more I haven't shown you. HTML has tags for describing all kinds of binary data, data entry forms, and even techniques for executing applications independent of the Web server itself, capabilities that can be combined to yield some amazing results. I should warn you that HTML is a rapidly evolving standard. The current official version is 2.0; however, some Web browser and server manufacturers have proposed and implemented a number of draft extensions, which the Internet Engineering Task Force (IETF, the regulating body for HTML), is working to approve in version 3.0.
Now that you understand the overall roles of Web clients and servers, and know a little about HTML files, let's delve deeper into the details of how Web clients and servers actually communicate. HTML describes what is exchanged; HTTP describes how it's exchanged. More precisely, HTTP describesthe format of client requests and server responses.
Let's start with the client's request. An HTTP server needs to know two essential items: what information the client wants and what action to take on it. The what part of the request is usually an HTML document or a graphic file; the action (or "method") tells the server what to do with it. The most common method is GET, which simply transmits the resource to the client. Figure 3 shows some other methods. The resource name and method are the two most basic pieces of information in every HTTP request. A request that contains only these two items is sometimes called a simple HTTP request.
GET sky.jpgIn the old days of HTTP version 0.9, this is all you could do. Nowadays, almost everybody speaks HTTP 1.0, which lets clients supply additional information to tell the server more about the client's capabilities. Here's the full request that the Internet Explorer sends my Webster server to get the file SKY.JPG:
GET sky.jpg HTTP/1.0
Accept: image/x-xbitmap, image/jpeg, image/gif
Accept-Language: en
User-Agent: Microsoft Internet Explorer/
2.0beta [Windows 95]
Connection: Keep-Alive
Referer: http://dave95/
If-Modified-Since: Sun, 21 Oct 1995 19:25:23 GMTThe first line looks like an old-style version 0.9 GET request, with the addition of HTTP/1.0 at the end, which is the server's cue that this is a version 1.0 request, and contains additional lines that follow. A double carriage return or linefeed pair indicates the end of a response header. In this particular example, the Internet Explorer tells Webster that it can handle X-Windows bitmaps, JPEG and GIF image files, that it's an English-based system, that it's the Internet Explorer running on Windows 95, and that the request was made from the client machine named "dave95." The last line tells the server that it should only GET the file if it was modified since the date and time given. Explorer has already downloaded this file, and doesn't need to get a new copy unless it's changed.
During the course of a connect session, the extra header fields vary from transaction to transaction, but the purpose is always the same: to give the server as much information about the client as possible. If the server knows, for example, that the client can't handle TIF images, it won't bother sending any.
Once the server gets a client request, its job is quite simple: locate the resource and do what the client asked (servers aim to please, that's why they're called servers). In the case of the simple GET request, this means get the file called SKY.JPG and transmit it to the client. Assuming the file exists and the client has permission to see it, here's how Webster responds to the Internet Explorer's GET request.
HTTP/1.0 200 OK
Date: Sunday Sun, 21 Oct 1995 19:38:46 GMT
Server: Webster/1.0
MIME-version: 1.0
Content-type: image/jpg
Last-modified: Sun, 21 Oct 1995 8:07:14 GMT
Content-length: 3150Following this reply header, Webster transmits the 3150 bytes of binary data (as indicated in the Content-length field) in the file SKY.JPG. As with the client request, the first response line contains the most important information: whether the request succeeded or not. The first element identifies the response as an HTTP version 1.0 format, and the second element is the response status code. Following that is a text description of the status code, in this case "OK." Figure 4 shows some typical response codes and what they generally mean; Figure 5 shows how the codes are grouped.
The other lines in the reply header give additional information to help the client interpret the data. For example, the MIME-version and Content-type fields tell the client that data is of the MIME version 1.0 type "image/jpg" (a JPEG compressed image). The MIME (Multipurpose Internet Mail Extensions) standard defines a number of data types. RFC 1049 states that the Content-type should "describe the data contained in the body fully enough that the receiving user agent can pick an appropriate agent or mechanism to present the data to the user, or otherwise deal with the data in an appropriate manner." (Internet Request For Comment documents contain proposals for new standards (or the de facto standard), and your opinion is invited. You can access the RFCs at http://ds.internic.net/rfc/.) Figure 6 shows some common MIME data types. The MIME Content-type contains both a major type and a subtype. In the example, the major type is "image," indicating that the data is a picture of some sort; the subtype is jpeg, indicatingit'sinJPEGformat. Describing the information in advance spares the client the trouble of examining the data to render it. This makes for faster browsers.
The Last-modified field tells the client when the data was last changed, so it can decide whether to use information it might have cached locally, or wait to receive new data.
I've only described the GET method and some of the most common attributes found in Web requests and responses. Obviously, there's a lot more to HTTP than that. My purpose here is not to give a full treatment of HTTP, but only cut a swath deep and wide enough to write Webster.
While it's beyond the scope of this article to discuss them fully, I should at least mention some of the current extensions to HTTP, if only to keep you abreast of the latest acronyms. By itself HTTP only specifies the way static information is requested and delivered. With the demand for ever more interactive Web applications, Web gurus have invented a number of extensions. Strictly speaking, these protocols fall outside the definition of HTTP.
CGI, Common Gateway Interface, was the first and most primitive way of providing "server-side support." The client sends a number of parameters like NAME="Dave Cook", CreditCardID=1234-5678-0000-0000, and so on. The server uses these to set environment variables on the host, then runs a custom-written program (often a shell script on UNIX systems) that looks for these environment variables and does something with them. Environment variables were chosen as the means for parameter-passing because most operating systems support them in some form. The downside of passing information this way is that it's inefficient and a bit arcane, as each program must be written to accept certain predefined environment variables, and the client must know a priori what they are.
BGI, Binary Gateway Interface, provides another way of invoking a server process. Instead of setting environment variables, the server calls a program or DLL directly on the client's behalf. On a Windows-based system, a BGI implementation might be a DLL with a predefined API. The server, upon receiving a request for a BGI transaction, loads the DLL and calls the requested function with arguments supplied by the client. The Microsoft Internet Information Server (codenamed The Internet Information Server) handles BGI this way (see page 50). This implementation of BGI is defined as the Internet Server Application Programming Interface (ISAPI). It's more efficient than CGI.
Java is a programming language from Sun Microsystems that provides a general means to download applications from the server and run them on the client computer. Java uses a p-code implementation where each client has an interpreter that can run Java programs.
Another programming language, Netscape's LiveScript, is similar to Java, without Java's static typing and strong type-checking. LiveScript supports most of Java's expression syntax and basic control flow constructs. In contrast to Java's compile-time system of classes built by declarations, LiveScript supports a run-time system based on a small number of primitive types.
Now I'll show you how I wrote Webster in MFC (see Figure 7). Webster is an outgrowth of my own research into the Web. As I was exploring HTML, HTTP, URLs and transactions, the basics seemed surprisingly straightforward. It didn't seem like it would be all that hard to write a Web server. After all, the only thing a server does is sit around waiting for the phone to ring, and when it does, it transmits a file or two over the line. (Browsers, on the other hand are more complex: they have to display text and images, manage hotlinks, parse HTML files, and so on.)
To be sure, Webster is the Yugo of Web servers. It offers only minimal HTTP support with no frills. Webster only handles GET requests, and it doesn't do anything with most of the extra client information it receives, like the If-Modified-Since field. But Webster does illustrate the basic features common to every Web server, including very powerful servers like Microsoft Internet Information Server. IIS supports not only HTTP, but FTP and Gopher as well. Among the many capabilities IIS provides (and Webster lacks) are support for CGI and BGI, integration with database systems through ODBC, and extremely robust, high-performance service. But Webster is good enough to present your very own real live Web home page, and it does run on both Windows 95 and Windows NT, unlike IIS, which only runs on Windows NT.
Before getting deep into the nitty-gritties, let's take a quick look at what Webster does. Figure 8 shows the main Webster screen, which displays status information about client connections. Generally speaking, server applications don't require much in the way of a user interface. All Webster has to do to fulfill its mission is process client requests and keep a log of transactions. But I wanted to monitor Webster's activities, so I gave it a face. (I considered implementing Webster as a Windows NT-based service application, but then I wouldn't have been able to run it in Windows 95.)
Figure 8 Webster
Let's go over its UI first. Since Webster doesn't support multiple documents (in fact, it doesn't really have any notion of documents at all), I wrote it as an SDI app. The main view is a scroll view with a splitter window to allow comparing messages in different areas of the list. Webster displays an icon in the Windows 95 system tray that indicates it's running, and whether there are currently any clients active.
A Configuration dialog lets the network administrator (that's me) set various options, such as the default home page, HTTP port number and maximum number of connections allowed, among other things (see Figures 9 through 13).
Figure 9 Configuring Webster
Figure 10 Setting the default page
Figure 11 Enabling logging
Figure 12 Setting HTTP part number
Figure 13 Output status information
While it's always nice to have a good UI, don't forget that as a service provider, Webster's priority is to get information quickly to clients. Recordkeeping comes second. The userinterface-thatis,thereal-time display of ongoing service transactions-is Webster's least important activity.
When building apps with MFC, it sometimes takes a little imagination to figure out what the document is in the doc/viewmodel. Webster has no notion of documents the way a word processor, spreadsheet,or Scribble program does. It merely displays information about client transactions. The document in this case is the collection of clients connected at any given time; the view is a representation of what's going on with those connections. Figure 14 shows the major C++ classes I used to implement Webster, and how they fit into MFC's application framework.
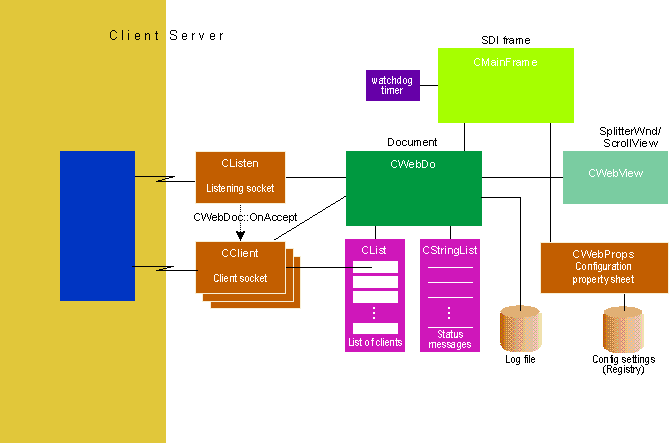
Figure 14 Webster Architecture
CWebDoc manages a list of clients, a list of status messages, and writes information to the log file. Since Webster is a SDI app, there's only one CWebDoc.
CWebView displays the messages in CWebDoc's list. Derived from CScrollView, CWebView permits scrolling to previous messages.
CListen is a socket class (described below) that listens for new clients. It handles the initial connection request on port 80. When the document accepts the connection, it creates a new CClient object and adds it to the list of connected clients. CListen continues to listen for new clients.
CClient is a socket class that manages a client transaction. CClient parses the request, retrieves the file, and transmits it to the client. There's one CClient object for each transaction currently in process, and these objects live only for the duration of a single transaction.
CMainFrame is a standard CFrameWnd with toolbar, status bar, and a splitter window (CSplitterWnd). It also manages a "watchdog timer" that periodically checks for nonresponding clients. CMainFrame also runs the CWebProps dialog when a user invokes the Configuration command.
CWebProps is a CPropertySheet that implements the configuration dialog.
Not shown in Figure 14 is CWebApp, the application class whose member functions read and write the configuration to the system registry when Webster starts up or shutsdown.
There's more code in Webster than I have space to describe fully in these pages, so I'll focus mainly on networking issues since that's what this article is all about. Most of the interesting stuff happens in CWebDoc, CListen, and CClient. I leave it to you to divine the rest from the source code, which you can download in toto from any of the sources listed on page 5.
At the bottom of the software chain in any network program are the communication layers that ship bits and bytes through your modem or network card and out onto the net. Web technology was first developed on UNIX systems, where the normal way of accessing the network is through the Berkeley Sockets interface. Sockets provide a relatively high-levelAPI to TCP/IP, with functions like connect, accept, send, recv, and so on. Windows provides an equivalent interface in the form of Windows Sockets. WINSOCK is the DLL that implements Windows Sockets. WINSOCK 1.1 provides the same functions as Berkeley Sockets, plus additional extensions specific to Windows 95. For example, WINSOCK notifies applications of communications events by sending messages to your window proc, instead of using the UNIX signal mechanism.
While using sockets is a lot easier than programming your network card directly, it still requires a good bit of programming. This is where MFC comes to the rescue. Starting in version 3.0, MFC provides a couple of classes that make sockets a breeze (see Figure 15). CAsyncSocket is the base socket class. It hides most of the tedious and sometimes complex work of managing the WINSOCK interface. Instead of writing a window proc to handle messages from WINSOCK, you handle events by overriding virtual functions like OnConnect, OnReceive, OnClose, and so on. An even simpler derived class, CSocket, provides a synchronous implementation that's ideal for programs like Webster. CSocket uses blocking to perform synchronous transfers using CArchive and a CFile-derived class, CSocketFile, so you can use normal streaming operations to send and receive data over the net. The definitions for these classes appear in AFXSOCK.H, which AppWizard automatically #includes for you if you check "Windows Sockets" under "WOSA Support" when you run AppWizard.
Figure 15 MFC Socket Classes
CObject Classes | ||
CAsyncSocket | Asynchronous socket class thatencapsulates WINSOCK. Base class for all socket classes | |
CSocket | Synchronous easy-to-use socket class provides blocking to work with CArchive and CSocketFile. | |
CFile Class | ||
CSocketFile | CFile-derived clas that works with CSocket and Carchive for streaming objects to/from sockets. | |
I used the CHATSRVR sample program that comes with Visual C++ as a guide in designing my socket classes. While CHATSRVR uses CSocket differently than Webster, it does illustrate how to write your own CSocket-derived class. In Webster,therearetwo:CListenlistensfornewclientconnectionsandCClientmanagesclienttransactionsoncethey're accepted. There's only one CListen object, but there may be several CClient objects, one for each transaction in process.
To see how the socket classes work in practice, let's step through a typical client request, the Internet Explorer's GET request for SKY.JPG. (In the excerpts that follow, I've omitted much of the code to highlight the important details.) When Webster starts up, MFC creates a new document per its usual mechanisms, and calls CWebDoc::OnNewDocument.
BOOL CWebDoc::OnNewDocument()
{
if (!CDocument::OnNewDocument())
return FALSE;
OpenLogfile();
// create one and only listener socket object
m_pSocket = new CListen(this);
if (!m_pSocket)
return FALSE;
// create socket on port m_wwwPort, default=80
if (!m_pSocket->Create(GetMyApp()->m_wwwPort)) {
.
. // (handle error)
.
return FALSE;
}
// start listening for requests
BOOL ret = m_pSocket->Listen();
.
.
.
return ret;
}As with CWnd objects, you create a socket by first creating the object with new, then calling CSocket::Create with the port number. Once you've created the socket, you can call CSocket::Listen, at which point the socket is ready for requests from clients. Pretty easy, huh?
When an HTTP client requests a connection to Webster on port 80, it arrives through the bowels of WINSOCK and CSocket to my virtual function CListen::OnAccept.
// CSocket virtual function override
void CListen::OnAccept(int nErrorCode)
{
CSocket::OnAccept(nErrorCode);
m_pDoc->OnAccept() ; // let doc process it
}CListen simply passes the job to CWebDoc, which creates a new CClient object, calls CSocket::Accept to accept the connection, and adds the new client to its list:
void CWebDoc::OnAccept()
{
.
.
.
// create new client object
CClient *pClient = new CClient(this);
if (pClient==NULL) {
Message(">> Unable to create client! <<\n");
return;
}
// Accept the connection
if (!m_pSocket->Accept(*pClient)) {
Message(">> Unable to accept connecton! <<\n");
delete pClient;
return;
}
.
.
.
Message("Connection accepted!!!\n");
m_listConnects.AddTail(pClient);
}Throughout the operation, CWebDoc calls its own member function CWebDoc::Message to append status messages to its list, which will be displayed by CWebView. At this point, CWebDoc has done its job, and goes back to waiting for either another connection request (from CListen), or notification that the transaction is complete. From this point on, CClient manages the transaction.
Once the connection is accepted (by calling CSocket::Accept), the client can transmit its GET request. When it does, the event percolates up through WINSOCK and CSocket to another virtual function override, CClient::OnReceive.
void CClient::OnReceive(int nErrorCode)
{
CSocket::OnReceive(nErrorCode);
if (ProcessPendingRead()) {
ProcessReq() ; // process the request
m_bDone = TRUE ;
if (GetMyProps()->m_bLogEnable)
m_pDoc->WriteLog(m_LogRec);
m_pDoc->KillSocket(this);
}
}CClient::OnReceive calls ProcessPendingRead to read the request. Since not all clients (such as Telnet-see below) transmit the whole request in one fell swoop, it may arrive piecemeal, as several OnReceive notifications. ProcessPendingRead accumulates incoming data into a buffer until the entire request arrives. When it does, CClient calls ProcessReq to process it.
void CClient::ProcessReq()
{
ParseReq(); // parse it // can only handle GETs for now
if ( m_nMethod != METHOD_GET ) {
.
. // error
.
return;
}
.
.
.
SendFile(m_cLocalFNA, m_cURI);
// (filename, directory)
.
.
.
SendTag(); // Done!!!
}ProcessReq calls ParseReq to parse the request, that is, split it into its method and URL. ParseReq also stores additional header lines in a holding list, where they'll be used later to prepare the response. After parsing the request, ProcessReq checks for a valid URL and a supported method. Assuming the URL is valid and the method is GET, ProcessReq calls SendFile to transmit the file.
void CClient::SendFile(CString& cLocalFNA,
CString& BaseFNA)
{
CFile cFile;
.
.
.
cFile.Open(cLocalFNA,
CFile::modeRead|CFile::typeBinary);
.
.
.
m_pDoc->VMessage(" Sending: %s\n", cLocalFNA);
SendReplyHeader(cFile);
SendData(cFile);
cFile.Close();
}SendFile opens the file using the normal MFC CFile class, and passes it to SendReplyHeader, which formats and transmits an HTTP 1.0 response header:
HTTP/1.0 200 OK
Date: Sunday Sun, 21 Oct 1995 19:38:46 GMT
Server: Webster/1.0
MIME-version: 1.0Following this, SendFile calls SendData to finally transmit the file. This is where the MFC classes really makes life easy.
void CClient::SendData(CFile& file)
{
char buf[BUF_SIZE];
int nBytes;
CSocketFile sockFile(this, FALSE);
while ((nBytes=file.Read(buf,BUF_SIZE))>0) {
TRY {
sockFile.Write((LPVOID)buf,nBytes);
} CATCH(CFileException, e) {
.
.
.
} END_TRY
}
sockFile.Flush();
}CSocketFile makes writing to a socket look like writing to an ordinary CFile. To transmit the bytes, I just read them from one file, and write them to another "file," which is actually the socket.
As control unwinds from the depths of the call stack, it eventually returns to ProcessReq, which calls SendTag to append an HTML tag that identifies "Dave Cook Consulting" as the sender (it always pays to advertise), and from there back to CClient::OnReceive, from whence the whole business started.
OnReceive calls m_pDoc->KillSocket to notify the document that the transaction is complete. CWebDoc::OnKillSocket removes the CClient object from its list and, with a mighty sigh of contentment for a job well done, deletes it. Whew!
As you can see, while developing Webster, I traveled to some of the farthest reaches of the MFC universe. One problem I came across initially was a mysterious assertion failure when I tried to create a new CClient object. The error only manifested itself on Windows 95. I was told by someone in the Microsoft Languages Product Support group that this was a race condition that's been corrected as of the MFC 4.0 release. However, as a precaution to those of you who might still be using version 3.x, and just to give you some idea of the complex shenanigans that go on behind the scenes in network programming, I thought I'd describe my workaround.
In brief, MFC maintains a map of "dead" sockets, those that were once open and now closed. If an application closes and opens sockets in the same thread, without yielding to give Windows a chance to process messages, it's possible an attempt will be made to close a socket that's already been closed, because the thread doesn't know it yet (it hasn't gotten the message). In version 3.x, MFC doesn't properly handle this because it can have only one entry in its dead sockets map. MFC dies asserting that there isn't already an entry in the map. The simple workaround is to include the following snippet of code in CWebDoc::OnAccept, just prior to creating the new CClient object.
// Just before creating a new CClient:
#if _MFC_VER < 0x400 // problem fixed in MFC 4.0
#include "afxpriv.h" // WM_SOCKET_xxx
MSG msg ;
while (::PeekMessage(&msg, NULL,
WM_SOCKET_NOTIFY, WM_SOCKET_DEAD, PM_REMOVE)) {
::DispatchMessage ( &msg );
}
// Ok, any dead sockets pending destruction
// have been dealt with. It's safe to create
// the new client socket now.
#endif // _MFC_VER < 0x0400I simply peek into the message queue to process any outstanding messages in the range from WM_SOCKET_NOTIFY to WM_SOCKET_DEAD, which is all socket messages (there are only two). This gives MFC a chance to clean up any dead sockets before I create a new one.
Back in the days when I wrote device drivers for a living, one of my mentors gave me a sage bit of advice: "Device drivers are perfect code." The implication is that driver code must be perfect, or else it may crash the system. While a Webster crash won't bring down Windows 95, it would be quite disconcerting to a client if Webster dies in the middle of a transaction, so it's important to make the code as robust as possible.
That said, I must confess with some chagrin that in the interest of building an educational tool that demonstrates basic HTTP and client/server transactions, there are many places where I simply punted on error checking and recovery. You have been warned!
While I didn't make Webster totally bulletproof, I did install an important feature I call the "watchdog timer." Because Webster relies on clients to behave properly, it can get trapped in an unusual state if they don't. For example, if a client makes a request, but fails to read the reply, Webster would hang waiting for CSocketFile::Write to complete. To prevent such mishap, I implemented the watchdog timer. CMainFrame creates an ordinary Windows timer to go off periodically. If a client goes idle too long, CMainFrame will detect it and simply delete the client socket, closing the connection. The timeout value is specified as part of the server configuration.
The status window provides real-time information about the activities of the server. A simple function, CWebDoc::Message, appends status messages to a list; to display them, I implemented my own simple buffered text view based on CScrollView. CWebView::OnDraw uses CDC::TextOut to draw the messages on the screen. The displaying of messages doesn't impede Webster's other activities, since Windows only sends a WM_PAINT message when there are no other messages in the queue. As an enhancement to CWebView, you might add a graphical display to show client activity intheformofahistogram.
In addition to real-time display, Webster also writes information about each transaction to a log file:
CWebDoc writes this information in the standard Common Log Format. It's tempting to include additional tidbits of information in the log file, but the purpose of the log is to store the minimum information necessary for accounting purposes. You don't want to burden your server with excessive logging requirements. Most facilities use utility programs to parse the log file and generate more useful statistics, such as activity mapped by time of day, most frequently requested files, and so on.
CClient accumulates log information as it processes the request. Before killing the client, CWebDoc extracts the log information, formats it, and writes it to a file WEBSTER.LOG.
Webster stores its configuration in the Windows system registry (see Figure 16). CWebApp provides member functions LoadProps and SaveProps to read and write the configuration. CWebApp::InitInstance contains the line
SetRegistryKey (IDS_REG_STRING)which tells MFC to use the registry, not WEBSTER.INI, when I call CWinApp::Get/WriteProfileInt and Get/WriteProfileString. IDS_REG_STRING is the resource ID of the string "Dave Cook Consulting." By convention, software settings are stored in the key HKEY_CURRENT_USER\Software\YourCompanyName.
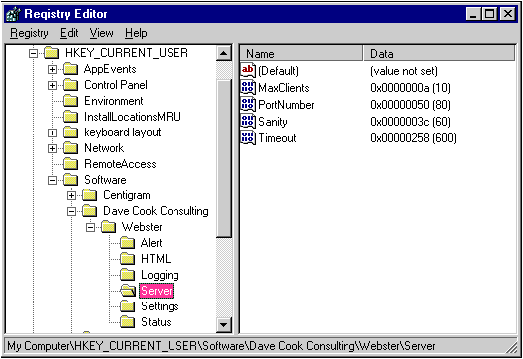
Figure 16 Saving Webster's configuration
As mentioned earlier, to edit the configuration settings, I implemented a property sheet dialog with tabs for Server, HTML, Logging, Status, and Alert (see Figures 9 through 13). The implementation is a straightforward application of CPropertySheet and CPropertyPage, so I won't bore you with the details.
Once Webster is built and compiled, going live on the Internet is surely tempting, but unwise. You might blast away your connection and your reputation along with it. So the first thing you should do before running Webster is unplug your computer from the network. If you're using a dial-up connection, just unplug the phone line from your modem; if you have a dedicated line, unplug the cable from your network card.
With your system disconnected, it's safe to launch Webster. Assuming it comes up OK, the first thing you have to do is configure your system. The Configuration dialog contains several property pages that let you set various options. The most important one is the HTML page, which lets you set the default HTML file and directory. This is the file that Webster will send if the client doesn't know what your home page is called. For example, if I connect to http://www.microsoft.com with my Web browser, the HTTP server at that location must be configured to provide a default HTML file, since none was specified in the URL. This is called a blind request. The default HTML file provides a top-level page for the host system. Typically, it contains links to other resources on the host. Some HTTP servers make you use a hardwired name like default.htm, but Webster lets you use any name you want. Make sure you set it to a valid HTML file on your computer, or else clients will get the dreaded response "404 - Requested URL not found." You also need to set the home directory, which becomes the root directory for all file requests.
I leave you to explore the other property pages on your own. Most of it is self-explanatory. One item worthy of note is "Enable Client Name Lookup" in the Status page. This feature, if checked, enables translation of client IP addresses (such as 198.68.184.240) to more human-readable domain names (such as davepc2.oz.net). Because name translation incurs significant processing delays (it requires searching the local host name database and/or contacting a Domain Name Server system), this option is usually left disabled.
Once you've configured Webster, how do you test it without going live on the net? One of the really useful features of TCP/IP is the local loopback address, which lets your machine talk to itself as if it were both client and server. Every machine has something called a hosts file that lists the names and IP addresses of hosts on the local network. On Windows NT, the hosts file is in \winnt\system32\drivers\etc. On Windows 95, it's in the \windows directory. Apps use the hosts file to resolve TCP/IP domain names into IP addresses. Even if all you have is a standalone machine running Windows 95 with dial-up networking, you have a hosts file. And within every hosts file is a silly little entry that looks like this:
127.0.0.1 localhost loopbackThis entry is a special IP address that lets your machine talk to itself without a network. You can run a browser like the Microsoft Internet Explorer, request a connection to 127.0.0.1, and WINSOCK will convey the request to whatever server software is running on your machine, as if it came from a remote client. This is just the ticket for debugging network apps like Webster. Just launch Webster, then start the Internet Explorer, type 127.0.0.1 into the Address field at the top of the window and, with any luck, Webster will respond. If not, here are some things to check.
If Webster crashes or says it can't run, make sure you have TCP/IP installed as a network protocol. Run Network from the Control Panel and look for TCP/IP as one of the installed components (see Figure 17). If TCP/IP doesn't appear, click Add, and Windows will step you through the installation.
Figure 17 Check for TCP/IP install
Make sure you have the correct version of WINSOCK.DLL, the one that came with your version of Windows. Some commercial browsers install older versions of WINSOCK.DLL on your machine.
If you get "Error 404 - URL not found," make sure the default HTML file and directory are set correctly in the configuration dialog. You can check the validity of your HTML file by viewing with your Web browser. Most browsers let you view HTML files directly. The server provides access to all files from the default HTML directory and subdirectories. Because the server runs as a local app, with all the requisite permissions, no additional file permission or privilege settings are required to access these files. Keep in mind that any file in this directory or its subdirectories is potentially available to clients if they know what to ask for.
If you're still having trouble, enable debug messages in theConfiguration/Statuspropertypage.I'vesprinkled debug messages throughout the code; you can add more.
Another useful debugging technique that deserves special mention is Telnet. Telnet is a character-oriented communications facility that comes with Windows 95 and Windows NT. Typically, it's used to log onto remote systems as a terminal emulator. You can use Telnet to type HTTP requests manually, and see what comes back from the server. Telnet doesn't operate like a trueWebbrowser.For one thing, it transmits a single character at a time, instead of a whole block. This makes Telnet pretty slow and clunky, but it's invaluable for debugging.
Just run TELNET.EXE, select "Connect Remote System" and type 127.0.0.1 as the host name and 80 as the port (see Figure 18). You also want to invoke "Terminal Preferences" and check Local Echo, otherwise you won't be able to see what you type. Once you've done all this, just type
GET / HTTP/1.0and press the return key twice (to indicate the end of the request). You should be able to see Webster's response, as in Figure 19. During my Web research, I used Telnet to snoop inside various servers. Just connect to your favorite Web site and type a request
GET somedoc.html HTTP/1.0and see what comes back.
Figure 18 Host name and port
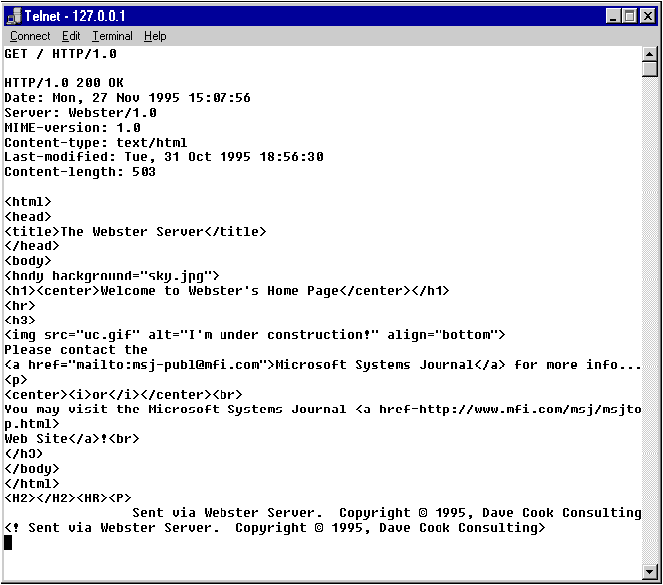
Figure 19 WEBSTER's response
Assuming all the preceding steps check out OK with no cause for alarm, and you're able to issue a request with Telnet, it's time to take the big plunge and go live on the network-yikes! Just plug your cable or phone line in and run Webster. Of course, nothing particularly exciting will happen. Remember, Webster doesn't actually do anything until a client requests something.
I hope this brief exploration into the Web helps you appreciate the elegance and simplicity of what takes place when you connect to your favorite Web site. As HTTP and HTML continue to evolve, you may wish to try new capabilities by adding them to Webster. Among the many features I've considered adding to Webster are: multithreading, CGI and BGI support, "keepalive" connections, and cool graphics for the status display. I leave these exercises to you and your imagination. Happy Web serving!
Webster works great for a bare-bones server. But what if you want to do something more sophisticated than put baby pictures of your son on the Web? Microsoft is currently beta testing its Internet Information Server (IIS) software, codenamed Gibraltar, which it plans to ship first quarter 1996. The Internet Information Server runs as a Windows NT Service on all Windows NT Server 3.51 hardware platforms (Intel, MIPS Alpha, and PowerPC). The Internet Information Server can turn you into a Webmaster, giving you full control over all aspects of a site's configuration. You can set virtual roots, which allow one machine to look like several different machines to clients. You get Secure Sockets Layer (SSL) support and the ability to grant/deny WWW access based on IP address. There are a number of logging features that you can choose from, such as the ability to log data directly to an ODBC data source like Microsoft SQL Server. You can also perform remote administration of a site, monitor performance through the Windows NT Performance Monitor application, and even support other protocols such as FTP and Gopher. The security accounts (and the tools to manage them) used by Internet Information Server are the same as those in Windows NT Server. In addition, Internet Information Server lets you extend your server's capabilities through a rich set of new programming interfaces including the Internet Server API (ISAPI) as well as older interfaces such as CGI (Common Gateway Interface).
Flat Web pages are on the way out. They'll be replaced with real-time services. Through ISAPI, your Web page can load a DLL extension when it starts up. If the DLL provides named functions HttpExtensionProc and GetExtensionVersion as common entry points, your HTTP server can load it using ISAPI. Unlike CGI, the current default standard for interactive Web services, ISAPI modules are DLL-based, so they're loaded directly into the HTTP server's address space, removing the need for the layer of environmental variables that CGI uses for communication. More importantly, ISAPI does not require that a new process be created for each new request. ISAPI is designed to be flexible for the content provider, so beyond the named export there is no limitation on what sort of information might be requested from it-data is passed as byte arrays. With ISAPI as the gateway, your Web server can request back office information and convert it from an unreadable format into the format the client can understand.
As just one example, your HTTP server might want to provide current temperatures for a city of the client's choosing. If the client chooses Chicago, HTTP would reference http://scripts/weather.dll?Chicago. The server in turn would load WEATHER.DLL and call its exported HttpExtensionProc, passing it a pointer to an ECB (Extension Control Block), a structure containing the context for this request, including the URL and other parameters passed from the client's browser. The ISAPI-compliant DLL will then have all the information it needs to proceed, retrieve the current temperature for Chicago from whatever data feed it knows about, and return the proper data by calling a function provided by the server.
IIS and ISAPI together will provide numerous possibilities for the corporate site. Right now, companies are tenuously testing out the Internet because they're unsure what benefits it really holds. Most current corporate Web sites are little more than online marketing brochures. Combine the flexibility of real-time data services with the C2-security provided by the Windows NT Access Control Lists, and you can go far beyond brochures. Internally, an "Enterprise-Wide Web" can act as a form of extended groupware. Users will be able to not only join in discussion pages and retrieve information on a need-to-know basis, but they'll be able to maintain sites that are instantly updatable via back office tools.
BGI | Binary Gateway Interface; a way of calling a binary process on the server machine. |
CGI | Common Gateway Interface; a way of running programs on a server machine, passing in environment variables. |
FTP | File Transfer Protocol for shipping files from one Internet machine to another. |
GIF | Graphic Interchange Format used to tranfer graphic images |
Gopher | A protocol for distributed document navigation. |
HTML | HyperText Markup Language is the document format used to describe Web pages. |
HTTP | HyperText Transfer Protocol is the message protocol that Web clients and servers use to talk to one another and exchange information. |
ISAPI | Internet Server API; binary gateway interface for Microsoft Internet Information Server. |
Java | A Web programming language. Java clients can download Java programs from the server and run them on the client machine. |
JPEG | Joint Picture Experts Group is a format for compressing graphic images. |
MIME | Multipurpose Internet Mail Extensions is a standard for describing different kinds of information that can be exchanged over the net. |
RFC | Request for Comment documents describe or propose new standards. Internet users are free to submit comments/suggestions/gripes. |
TCP/IP | Transmission Control Protcol/Internet Protocol is the basic communications protocol used by the Internet. Strictly speaking, TCP/IP is a suite of network protocols. |
URL | Universal Resource Locator is a way of addressing servers, files, Web sites and other "resources" on the Internet. |
WAIS | Wide Area Information Server is a standard for content indexing and information retrieval. |
For many people, just getting connected to the Internet is a big enough hurdle, forget about becoming a Web site as well. There are so many service providers promoting easy access to the information highway that it can be quite confusing to newcomers. For browsing, most people use dial-up modems to connect to an Internet Service Provider (ISP) when they want to access the net. But to become a server (and use Webster), you need direct access to the Internet. That means your computer is communicating live on the Internet, using the TCP/IP protocol. If you're using a modem, this means that you have dialed your ISP number and are connected.
With a direct access connection, your computer has a unique 32-bit IP address in the standard Internet dotted format. For example, my IP address is 198.68.184.240. Your ISP will assign your IP address and help you get connected. Windows NT supports dial-up networking through an ISP with its Remote Access Service (RAS), which also comes with the Windows 95 Plus! package. If you go this route, I recommend you get a modem capable of transmitting at 28.8Kbps. You'll have some unhappy clients if you make them suffer while your modem struggles to ship JPEG files over the line at 1200 baud.
The other connection option is a dedicated line. You may be lucky enough to have a dedicated Internet connection at your job or university. If so, your network administrator can help you set up your IP address.
However you get it, your IP address goes into a giant distributed database called the DNS (Domain Name System) that resides on several servers throughout the Internet. Applications use this database to convert domain names like davepc2.oz.net to IP addresses like 198.68.184.240. It's surprising how much of the overall Internet activity is spent just looking up these names-around six percent of transactions.
Once you've established your presence on the Internet via a direct access connection, your computer can act as an Internet host. In addition to accessing other host computers, you can provide network services yourself. You can run the Webster HTTP server described in this article, or some other Web server, and anyone in the great World Wide Web can view your home page using their favorite browser.
What can you do if you want a home page, but don't have access to a direct Internet line, and don't want to leave your phone off the hook twenty-four hours a day? Most ISPs have a Web server running on their system, and will grant you a modest amount of disk space as part of your basic service package. You can simply give them your HTML files (over the net, of course), and let their server do the work.
From the February 1996 issue of Microsoft Systems Journal.