April 1996
![]()
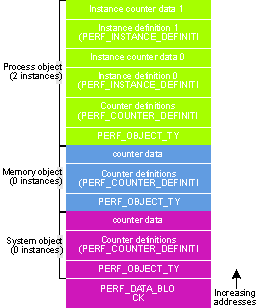
Matt Pietrek is the author of Windowsâ 95 System Programming Secrets (IDG Books, 1995). He works at Nu-Mega Technologies Inc., and can be reached at 71774.362@compuserve.com. In last month's column, I began describing the Windows NTÔ performance data, and presented some basic C++ classes to acquire the data. However, because the Windows NT performance data is convoluted (to put it mildly), I deferred a description of the performance data format. This month, I'll describe what the performance data looks like and provide the remaining classes that let you access it from within a C++ program. Before I jump into the performance data format, a quick review of last month's column is in order. The Windows NT performance information lets you query Windows NT for information such as process and thread lists, memory-paging statistics, and the cache hit rate. All of this information is stored in the HKEY_PERFORMANCE_DATA key of the registry. To handle the messy details of querying the registry for performance information, last month's column included the CPerfSnapshot class. I use the term "snapshot" because the performance data is only guaranteed to be valid at the instant you call RegQueryValueEx. Even as you're parsing the data in your code, portions of the data may become invalid. For example, a thread may terminate, so the thread list would be partially wrong. The CPerfSnapshot class is really just a container for holding the raw performance data, and has very little knowledge of what the data means. The classes I'll give this month let you parse the data in a relatively straightforward fashion. The other class from last month is the CPerfTitleDatabase class. In the performance data, many names such as "Process" or "File Read Operations/sec" are stored as integer indices rather than as actual strings. For instance, on my system, an index value of 230 corresponds to the string "Process". The CPerfTitleDatabase class takes care of reading the name strings from the registry, and converts indexes to strings and vice versa. As I described last month, whenever you query for performance data successfully, you get back a variable-length mass of data; the only thing you know for sure is that the data starts with a PERF_DATA_BLOCK structure (defined in WINPERF.H). The CPerfSnapshot class encapsulates this data structure. It's all the stuff that comes after the PERF_DATA_BLOCK structure that makes the performance data look convoluted. In working with the performance data, I have a mental model of the performance data that helps me keep everything straight. This model is somewhat like a directory/file hierarchy. The classes I'll provide this month mirror this hierarchy. Like a file system hierarchy, there are first/next methods for navigating the hierarchy. At the top of the hierarchy is what I call the "object list." Whenever you acquire a performance snapshot, the data contains an object list with zero or more objects in it. When you ask for a particular kind of performance data (such as the thread list), you may get more objects than you requested. In the case of requesting a thread list, you'll also get information about the processes the threads belong to. For this reason, the object-list class has enumeration and lookup functions you must use to access the particular object you're interested in. What are these objects? In the sense of Windows NT performance data, objects include "Process", "Thread", "Memory", "Processor", "Physical Disk", "Redirector", and several others. It's important to understand that an object may itself be a list. For example, the process object doesn't mean just one particular process. Rather, the process object means the list of all running processes. Likewise, the processor object is a list, since multiprocessor machines have more than one CPU. On the other hand, the memory object obviously isn't a list. Moving down yet another level, object lists contain zero or more object instances. For example, the process object contains as many object instances as there are processes in the system. Thus, the process object itself isn't that interesting. It's the object instances within the process object that contain the useful information. If the difference between objects and object instances is confusing, don't worry. It took me awhile to grok it, too. If the Windows NT performance data were simple, you'd think that each type of object instance (like a process object instance) would have a well-defined format from which you could just pluck the information you need. Alas, this isn't the case. The individual bits and pieces of information about an object instance aren't located in fixed locations within the object instance. Instead, each object instance contains one or more "counters" tacked onto the end of its data. A counter is like an attribute of an object instance. For a process object instance, the counters include the process ID, the number of threads, the percentage of time spent in privileged operating system code, and so forth. (Yes, in some cases, the term "counter" is misleading.) For a thread object instance, the counters include the thread's priority and the ID of the process it belongs to. Getting at the counters for a particular object instance is tricky because only the raw counter data is stored at the end of each object instance; the information that explains the raw data is located elsewhere. A portion of the data for an object list (not an object instance) is a list of all the counters that apply to the object instances that follow. Returning to the process object example, part of its data is a list of counter descriptions. The counter descriptions can then be used to interpret the raw data in each of the process object instances. Think of the counter description as a structure definition; each object instance has a copy of the structure tacked on to its end. Before I describe the C++ classes I used to wrap up this lovely mess, I'll recap the object list description, this time tying it to structure names from WINPERF.H. The performance data starts with a PERF_DATA_BLOCK structure, which tells you how many performance objects are in the object list. Following the PERF_DATA_BLOCK structure is the actual object data. Each object starts with a PERF_OBJECT_TYPE structure. Each object in turn contains zero or more object instances. Each object instance begins with a PERF_INSTANCE_DEFINITION structure. Besides containing a list of object instances, each object also describes one or more counters. The counters describe the data that ends each object instance. Each counter definition is a PERF_COUNTER_DEFINITION structure. As a final theoretical note before going to the code, I want to clear up the issue of objects that don't have object instances-like the memory object. These objects still have counters. However, the counters don't describe the raw data at the end of an object instance. Rather, the counter definitions describe the data at the end of the object itself. Part of a counter definition is the offset of the raw counter data from the end of an object instance. In the case of an object without instances, the counter offsets are relative to the end of the counter descriptions. Figure 1 shows a hypothetical performance snapshot. It starts out with a PERF_DATA_BLOCK header. Following the header are three performance objects (a system object, a memory object, and a process object). Each object starts with a PERF_OBJECT_TYPE header. The two objects (system and memory) that don't have object instances end with counter definitions (PERF_COUNTER_DEFINITION) followed by the counter data. The process object also has PERF_COUNTER_DEFINITION's, but they are followed by two process object instances (the PERF_INSTANCE_DEFINITION structures). Figure 1 Performance Snapshot Data Structure The classes I wrote to encapsulate the complexity of all these variable-length structures correspond closely to the structures in WINPERF.H. Each class includes enumeration and lookup methods that return pointers to class instances of the type logically below it in the hierarchy. For example, the performance object class has methods that return pointers to object instance classes. The one exception is that the performance object class doesn't have a lookup method. This is because there could be multiple performance object instances with the same name, and the lookup method wouldn't know which instance to return. As you look up or enumerate the lower-level classes, you'll get back pointers to instances of the lower-level classes. It's your responsibility to delete them when when you're done. This model is different from typical find first/next functions where you supply a structure which is filled with information. The model my classes use is more like OLE: when you create an OLE object, you get back an interface pointer, and the interface has a reference count of 1. You need to call IUnknown::Release explicitly to free the object. Deleting the object pointers in my classes is similar to calling IUnknown::Release in OLE. Working our way from the top down in the hierarchy, the first class we come to is CPerfObjectList, located in OBJLIST.CPP and OBJLIST.H (see Figure 2). CPerfObjectList provides access to the various performance objects embedded in the performance snapshot. The CPerfObjectList constructor expects a pointer to a CPerfSnapshot class (which I described last month), as well as a pointer to a CPerfTitleDatabase class. The title database is needed to look up a particular performance object (such as "thread") by name. The CPerfObject class is the only class described this month that you create explicitly, and thus is the only class that you need to know the constructor parameters for. The GetFirstPerfObject and GetNextPerfObject methods of the CPerfObjectList class allow easy enumeration of all performance objects in a snapshot. They both return a pointer to a CPerfObject. Alternatively, if you know exactly which kind of performance object you're after, you can use CPerfObjectList::GetPerfObject(name), which also returns a CPerfObject pointer. Regardless of which you use, the function locates the appropriate PERF_OBJECT_TYPE (a WINPERF.H structure) within the snapshot data and uses it to create a CPerfObject. The CPerfObject (PERFOBJ.H and PERFOBJ.CPP, see Figure 3) has the GetFirstObjectInstance and GetNextObjectInstance methods for enumerating the object instances within a performance object. For each instance, the methods return a pointer to a CPerfObjectInstance. If the object doesn't have instances, the GetFirstObjectInstance method fakes a single instance. As you might guess, CPerfObject::GetObjectInstanceCount returns the number of object instances the object contains (for example, how many threads are in the thread object). If the object doesn't have instances, the method returns -1 (see PERF_NO_INSTANCES in WINPERF.H). The CPerfObject::GetObjectTypeName method returns the name of the object ("Process", "Thread", and so on). This method uses the title database to convert the object's title index into a readable string. As the CPerfObject methods enumerate the instances, they return pointers to CPerfObjectInstance objects. (The CPerfObjectInstance code is in OBJINST.H and OBJINST.CPP-see Figure 4). Since each object instance has a name, the class includes the GetObjectInstanceName method for retrieving this data. If you were enumerating the process list, you could use this method to find the name of each process. CPerfObjectInstance::GetFirstCounter and GetNextCounter return pointers to CPerfCounters. If you know the name of the desired counter, use GetCounterByName instead; this method takes a readable name (such as "Working Set") so you don't have to pass the counter's index value (such as "180"). Finally, we come to the lowest level in the hierarchy: CPerfCounter (PERFCNTR.H and PERFCNTR.CPP-see Figure 5). This class represents one unit of information about one particular performance object instance. GetName returns the counter's name, which originally started out as a string in the title database. GetType returns the DWORD value that describes the size of the counter and how it should be interpreted. WINPERF.H defines all the gory bitfield encodings for this DWORD. (Calling the counter-type bitfields Byzantine is an understatement.) CPerfCounter::GetData retrieves the raw data associated with the counter. It also returns the counter's type DWORD. The final method, CPerfCounter::Format, hides all the counter format variations. Simply pass it a buffer pointer, and Format fills it with a string that represents the value. Format does something reasonable with all the various counter types I encountered, but doesn't support every known type in WINPERF.H. The third argument to Format is a default argument that specifies whether Format should display the number as decimal or hex. The default is decimal. So, how do you actually use all this code in your application? I decided that the easiest thing to do is to put all the classes in a library. PERFDATA.MS compiles all the class source files and puts the resulting OBJ files into PERFDATA.LIB (see Figure 6). In applications that use the performance data classes, simply include PERFDATA.LIB in the linker's library list. When you build PERFDATA.MS with NMAKE, it accepts two optional defines, DEBUG=1 and UNICODE=1, to build debug and/or unicode versions. The default is no debug info and ANSI strings. I've also provided PERFDATA.H (see Figure 6), which #includes all the header files you need, so you don't have to add six separate #include directives in each of your source files. To demonstrate the classes in action, I wrote two example programs, both command-line oriented. The command line for building both programs is included at the top of their respective source files. The first demo program is PERFENUM.EXE, built from PERFENUM.CPP (see Figure 7). After taking its performance snapshot, the program enumerates each performance object and object instance in the snapshot. For each object instance, PERFENUM displays the title and value for each counter. When invoking PERFENUM, you control the contents of the snapshot. You can pass the strings "Global", "Costly", or something like "Processor Memory" (to display processor and memory info). Whatever you pass on the command line is passed to CPerfSnapshot::TakeSnapshot, so see last month's column for a better idea of exactly what you can pass. The other demo program is WORKSET.EXE, built from WORKSET.CPP (see Figure 7). The purpose of WORKSET is to show how to quickly burrow down to a specific piece of information. WORKSET looks for the working set for the process whose name is passed on the command line. While some of the WORKSET code is similar to the PERFENUM code, there are key differences. First, with the CPerfObjectList class, I use the GetPerfObject method to find the "Process" object within the snapshot rather than enumerating through all the objects. Second, after I have a pointer to the right CPerfObjectInstance, I use GetCounterByName to get the desired counter. Compare this with the PERFENUM code, which iterates through all the counters. Also, WORKSET's output is best displayed in hex, so I pass TRUE as the third argument to override the default behavior of CPerfCounter::Format. Despite all the code, and everything I've written, there are still aspects of the performance data that I haven't touched upon. For example, many of the performance counters really are counter values and are meaningless except when compared to a previous snapshot. Still, the C++ classes make it a lot easier for you to get useful information you might otherwise shy away from because it's such a pain to get. Have a question about programming in Windows? You can mail it directly to Under The Hood, Microsoft Systems Journal, 825 Eighth Avenue, 18th Floor, New York, New York 10019, or send it to MSJ (re: Under The Hood) via: Internet: Matt Pietrek Eric Maffei
The Performance Data From 30,000 Feet
The Performance Data Classes
Using the Performance Data Classes
71774.362@compuserve.com
ericm@microsoft.com