July 1996
![]()
Talk to Any Database the COM Way Using the OLE DB Interface
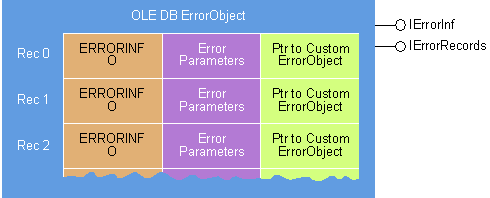
Stephen Rauch Stephen Rauch is a development technical specialist at Reuters. He can be reached on Compuserve at 70313,1455. Where do you keep your data? Well, that's a pretty broad question. If, in the context of databases, I asked about your personal data, you would probably tell me that it's in spreadsheets, documents, project plans, and flat-file databases on your PC. If I asked where you keep your group data, you would probably tell me that it's stored in Lotus Notes or Microsoft Exchange on a server somewhere. And don't forget about all that enterprise data kept in central databases as small as a SQL database like Oracle or as large as a data warehouse. Obviously your data is spread all over the place. How do you query, access, and modify all that data? The problem is that every source of data has a different interface and query language for accessing its data, like SQL or DDE. There have been several good initiatives to create a common method of accessing data. One of these, the Open Database Connectivity (ODBC) interface, allows applications to use SQL as a standard for accessing data in database management systems. ODBC permits maximum interoperability-a single application can access many different database management systems-but ODBC does not provide access to all data types. Now, OLE DB gives you a new choice. OLE DB is the method for accessing all data via a standard COM interface, regardless of where and how data is stored. This includes storage media such as relational databases, documents, spreadsheets, files, and electronic mail. With OLE technology, the database as we know it today becomes a component called a data provider. In fact, any component that directly exposes functionality through an OLE DB interface over a native data format is an OLE DB data provider. This includes everything from a full SQL DBMS to an ISAM file to a text file or data stream (see Figure 1). Figure 1 The OLE DB Architecture Just as the Windows 95 Explorer lets you explore file systems, future Explorers will let you explore data. For example, Microsoft could build a data provider that knows how to access and manipulate data stored in Microsoft Excel spreadsheets. With this data provider in place, you could use the Explorer distributed with the operating system (one that consumes OLE DB interfaces) to explore the data stored in your spreadsheet. Furthermore, individual OLE DB component objects can be built to implement more advanced features on top of simple data providers; such components are called service providers. Through service providers like query processors, specialized applications like report writers (which build and generate reports based on some subset of data) can take advantage of providers that interconnect and offer different combinations of data presented as tables. Reports can span across different data storage types without bringing data locallytoaclientasinthetypicalcaseofheterogeneousjoins. Just as there are different types of data providers, there are different types of OLE DB data consumers. Data consumers may be custom programs written to one data provider or generic consumers written to work with a variety of data providers. Future versions of products like Word, Microsoft Excel, and Microsoft Project could become data consumers as well as data providers. In that case, Microsoft Word could directly access data in a Microsoft Excel spreadsheet, and Microsoft Excel could directly access data in a Microsoft Project file. What about your investment in ODBC? That has not been forgotten; Microsoft is supplementing the ODBC Driver Manager you know today with an OLE DB provider (code named Kagera) to ODBC data. This component immediately provides OLE DB data consumers access to SQL data while at the same time broadening the class of applications accessing ODBC drivers. This article, based on the M6.1 version of the OLE DB SDK, merely skims the surface of what the SDK has to offer. The OLE DB SDK contains sample code, libraries, include files, and most important of all, some very complete documentation. In particular, you must read the specification defining a set of common interfaces exposed by component objects for accessing and manipulating data regardless of where it is stored. As of press time, Microsoft plans to put the SDK on http://www.microsoft.com and on the MSDN Level II subscription CD. I will introduce you to all of the objects and their interfaces, focusing mainly on the mandatory interfaces data and service providers must implement. From there I will move on to finding and locating data and service providers, then introduce some functionality you can add to data and service providers that makes them more robust. I have even included a sample data consumer application and data provider. OLE DB is large and very flexible, so it is impossible to cover all of the interfaces and functionality in detail. I am going to assume that you have a good understanding of both OLE and database technologies. If you understand ODBC, SQL, and Microsoft's Data Access Objects (DAO), even better. You will find after reading this article and the OLE DB specification that the database concepts and objects are similar to ODBC and DAO. The OLE DB specification introduces approximately 55 new interfaces. They are grouped into seven object types: DataSource, DBSession, Command, Rowset, Index, ErrorObject, and Transaction (see Figure 2). An object type is defined as a set of interfaces an object must expose and a set of interfaces it's encouraged to expose. For example, the Rowset object type is defined by a group of interfaces a data consumer may interact with to manipulate tabular data. To play the role of a Rowset, an object must implement the IRowset, IAccessor, IRowsetInfo, and IColumnsInfo interfaces. Optionally, a data or service provider can implement a host of other related interfaces, as seen in Figure 2. Don't be overwhelmed by the number of objects and interfaces. Providing a specification generic enough to access all types of data without compromising the functionality of the data provider is a monumental task. However, it's also obvious that a full SQL DBMS data provider is going to offer considerably more functionality than a data provider for a text file. Therefore, you don't have to implement all of these interfaces. In developing OLE DB, Microsoft looked at similarities between providers and produced a base level of interfaces. Base-level interfaces are the minimum set of objects and interfaces both data and service providers must support (see Figure 3). A simple data provider that doesn't support transactions or queries through Command objects may support only these required interfaces, while more sophisticated data and service providers will build on this foundation. Figure 3 Base-level Interfaces All data and service providers must support a Data Source Object (DSO). A DSO represents a connection to a data source through which you can operate on its data. The DSO is also the initial object instantiated by calling CoCreateInstance for a given OLE DB data or service provider's CLSID or by binding to a moniker. A DSO creates multiple sessions via DBSession objects within a single connection context. Once instantiated, a data consumer must always initialize a DSO with the IDBInitialize::Initialize member function. Attempting to use a DSO that lacks required scope or authentication information will return an error. Scope includes information such as the name and location of the data source and authentication information if the data is not in an authenticated security environment. This information is provided by a data consumer through the IDBInitialize::Initialize member function. Because a generic consumer like a query processor (which is also a service provider) may potentially use your data provider without any knowledge of its implementation, it's important to provide information about the properties of your data provider and how to build and execute queries. A data consumer can obtain this information through the IDBInfo interface. The IDBInfo::GetPropertyInfo member function returns information about the data source. Such information includes-but is not limited to-DBMS name, version, supported syntax (outer joins and alter table), capabilities (bookmarks and retaining abilities), and maximum lengths or sizes. IDBInfo::GetKeywords and IDBInfo::GetLiteralInfo let you build commands that extract data from data sources and providers. These functions provide the keywords that are unique to the provider and information about the literals used in text commands. If a DSO supports the IPersistFile interface, you can persist its connection status, scope, and properties. You can optionally (based on properties) persist the authentication information to a file, although this may be dangerous since storing password information in a file invites hackers. Note, however, that when you persist a DSO you are not persisting any active sessions, Command objects, or Rowset objects (which I will discuss later); loading the persisted file yields a DSO in the same state as when the DSO was created. As you will notice in the next few paragraphs, many interfaces either contain the word Rowset or return a Rowset. That's because they all revolve around the Rowset object. A Rowset object makes data available to a data consumer. With a Rowset object and its interfaces, a data consumer can navigate through rows of data and add, change, and delete data within a data source. Calling IDBCreateSession::CreateSession, which is supported by the DSO, creates a DBSession object. You can access data from a table, create and execute queries, manage transactions, and create a table or index through this object. At a minimum, all DBSession objects must support an IOpenRowset interface. Through IOpenRowset::OpenRowset, a data consumer generates a Rowset, making available data from an individual table. A Rowset generated through the IOpenRowset interface creates a result set from the SQL query SELECT * FROM TABLENAME where TABLENAME is supplied by a data consumer. Optionally, simple data providers can allow for definition of tables and indexes through two related interfaces, ITableDefinition and IIndexDefintion, which allow the provider to create a table or index without the overhead of supporting a data definition language. IOpenRowset, ITableDefinition, and IIndexDefinition can be used to create a simple data provider that exposes raw data to data consumers for browsing in a very simple and direct fashion. If the IDBSchemaRowset interface is exposed by a data or service provider, data consumers can get information about the database without knowing its structure. For example, you might have a SQL Server� database that organizes each database into a set of schemas with tables and queries for each schema or a Microsoft Access 2.0 database that has a container of tables and a container of queries. There are many ways a data consumer can access data from a data provider, such as reading a table sequentially, direct positioning in a rowset, and scrolling. Support for these different methods of data navigation depends on the interfaces a data provider supports. All Rowset objects support a minimal set of mandatory interfaces to access data. That minimum set includes IAccessor, IColumnsInfo, IRowsetInfo, and IRowset. Let's take a look at the steps required to read a table sequentially. Assume that you, the data consumer, already have a Rowset object. You created the Rowset object by using either IOpenRowset::OpenRowset exposed by the DBSession object or ICommand::Execute implemented by a Command object. IOpenRowset deals with the simpler case of retrieving all data from a table. ICommand gets a Rowset that meets a specific data definition or data-manipulation statement. Executing either of these functions returns a pointer to an IRowset interface, pIRowset, which is the most common interface used to read data sequentially. First, you need to get some information about the column names and column types. You'll use this information to create bindings, which is the next step. With the IRowsetInfo::GetProperties member function, you can obtain information that describes the capabilities of the Rowset through properties supported by a Rowset: bookmarks, scrolling backwards, the maximum number of open rows that can be active at the same, and about 60 other properties. Individual Rowsets created by the same data or service provider may have different properties depending on how the Rowset was created and if it applies to the current circumstances. For example, a data provider's ability to support the property might be affected by the current transaction or the current query. This will become clearer when I discuss Command objects. There are approximately 70 Rowset properties defined in the OLE DB specification. If you are building a data or service provider, you can add additional properties to describe special capabilities of your Rowsets. You can also retrieve other objects associated with the Rowset through the IRowsetInfo interface. IRowsetInfo::GetSpecification basically returns a pointer to the object that created the Rowset. This object is usually, but not necessarily, a Command object. Given a Command object, you can get the command text used to create the Rowset. If a DBSession object is returned, you can get schema information and transaction interfaces. IRowsetInfo::GetSpecification basically provides an additional method for a data consumer to gain additional information about the Rowset. The IColumnsInfo interface provides the necessary methods for a data consumer to determine the metadata, or characteristics, of the columns in the Rowset. From either the metadata or the command specification that generated the Rowset (IRowsetInfo::GetSpecification), a data consumer can determine which columns it needs from the Rowset. IColumnsInfo::GetColumnInfo returns the most commonly used metadata (column ID, column name, ordinal number of column, data type, and so on). If you already know the name or property identifier for the columns you want to use, then calling the IColumnsInfo::MapColumnIDs member function will retrieve the column ordinals. Now that you know something about the Rowset, you must create bindings. A binding associates a piece of memory in the data consumer's buffer with a column of data in a Rowset. It consists of matching some persistent name or identifier of the logical column to its physical ordering in the current Rowset. For example, if a SQL statement like is executed to yield a Rowset, then you could bind to the second column to retrieve the customerID. For the lifetime of the Rowset, columns always have a fixed ordinal, which begins with 1 and represents the order in which the columns appear in an array returned from IColumnsInfo::GetColumnInfo. The structure DBBINDING, which is defined in the OLE DB header file OLEDB.H, describes the relationship between a field in a data consumer's structured buffer and the value of a field in a Rowset (see Figure 4). Each binding must have at least one of the following parts: value, length, and status. Value is specified by dwType, cbMaxLen, and obValue, which indicate what the data consumer's structure is expecting, how much space is available to hold it, and where in the data consumer's buffer the value should be placed. The dwType forms an implied coercion. The OLE DB specification says Accessors are only obligated to transfer data in the type exposed as the type of a column in the Rowset; additional coercions are optional. Length indicates the true length of the data and is useful mainly on variable-length data types. On fixed-length data types it is set to the actual width on a read from a Rowset and ignored on a write. On variable-length data types, length reports the true, full length of the data on reads, and is taken as an override of the true size on write. The status part of the binding lets a data consumer get status information when reading from or writing to a Rowset. Status can indicate whether the value is null upon a read, if the value suffered any change upon coercion, and any error state. Figure 5 shows how to create bindings that map the data in each column of a rowset to locations in a data consumer's data buffer. Notice the use of the pColumnInfo argument in defining the binding information. Information contained in pColumnInfo is obtained by calling IColumnsInfo::GetColumnInfo. Now that you have established the bindings, you need to gather them in an Accessor, which reads data from and optionally writes data to a data provider. Accessors contain information or code to pack and unpack rows held by the data provider. You use them like handles on the access members of a row, helping the row to "crack" its contents and deliver the columns you bound in the previous step. You can create an Accessor at any time during the running of a Rowset although it must be created before getting data from a data or service provider. Remember, the columns fetched by the Rowset are determined by a query from a command or through the IOpenRowset::OpenRowset member function, not the Accessor. An Accessor is created by a data consumer using IAccessor::CreateAccessor, which is prototyped as follows: The parameters are explained in Figure 6. To create an Accessor based on the binding information described in Figure 5, a call to ::CreateAccessor would look like this: After creating and successfully obtaining a handle to an Accessor, the next step is to fetch rows. Fetching is the process in which a data consumer makes a request to a data provider to obtain (fetch) some number of rows from a data source. Rows are fetched with methods such as IRowset::GetNextRows, IRowsetLocate::GetRowsAt, IRowsetLocate::GetRowsByBookmarks, and IRowsetScroll::GetRowsAtRatio (these are defined in the OLE DB specification). Each method returns handles to the rows expressed as a handle HROW. Figure 7 shows an example using the IRowset::GetNextRows method, which returns an array of HROWs in the last parameter, rghRows. HROW hRow [in] is the handle of the row from which you get the data, and HACCESSOR hAccessor [in] is the handle of the Accessor you want to use. void *pData [out] represents a pointer to a buffer allocated by the data consumer in which to return the data. A data provider uses the bindings in the Accessor to determine how to return the data. For each binding in the Accessor, GetData obtains the data for the specified column of the row indicated by hRow. Next, it coerces or translates the data according to the data type in the binding. Then it places the coerced data in the data consumer's structure at the offset specified in the binding, truncated if necessary to match the value of cbMaxLen in the column binding. You can call GetData any number of times. In each call, you can pass the same values, a different Accessor, a different pointer to a buffer, or different values for both. This means you can get as many copies of the data as you want, and you can get them in different types if alternate coercions are provided by a data provider. Rows are held and references are counted by a data provider until the data consumer releases the rows. You release rows with the IRowset::ReleaseRows member function. ReleaseRows decreases the reference count of the specified rows passed to the function; call ReleaseRows once for each time a row was retrieved. For example, if the row was retrieved three times, ReleaseRows must be called three times. When the reference count decreases to zero, the row is truly released. Finally, when you are finished with the Rowset, you must release the Accessor. IAccessor::ReleaseAccessor releases the Accessor and all the resources associated with it. The data consumer must also release the Rowset with IRowset::Release after releasing the Accessor. Now you know how to read a Rowset sequentially. There are other methods of accessing data from a Rowset, and all depend on the properties and interfaces supported by a data provider. These include IRowsetLocate and IRowsetScroll. IRowsetLocate moves to arbitrary rows of a Rowset. IRowsetScroll moves to exact or approximate positions in a moveable Rowset depending on properties of the Rowset. It is likely to be used heavily for support of visible scrolling lists. The IRowset interface also defines interfaces for adding, updating, and deleting Rowsets. I will cover these interfaces in the sample application. I have defined the base-level interfaces and functionality; the next step is to add additional functionality. If you're building a data or service provider, you will want to expose some of these advanced features to build a more robust provider. Before I begin to define additional functionality, it is important to understand how a data consumer finds and instantiates a DSO. Like all COM components, OLE DB data and service providers are found in the registration database. Information about OLE DB data and service providers is kept in the registration database using the standard OLE Component Categories structure, which allows OLE components to become members of arbitrary categories. It also permits OLE components to describe themselves in enough detail that they do not have to be instantiated. Instantiation may be expensive or may require connection to a remote machine, so it should be avoided if possible. Utilizing this model, a data consumer can locate and directly instantiate a data or service provider's DSO-the data consumer can read information from the registry to determine the correct data provider to load for a given instance of data. The data consumer can also obtain a list of enumerators. An enumerator is a COM server that implements IDBEnumerateSources. Not all providers are enumerators, and not all enumerators are providers. Finally, a data consumer can obtain a list of service providers, which are COM servers that enhance a provider in some way. Typically, a service provider exposes a subset of OLE DB interfaces. For example, a query processor might query over several data providers. In most cases, an application built to consume data from a specific data provider will locate and directly instantiate an OLE DB data provider or service provider. General data consumers will ordinarily use a standard enumerator, included as part of the SDK, that reads the enumerators out of the registry. Because each provider may support IDBEnumerateSources, there can be many enumerators. Thus, the standard enumerator forms the root of a hierarchy of IDBEnumerateSources. How does an enumerator work? A general data consumer calls CoCreateInstance to instantiate the standard enumerator (see Figure 8). IDBEnumerateSources::Sources provides a Rowset that contains the name of the data source, a parse name, a description of the data source, and the properties of the data source. A DBSOURCE_ISENUMERATOR property means the data source supports IDBEnumerateSources. The DBSOURCE_ISPARENT property is set if the data source is parented to the data source that just called IDBEnumerateSources::Sources. This allows the client to go backwards through the enumeration. In a file-system model this is equivalent to "..". A data consumer can then navigate through data sources just like a file system. Figure 8 OLE DB Enumerator in Action! Once a data consumer locates the data source in the Rowset, it can extract the parse name string and, using IParseDisplayName, obtain the moniker associated with the data source. A general data consumer will use the moniker with the standard IMoniker::BindToObject member function to bind to the object with which it is identified. By now you should be able to create a pretty good application that can find and retrieve data from a simple data provider, so let's look at some additional functionality that more sophisticated data providers may provide. If you're building a data provider, probably the first thing you will want to add is support for building commands. Commands are queries that are built and executed to retrieve data from a data source. A data provider that supports building and executing more sophisticated queries is certainly more robust than just opening a table, which is all the base-level interfaces and objects support. This is because a query enables a data consumer to ask for specific data versus sifting through the raw data. Commands and their properties are encapsulated in Command objects, which are created through the IDBCreateCommand interface supported by the DBSession object (see Figure 9). At a minimum, a Command object supports the ICommand, IAccessor, ICommandText, IColumnsInfo, and ICommandProperties interfaces. Through these interfaces a data consumer builds and executes commands that result in a Rowset. Figure 9 The IDBCreateCommand Interface on the DBSession Object Before building a query, a data consumer must learn how to query a particular data provider. This is where the information from the IDBInfo interface supported by the DSO comes in. Remember that a data consumer can learn the supported syntax, capabilities, keywords, and literal information supported by a data provider. If you are developing a specialized data consumer that always accesses data from a specific data provider, you may know how to build a query that accesses data from the provider. The information on this should be provided by the data provider's development group in a specification. If you are building a generic data consumer that can query any data provider and want to take full advantage of the provider's capabilities, you will definitely use this interface to build queries. If you need to know column metadata, you can use the functions supported by the IColumnsInfo interface. Assuming that the data consumer's programmer read the spec and that the consumer knows how to build the query, it creates a Command object through the DBSession object by invoking the member function IDBCreateCommand::CreateCommand, which returns a pointer to a Command object interface, in this case ICommandText. The first parameter to IDBCreateCommand::CreateCommand, IUnknown* punkOuter, points to the controlling IUnknown interface if the new command is created as part of an aggregate. It is a null pointer if the command is not part of an aggregate. Once the data consumer obtains a pointer to the ICommandText interface, it creates and sets a text command. A textual command is typically a SQL expression (for example, SELECT orderID, customerID, Shipname FROM ORDERS WHERE ...) that is set explicitly through the ICommandText interface by the method ICommandText::SetCommandText. Because there are many dialects of SQL and potentially other languages, textual command formulations require not only the actual text but also an indicator of the language and its dialect (for example, ANSI SQL-92, Access SQL, or T-SQL). Thus, the ICommandText::SetCommandText method has two parameters: The pwszCommand parameter is the actual text of the command. The rguidDialect parameter is a GUID that specifies the language and dialect used by the text. For example, a call to ICommandText::SetCommandText might look like this: There is a complete list of dialect GUIDs defined in the OLE DB specification. If you are a building a data provider, be aware that you can define GUIDs for your own dialects as well. Not all data providers will support all dialects; in fact, most data providers will support only one dialect. Before you execute the command, you may want to register with the Command object the properties you want supported by the Rowsets returned by ICommand::Execute. By setting properties, a data consumer can ask for the exact functionality it wants. This affects how a Rowset is implemented by a data provider. It is also how a data consumer can get the functionality it wants with associated performance trade-offs. You can register with the ICommandProperties::SetProperties function. Invoking ICommandText::Execute will generate a Rowset based on the command specified as an argument in the ICommandText::SetCommandText member function. ::Execute is prototyped as follows: Figure 10 describes the parameters. For your command, a call to ICommandText::Execute returning an IRowset interface pointer would look like this: This gives you a Rowset interface and lets you manipulate the data using the Rowset cotypes. Microsoft is investigating enhancements to commands for a future version of OLE DB. The major new innovation under design is the command tree, which is an alternative to a text command. Command trees represent DML and DDL statements in an algebraic tree in which each node contains either an operator, an operand, or both. All nodes in all command trees have the same structure. The most important fields are the operator, the pointer to the first child, and the pointer to the next sibling. The latter two fields create a linked list for all children of the same node. In addition to these three fields, there are two status indicators set by a data provider to distinguish if the node's operator is acceptable (for example, a provider might not support a join or arithmetic operation) and if the operator in the node's current context is acceptable. Operators are divided into two groups: data manipulation operators and data definition operators. Data manipulation operators are used for, well, manipulating data in a data source. This includes constants, identifiers, names and parameters used to define scalar constants, bookmarks, catalogs, schemas, columns, table names, and lots more. Data definition operators are used for altering, creating, and deleting attributes and properties of a data source, especially record layouts, field definitions, key fields, and file locations. The shape of a tree for a SQL statement SELECT * FROM CUSTOMERS ORDER BY CITY is shown in Figure 11. Representing each node as a rectangle, the top portion represents an operator (SELECT, FROM, WHERE), the bottom left portion of the rectangle is the FirstChild and the bottom right portion of the rectangle is the NextSibling. Figure 11 SQL Statement Tree What is the advantage of commands represented as trees over commands represented as text? Unlike text commands, which must be built to a specific language and dialect, command trees are language-independent. Also, through the use of command trees, a data consumer can retrieve error information down to a node in the tree. Because the error may occur anywhere within a possibly long string, the error indication scheme for nodes in a command tree does not work well for text commands. OLE DB has defined a set of interfaces and an object to support simple, nested, and coordinated transactions. Any data that is read, added, changed, deleted, or updated can be transacted. Transaction support is provided through the ITransactionLocal interface supported by the DBSession object (see Figure 12). Any data provider that supports transactions must support this interface. Figure 12 The ITransactionLocal Interface on the DBSession Object Without transaction support, all work done under the scope of the DBSession object is immediately committed on each method call. When a DBSession object enters a local or coordinated transaction, all work done by the DBSession or the Command and Rowset objects associated with the DBSession is part of a transaction. A data consumer calls ITransactionLocal::StartTransaction to begin a transaction on the DBSession object. It is also through this interface that a data consumer commits or aborts the unit of work performed within a transaction's scope. For those data providers that support nested transactions, calling ITransactionLocal::StartTransaction with an existing transaction active on the DBSession returns a new transaction nested within the active transaction. Changes made within the innermost transaction are completely invisible to its outer transaction until the inner transaction is committed or aborted. Data providers that support extended transaction functionality implement a Transaction object. The Transaction object supports the ITransaction interface for committing or aborting a transaction directly, allowing a data consumer to commit or abort at a transaction level other than the current level of a nested transaction. Another feature of the Transaction object is event notification; IConnectionPointContainer may be supported as a notifications sink for the ITransactionOutcomeEvents interface implemented by a data consumer. ITransactionOutcomeEvents, an interface defined in the OLE Transactions specification, provides the capability for a data consumer to monitor the outcome of transaction events. When a commit or abort is processed, a data provider notifies each registered ITransactionOutcome interface of the transaction's outcome. Finally, a data provider that supports the ITransactionJoin interface can participate in coordinated transactions. Calling the ITransactionJoin::JoinTransaction method enlists the DBSession into a coordinated transaction. Once a data consumer joins a coordinated transaction, it calls the transaction coordinator's ITransaction::Commit or ITransaction::Abort method to commit or abort the transaction. The Index object supports several interfaces that abstract the functionality of a data provider if the provider gives fast access to its data via a file access method. At this time, OLE DB supports the file access methods based on ISAM and B+/-Trees. Any data provider supporting the Index object must support the IAccessor, IRowset, IColumnsInfo, and IRowsetIndex interfaces. The IRowsetIndex interface contains the methods to position within an index and to define the range of contiguous keys scanned when a data consumer calls IRowset::GetNextRows. IRowsetIndex::SetRange restricts the set of row entries visible through a call to IRowset::GetNextRows. Calling IRowset-Index::Seek allows you to directly position at a key value within the current range established by calling IRowsetIndex::SetRange. An index can have several properties associated with it, including DBPROP_INDEX_PRIMARYKEY, DBPROP_INDEX_UNIQUE, and DBPROP_INDEX_CLUSTERED. To determine the properties associated with a particular index, you can call IRowsetIndex::GetIndexInfo, which returns an array of DBPROPERTY structures where each structure describes a property supported by the index. Sample code in the OLE DB specification shows how to read a table through an index. The last object and set of interfaces I want to introduce before moving to the sample application is the ErrorObject and its interfaces. ErrorObjects are optional; they don't have to be implemented by a data service provider. ErrorObjects are an extension of the OLE automation error-handling interfaces, which include ICreateErrorInfo, IErrorInfo, and ISupportErrorInfo. Through these interfaces, an object can provide error-related information to a consumer of the object. This includes a text description of the error, the GUID for the interface that defined the error, help context ID, help file name, and the ProgID of the class or application that returned the error. One of the shortcomings of the OLE automation error-handling interfaces is their inability to return multiple error records from a single call. For example, a data consumer might call into a query processor, which calls down into several data providers. If an error occurs in a data provider, how does the query processor add its own error information to the data provider's error before returning to the data consumer? To solve this problem, OLE DB extends the OLE automation error objects by adding the ability for an ErrorObject to contain multiple error objects (see Figure 13). Figure 13 OLE DB ErrorObject Records in OLE DB ErrorObjects are numbered starting at zero and new error records are added to the top of the list. When an error record is retrieved, it is extracted from the list in LIFO order. Therefore, consumers of the object can start with the highest level of error information and then retrieve increasingly detailed information. Each error record is composed of three parts, an ERRORINFO structure, error parameters, and a pointer to a custom ErrorObject. The ERRORINFO structure returns most of the basic information associated with an error. Error parameters, which are provider-specific values, are substituted into error messages by a provider-specific error lookup service through the member functions supported by IErrorInfo. For example, the provider might associate the error message with the dwMinor value relating to an error code in the data provider's specification. Error parameters supply the name of the table that could not be opened. In addition to the ERRORINFO structure and parameters, a custom ErrorObject is associated with each error record. A custom ErrorObject is the mechanism by which OLE DB ErrorObjects are extensible, allowing you to create your own provider-specific ErrorObject. Your ErrorObject's interface pointer is stored in the record. As you can see, this model is very extensible, giving a data consumer lots of error information that can be provided to the user. The IErrorInfo and IErrorRecords interfaces are self-explanatory and there is plenty of sample code in the OLE DB specification. I picked the CheckBook sample from Visual C++� to demonstrate OLE DB. CheckBook illustrates how to implement a record-based document. It writes the data to an To convert the application into two components, a data consumer and simple data provider, I removed the file access functions (basically the CDocument CChkBookDoc class) and created a data provider from it. The data provider is an in-process server implementing the base-level interfaces described earlier. The new CDocument-based class uses the OLE DB interfaces to consume data from the data provider (see Figure 14). When you open a document with OnOpenDocument, the application immediately calls CoCreateInstance to instantiate the data provider and initializes the data provider by providing the file name entered by the user. The original CheckBook application accessed all data from the flat file when the file is opened-no commands here-and displayed it in two views. This is exactly what the OLE DB CheckBook application does; after initializing the data provider, the CheckBook data consumer creates a DBSession and opens a Rowset using the IOpenRowset::OpenRowset member function. The data consumer then goes into a loop (see the CCheckbookDoc::GetNextRows member function), fetching and getting the data directly from the data provider and storing the check information in a CObList. In this example I hold onto the HROWs so that I have the HROW for an individual check when the user updates it. I made this simplification since the example holds onto a relatively small number of rows at a time and the provider does not support bookmarks. General-purpose consumers should attempt to use bookmarks rather than hRows to hold onto a row whenever possible, since hRows require that the provider do some caching and are generally more heavyweight than bookmarks. The OLE DB CheckBook application adds new rows, which are checks, at the end of the flat file by calling the IRowsetNewRow::SetNewData member function in CCheckbookDoc::AddNewCheck. Using an Accessor and a pointer to the new data values, the data consumer calls SetNewData, which returns an HROW of the newly added row. When I get the new HROW, I add it to my CObList just in case the user wants to change the check before closing the application. By providing an Accessor and an HROW from an open Rowset, you can change the data associated with the HROW by using the IRowsetChange::-SetData member function. In CCheck-bookDoc::UpdateData, I use this interface to update changes made on the check. How do you run the application? First you have to register CheckBook's data provider. The data provider is a self-registering in-process server and may also be registered using the REGSRV32.EXE tool. Create your own checkbook through the application, or use the MYCHECKBOOK.CHB file provided with the sample application and the source code to the data consumer. To start the application, run CHECKBOOK.EXE. The goal of OLE DB is to give applications uniform access to data stored in DBMS and non-DBMS applications. Using OLE DB, applications can take advantage of the benefits of database technology without having to transfer data from its place of origin to a DBMS. If you don't already have the OLE DB specification, get your hands on it. The openness of the specification and the promise of accessing any type of data-no matter where or how it is stored-is information at your fingertips. Coercion Converting the base medium of a column in a row of data to match the caller's requested format. For example, the caller may want a string representation of a value which is actually stored in the database as an integer. Consumer Any application that retrieves data from a data or service provider using OLE DB interfaces. DDL Data Definition Language. DML Data Manipulation Language. Heterogenious Join A join between local and remote tables in different DBMS. For example, you use a heterogenious join to join a table in a Microsoft Access database with another table in Microsoft FoxPro. Joining two or more tables is the process of comparing the data in specified columns and using the comparison results to form a new table from the rows that survived the comparison. Join A link between the rows in two or more tables done by comparing the values in columns specified within a statement of some query language. Metadata The data stored in a database that describes the tables and columns and their relationships. Outer Joins Most joins provide only matching rows (rows with values in the specified columns that satisfy the join condition) in the results; these join operations eliminate the information contained in rows that do not match. It is sometimes desirable to retain the nonmatching information by including nonmatching rows in the results of a join. To do this, you use an outer join. Query Processor Given a statement in some query language (that is, SQL), a query processor determines a query plan for a statement, executes the query plan, and returns a result set.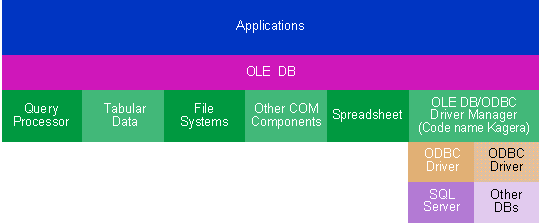
Objects and Interfaces
Base-Level Interfaces
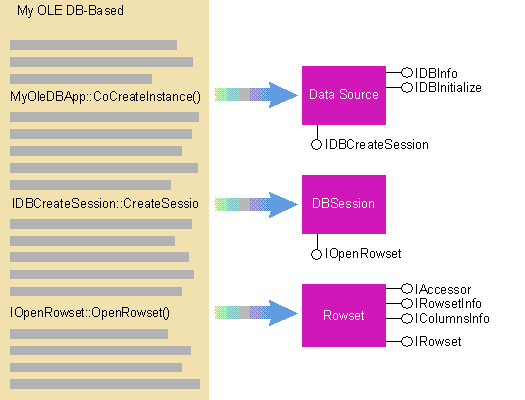
Reading a Table Sequentially
Creating Bindings
SELECTorderID,customerID,ShipnameFROMORDERSWHERE ... Creating Accessors
HRESULTCreateAccessor(DBACCESSORFLAGSdwAccessorFlags,
ULONG cBindings,
const DBBINDING rgBindings[],
ULONG cbRowSize,
ULONG* pulErrorBinding,
HACCESSOR *phAccessor); HACCESSOR hAccessor;
hr = pIAccessor->CreateAccessor( DBACCESSOR_READ |
DBACCESSOR_ROWDATA,
cBind, rgBind, 0,
NULL, &hAccessor ); Releasing Rows
Other Means of Reading Rowsets
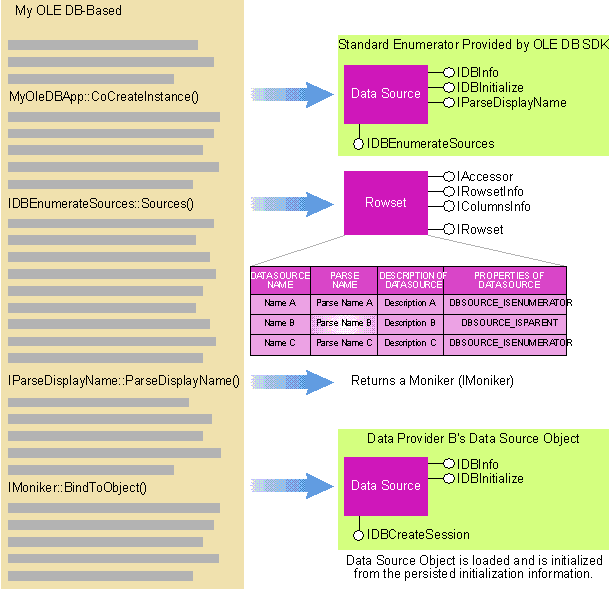
Finding and Instantiating a DSO
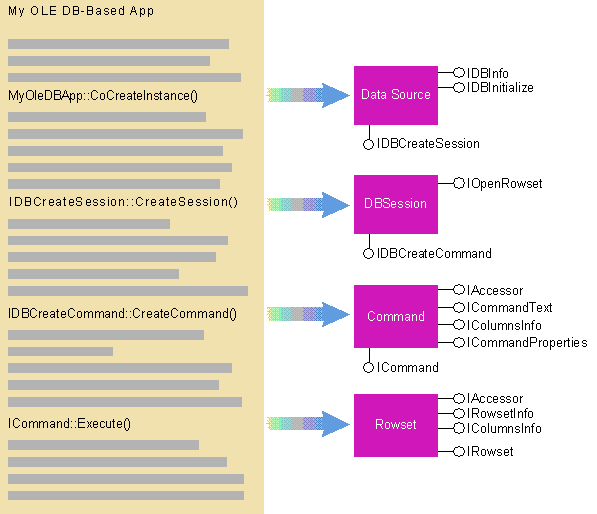
Building Commands with Command Objects
ICommandText *pCommandText;
hr = pIDBCreateCommand::CreateCommand
(NULL, IID_ICommandText,
(IUnknown **) &pCommandText);
pIDBCreateCommand -> Release (); REFGUID rguidDialect
const LPWSTR pwszCommand pICommandText->SetCommandText (DBGUID_SQL92,
"SELECT * FROM CUSTOMERS ORDER BY CITY"); HRESULT Execute (IUnknown *rgpUnkOuters[],
REFIID riid, DBPARAMS *pParams,
HCHAPTER *phChapter, BOOL fResume,
ULONG *pcRowsets,
IUnknown ***prgpRowsets,
WCHAR **ppRowsetNames); HRESULT hr;
ULONG ulRowsets = 0;
IRowset **rgpRowsets = NULL;
hr = pCommandTree->Execute (NULL, IID_IRowset, NULL,
NULL, FALSE, &ulRowsets,
(IUnknown ***)&rgpRowsets); Command Trees
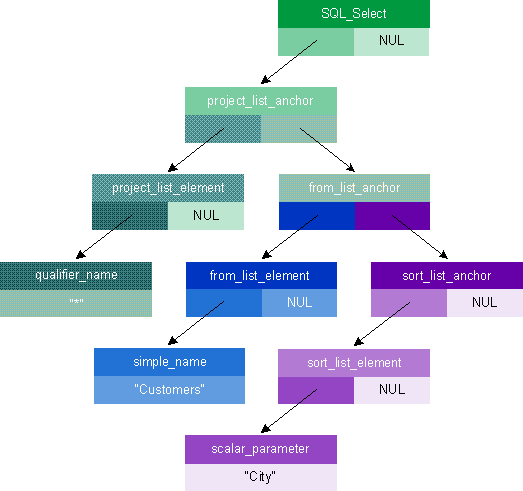
Transactions
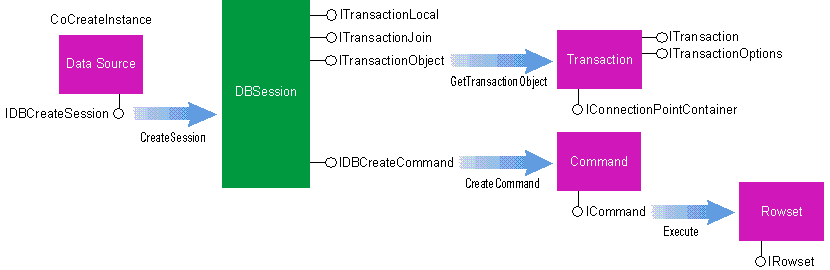
Index Objects
ErrorObjects
typedef struct tagERRORINFO {
HRESULT hrError;
DWORD dwMinor; // A provider-specific error code
CLSID clsid; // The class ID of the object that
// returned the error.
IID iid; // The IID of the interface that
// generated the error
DISPID dispid; // Indicates the method that
// returned the error
} ERRORINFO; Cannot open table <param1>. CheckBook
MS-DOS file with a CHKBOOK-specific file format and on a per-record basis rather than on a load/save basis. Written to the file is the check number (which is automatically assigned by the application), the date the check was written, who it was written to, a memo, and the amount. The application supports retrieving, editing, and adding records. Keeping the same functionality as the CheckBook sample, I modified the application so it uses OLE DB to access the data store, which in this case is a flat file. As you can see, you can access any data no matter how it is stored. REGSVR32 CHECKDP.DLL Conclusion
DATABASE GLOSSARY