June 1996
![]()
Roll Your Own Persistence Implementations to Go Beyond the MFC Frontier
Allen Holub
Allen Holub is a programmer, consultant, and trainer specializing in C++, object-oriented design, and Microsoft operating systems. He can be reached at allen@holub.com or http://www.holub.com.
Click to open or copy the EXAMPLE project files.
Click to open or copy the PROJECT project files.
A persistent object is one that can retain its value longer than the lifetime of the program that created it. (Some people call persistence "serialization," probably because the data goes out to the disk in a serial fashion. I'll use the more common term here.) The implementation of persistence in MFC is problematic. I'm going to remedy this by developing a persistence implementation that is not integrated with MFC, but that can coexist with MFC nonetheless. The implementation I'll show you uses templates and several new language features-namespaces, run-time-type-identification (RTTI), and so on. If you haven't used this stuff yet, this article will give you some examples to get you started.
Let's start by looking at how MFC persistence works with a realistically complicated example. (In spite of the complexity, I've stripped out a lot in the interest of clarity, replaced various collections with fixed-length arrays, and removed most of the error checking.)
Employee.h (see Figure 1) shows several persistent classes. Starting at the top, the Employee class contains information common to all employees. The current example shows an employee ID, but a fleshed-out version would have a name, salary, and so on. The class is made persistent by three things. First, the class must derive from CObject or one of its derivatives. Second, it must include a DECLARE_SERIAL invocation at the top of the class definition. (Note that DECLARE_SERIAL is happy being a private member; it's put into the public section of the class definition by all the wizards, but there's no reason for it to be there.) Finally, an override of CObject's Serialize function must be provided (about half-way down the class definition).
The other class members implement the actual object. Dump just dumps the local fields to the debugger's output window when an object of class Employee is passed to AfxDump. The constructors and destructors do the obvious thing. Note that the destructor is virtual, so I can delete a derived-class object through an Employee pointer. The is_this_you message handler will be used to find a specific Employee when all you have is an ID. I'll come back to set_up_pointers in a moment.
Two classes derive from Employee: Manager and Peon. Manager extends Employee by adding an array of pointers to members of the managed group and a parallel array of employee IDs for the members. For example, the employee ID of the Peon pointed to by group[x] will be in group_ids[x]. The Peon extends Employee by adding a pointer to its manager and the ID of its manager.
The Division class is a simple container that represents all the employees in a division. Note that a Division is also persistent; it derives from CObject, invokes DECLARE_ SERIAL, and has a Serialize override.
Employee.cpp shows the implementation details. The IMPLEMENT_SERIAL invocations at the top of the file are required to match the DECLARE_SERIALs in the class definitions. The macro arguments are the current class name, the base-class name, and a "schema"-basically a version number for the class. You should change the schema value every time the class definition changes to make sure the data that you read back from the disk fits into the current implementation of the class. The various class's Dump functions just print the relevant members of the current class to a CDumpContext in the same way you'd print to an ostream. The resulting output appears in the debugger's output window.
The Serialize functions, which transfer data in the current class definition to or from the disk, come next. The CArchive pointer is used much like an ostream. The derived-class Serialize functions must all chain to the base-class versions to transfer data at the base-class level or only the derived-class data would be transferred. That's why the Serialize function should be protected. If it is private, you can't chain to it. (The function should hardly ever be public as in the wizard-generated code. Make it public only if you intend to actually call Serialize from a non-member function.)
The important thing to notice in the Serialize functions is that you can't reliably flush a pointer to disk. When you do the restore, the object you're pointing to will probably not be at the same place in memory as it was when the file was flushed. Consequently, rather than flush the array of Peon pointers in the Manager, I just flush the employee IDs of the Peons. Similarly, the Peon doesn't flush the Manager pointer, only the Manager's employee ID.
The pointer problem is actually solved by MFC, but only if every pointer in your persistent object points at a CObject derivative (and every pointer in those objects also points at CObject derivatives, and so on), and you always use the << operator to load or flush all pointers in all Serialize functions. If this is the case, you can use the << and >> operators to flush the pointer (in which case MFC flushes the object addressed by the pointer, not the pointer itself). MFC correctly handles graph-like relationships. For example, if a tree node derives from CObject, all the pointer fields in the node point at CObject derivatives, and << is used everywhere to flush all the pointers, then you could flush the entire tree do the disk by using << to flush the root node. I don't usually take advantage of this mechanism for several reasons, the main one being that I don't want to (and often can't) derive every class in my system from CObject, so the mechanism is not reliable in the general case. The other major problem is that I usually want a given object to be flushed to disk only once. If an object was in several trees at the same time, it would be flushed to disk as many times as there were trees.
The Division class's Serialize function deserves attention because it demonstrates a particularly useful and necessary feature of any decent persistence implementation: it's polymorphic. The array of Employee pointers that comprise the Division do not point at generic Employees as you might surmise from the class definition (and the definition of the cur pointer in the Serialize function). They actually point at Manager and Peon objects. Nonetheless, I can flush the objects to disk (and read them back) without having to know the object's actual type. The line
ar << *cur++invokes a special shift overload that takes a CObject pointer as its right operand and flushes that object to the disk (by indirectly calling the Serialize functions). Since Manager and Peons both have CObject as an ancestor, the conversion from Manager* to CObject* is automatic and silent. The system doesn't need to know the object's actual type as long as the object is a member of some class that has CObject as an ancestor and that implements all the required persistence stuff discussed earlier. The matching
ar >> *cur++goes in the other direction. The right argument must be a CObject pointer. The system figures out what sort of object is on the disk, allocates (using new) and initializes (using the default constructor) an object of that type, and fills it with data from the disk by calling the Serialize functions that you provide. Since the memory comes from new, you must pass it to delete when you're done.
Note that there's a big difference between using the shift overloads and calling Serialize directly. If I did something like
Employee emp;
emp.Serialize( ar )the only information that I'd get off the disk would be the information transferred by Employee::Serialize. I'd be in big trouble if the object on the disk was actually a derived-class object. Not only would the derived-class data still be on the disk, but the disk file would be out of synch with my reads; subsequent reads would probably get garbage. A direct Serialize call works only if you know the actual type of the object on the disk. In the current case, the foregoing code would work only if I could guarantee that there was an actual Employee (not a Manager or Peon) on the disk waiting to be read.
The next part of the puzzle is the set_up_pointers function just below the Serialize functions. Remember that the Manager flushed only the employee IDs to the disk and the matching load gets only the employee IDs, not the Peon pointers. Consequently, once all employees in the Division are reloaded, the pointer arrays have to be reconstructed. The set_up_pointers function does this by asking the Division object (passed in as an argument) for a pointer to an object that has a specific employee ID by calling give_me_ worker_with_this_id.
The function then checks that the returned worker is actually a Peon by using the new C++ dynamic_cast mechanism. The expression
Peon *peon = dynamic_cast<Peon *>(emp);works much like a cast to Peon* except that the resulting value is NULL if the cast isn't safe. That is, peon is set to NULL if emp doesn't point at either a Peon or at an object of some class that derives from Peon. The dynamic cast fails, for example, if give_me_worker_with_this_id returns a pointer to a Manager or an actual Employee. There are variants to dynamic_cast that allow conversion of a reference, but these are less convenient to use because they throw exceptions if the cast doesn't work. I usually use the pointer version.
I should also point out that, even though MFC supports a similar mechanism in CObject's IsKindOf function, I prefer to use the system built into the language itself. The dynamic_cast is more portable than IsKindOf, it doesn't require me to derive from CObject, and I find it more readable. The built-in dynamic_cast also works with template classes and correctly handles all multiple-inheritance scenarios; the MFC IsKindOf function does not.
The final part of the picture is SerialDoc.cpp (see Figure 2), which shows you how the document object allocates a Division in the constructor (using new) and deletes it in the destructor (with delete). The Serialize override flushes the entire division to disk using the shift operator overload of the CArchive object. This operator overload calls the Division's Serialize functions, which indirectly call the Manager and Peon Serialize functions, and so on. As before, I'm using a dynamic_cast on the read to make sure that I actually get what I expect off the disk.
The OnNewDocument function reinitializes the Document in an SDI application-it just frees the Division and allocates a new one. OnPopulate, at the bottom of the listing, is a menu handler that populates an empty Division with a few Employees so that it can be tested. OnDump prints out the current Division-Division::OnDump is called as a side effect of AfxDump.
There are a lot of good reasons to use MFC: it helps a lot with the MDI implementation, and it's indispensable for supporting OLE. (A few years ago at a Microsoft developer's conference, we were told that we should all use MFC because it "encapsulates 20,000 lines of code essential to every OLE 2.0 application." I thought "good grief, it takes 20,000 lines of code just to write a basic OLE app," but using MFC does save me from having to write all that code myself.)
On the downside, MFC is not at all object-oriented. For example, MFC regularly violates many OO principles such as not exposing the data members of a class, and many MFC classes use derivation incorrectly. (How many times have you sent a message whose handler is defined in a CWnd to a CDialog?) Given these problems, I'm extremely reluctant to couple MFC to the OO parts of my programs. Rather than building my applications around the MFC architecture, I first design a proper OO system without consideration for the implementation environment, then I use MFC to help implement some of the objects in my system. Looking at the high-level design documents for most programs I've written would give you no indication that MFC was used at all.
Moreover, I don't want to be married to MFC forever. If something better comes along, I want to be able to implement the new library without significantly impacting my code. I can't decouple from MFC if I derive from CObject all over the place as MFC's persistence implementation requires. One of the main issues in code reuse, after all, is that you have no way of predicting how the code you write today will be used in the future. Deriving from CObject effectively prevents this flexibility.
Deriving too often from CObject also really gets in the way with regard to multiple inheritance, and multiple inheritance is central to the idea of a reusable utility class, usually called a "mix-in." (Multiple inheritance was controversial for a while, but C++ is moving in the direction of template-based class hierarchies that use multiple inheritance to define "interface" classes. Java even has a keyword, "implements", that distinguishes this sort of multiple inheritance from the standard sort of is-a inheritance, for which Java uses "extends".)
Here's how a mix-in might work. A typical collection implementation requires you to derive "storable" objects from some base class to assure that the object has the capabilities needed for collection management. Figure 3 shows how this might look in a typical single-inheritance scenario. (This is a Booch-style inheritance graph, where the arrows point from the derived to the base class.) An Employee holds information common to all Employees (names, employee IDs, and so on). Managers have all the characteristics of Employees, but add capabilities as well-they keep a list of Peons who work for them, for example. The Peons, on the other hand, don't keep lists of anything, but they do have pointers to their Managers.
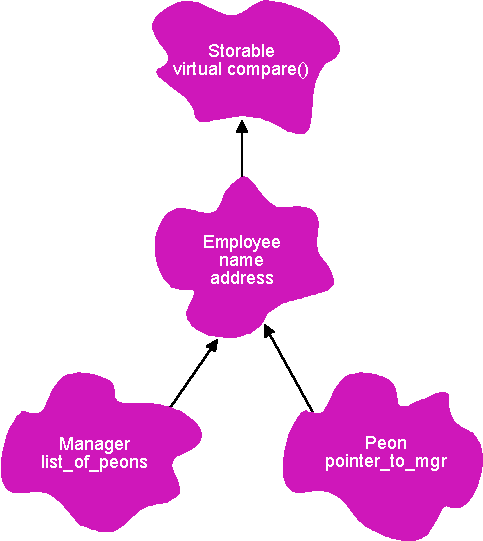
Figure 3 Single-Inheritance Mix-in
The problem with this arrangement is overhead. The Storable base class probably has some fields in it and certainly has virtual functions. All Employees, including all Managers and all Peons, carry around the overhead of these fields. Now, let's say that this is the average company where the Managers outnumber the Peons by a factor of 100:1 (or in this era of corporate downsizing, maybe 50:1). Remember, there are no lists of Managers, just lists of Peons. Nonetheless, every Manager is carrying around the overhead of being Storable.
The problem is solved easily if you realize that Storable is not a true base class in the sense that a Manager is an Employee. Rather, Storable is a property that you want to mix into the class hierarchy just where you need it. That's why it's called a mix-in class. Figure 4 shows a revised class hierarchy that fixes the earlier problems. A Peon is a "Storable Employee," while a Manager is a plain old Employee. Only the Peon carries the overhead of being Storable. Using an adjective for the class name, by the way, clues you in to the fact that a mix-in strategy is appropriate for this class. A true is-a inheritance relationship is usually indicated when both class names are nouns (a Manager is an Employee).
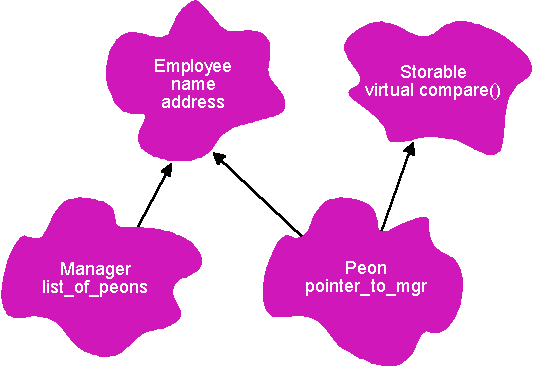
Figure 4 Using Mix-Ins to Reduce Overhead
MFC and CObject come into this because of the dreaded diamond-shaped class hierarchy, which causes no end of grief in C++. Figure 5 shows the problem. Notice that Peon doesn't provide an override of CObject's Dump function. If I try
peon Fred;
Fred.Dump();I'll get a hard error from the compiler. The main problem is that there are actually two CObject components in a Peon. (see Figure 6) Both the Employee and Storable components of a Peon have a CObject component. When you say Fred.Dump, the compiler doesn't know which "this" pointer to use-the one that points at the CObject component of an Employee or the one that points at the CObject component of a Storable. Things get even worse when you try to serialize a class that derives multiply from CObject. The following code demonstrates the problem. First, you can't list two base classes in the IMPLEMENT_SERIAL macro. Moreover, you can't pick one side or the other to make it work. The IMPLEMENT_SERIAL(C,A,1) in the following code generates nine error messages.
class A: public CObject
{
DECLARE_SERIAL( A )
};
class B: public CObject
{
DECLARE_SERIAL( B )
};
class C: public A, public B
{
DECLARE_SERIAL( C )
};
IMPLEMENT_SERIAL( A, CObject, 1 )
IMPLEMENT_SERIAL( B, A, 1 )
IMPLEMENT_SERIAL( C, A, 1 )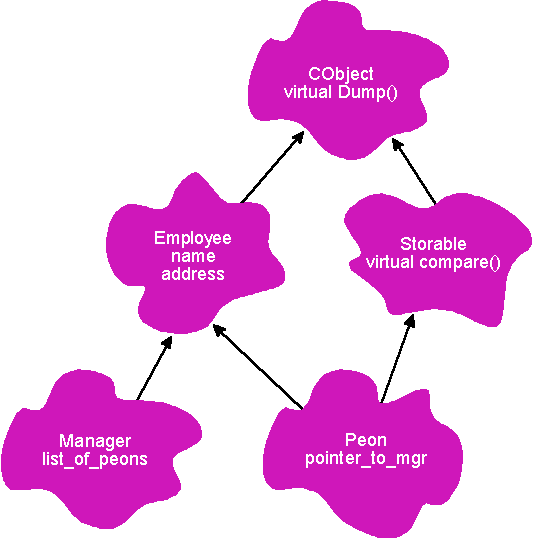
Figure 5 A Diamond-Shaped Class Hierarchy
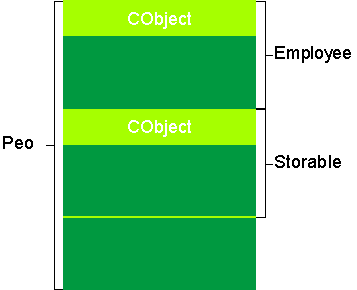
Figure 6 A Peon in Memory
Most C++ textbooks tell you that you can solve the ambiguity problem using virtual base classes. If you defined Employee and Storable like this
class Employee: virtual public CObject { /*. . .*/ };
class Storable: virtual public CObject { /*. . .*/ };
class Peon: public Employee,
public Storable { /*. . .*/ };there would be only one CObject in the resulting Peon. Virtual base classes introduce their own problems, however. The main problem is initialization; if both Employee and Storable had constructors that initialized CObject in different ways, the compiler wouldn't know which one to use to initialize the (now merged) CObject component. The solution to this conflict is not pretty; the constructor in the most-derived class (Peon) has to initialize everything above it in the hierarchy. This, of course, violates many basic rules of OO design, including the rule that you shouldn't need to know anything about the design beyond the immediately surrounding context. Another problem is that the presence of virtual base classes adds to the high overhead of exception processing.
To really use mix-ins effectively, you have to avoid this diamond-shaped structure. Of course, if you're deriving everything from CObject, you're guaranteed to have similar ambiguity problems. Returning to the matter at hand, you cannot fix the earlier problems by making CObject a virtual base class. If you make B and C derive virtually from CObject (by preceding the "public" with "virtual" in the earlier class definitions) the compiler spits out six error messages (different ones than before, but errors nonetheless).
The final problem with MFC serialization is that it doesn't work with templates. In my opinion, a well-designed C++ class hierarchy should make use of templates. In fact, the Standard Template Library (STL), which defines many templates that do data-structure manipulation much better than MFC's equivalent classes, is part of the C++ language as defined in the ANSI/ISO C++ committee's Draft Working Paper. I, for one, want to use an accepted part of the standard library for data-structure manipulation rather than MFC's quirky classes. Unfortunately, template classes (including all STL template classes) can't be serialized to disk using MFC, which uses the macro preprocessor to generate various persistence-related functions. The class names must be known at preprocessing time for this to work, but templates are expanded by the compiler long after the preprocessor is gone. Consequently, there's no way for the preprocessor to know the compiler-generated class name. In my opinion, it's unacceptable that MFC won't store an STL object on the disk with its default serialization mechanism.
Since the MFC persistence implementation isn't up to snuff, let's roll our own. Remember from our earlier look at MFC's persistence that the system must somehow create an empty object of the correct type to use as a receptacle when the Serialize functions read data from the disk. In the earlier example, the Division's serialize function didn't know the actual type of the object it loaded. It loaded Managers and Peons, but did that using an Employee pointer. It was happy as long as it got an Employee of some sort off the disk. Division::Serialize couldn't just create Employee objects to hold the data from the disk, however. A Peon, for example, has fields that don't exist in a raw Employee, so you can't stuff a Peon's data into an Employee object. You need to create an actual Peon, or rather the system has to do it for you since all you know about the disk file is that there are a bunch of Employees of some sort stored out there. You don't know what sort of Employee, however.
If you could just flush an object to the disk with a single write call, you could get by with just storing the object size on the disk, but this doesn't work any better than trying to copy objects with memcopy (as compared to the copy constructor). To make matters worse, there are things stored in the object that you don't know about, like the virtual-function-table pointer. You can't just write the vtable pointer to disk and then expect to be able to read it back reliably. For one thing, the program might have been recompiled since you last wrote to disk and the vtable might have moved as a consequence.
What's the solution? If you use the debugger to look at a file generated from an MFC app that uses persistence, you'll notice that mixed up in the general gobbledygook are occasional strings that hold class names. That's the key! The system writes the class name to the output file just before calling Serialize. On the read side, it reads the class name and uses it to create a new object of the required type. In other words, it's possible to translate a string that holds a class name into an empty, but properly initialized, object of that type. (The default constructor is used for initialization.) This ability is called dynamic creation, and we have to implement dynamic creation to do persistence. Unfortunately, MFC's dynamic-creation system (DECLARE_DYNCREATE/IMPLEMENT_DYNCREATE) has all the problems with respect to persistence discussed earlier, so we can't use it.
Dynamic-creation implementations all work more or less the same way. You keep a database (I'm using the word loosely) indexed by class name. Each database entry holds a function that manufactures an object of the required type on request. In my implementation, you pass the function a class name, and it returns a new object of that type if it recognizes the name, otherwise it returns NULL.
I've taken a very different approach to dynamic creation than MFC. I use a template, not the macro preprocessor, to implement the mechanism. To create objects of a given type dynamically, you must first create a "factory" object that manufactures objects of that type. You then call the dynamic::create function to actually manufacture the objects. The factories are created by expanding a template (called "factory"). They need not stick around for the life of the program; they just have to be in existence when dynamic::create is called.
Figure 7 demonstrates the mechanics. I declared a few classes and a template, then registered factories for them with definitions like this:
dynamic::factory< Peon > peon_factory;Once the factories are created, you can forget about them. They don't have to exist for the life of the program, but they do have to exist during dynamic creation. For example, you can declare them as local variables in a function that's going to do dynamic creation. That's good because the factory object contains one object of the type that it will create, so a large contained object can take up a lot of space. If this is a problem, declare the factories in the same scope as the dynamic::create call. (There's one other restriction: factories for template classes cannot be allocated on the stack-they must be defined at the global level or gotten from new.)
An object of the required type is generated with a call like this:
Peon *p = (Peon *)dynamic::create( "class Peon" );You pass dynamic_create the class name and it returns either a pointer to a new object of that class or NULL if it can't create the object (probably because there was no factory). Note that the factory object doesn't have to be visible to create an object-it could be defined in some other file, for example. All you need is the class name, which you could read from disk. Unlike MFC's dynamic-creation implementation, there's no requirement that you derive from anything special (like CObject) and there are no magic macros that must be included in the class definition.
Figure 7 shows all this being used to create versions of the Manager and Peon classes dynamically. I've removed all the MFC stuff (DECLARE_SERIAL, IMPLEMENT_ SERIAL, CObject, and so on), and I declare the factories towards the bottom of the example. The create_a_few_objects function manufactures an instance of each object and checks that the correct object was created using the dynamic_cast mechanism described earlier. I'm deliberately using an Employee pointer (rather than a Peon or Manager pointer) to demonstrate the polymorphic nature of the system. Even though it's an Employee pointer, it's actually pointing to a derived-class (Manager or Peon) object. The dynamic_cast operator makes sure that an object of the correct type was actually manufactured.
This code shows how to manufacture an object of a template class:
template <class t>
class templ
{
t some_data;
public:
virtual ~templ(){}
};
dynamic::factory< templ<int> > f3;
templ<int> *tp = (templ<int>*)
dynamic::create("class templ<int>");The process is the same as before, but I use the name of a template class instead of a normal class. Note that the factory creates a specific expansion of the template (templ<int>), not the template itself. If I wanted to manufacture some other template class (such as templ<double>), I'd need a second factory.
So, how is all this accomplished? Dynamic.h has the required classes (see Figure 8). The first programming problem really falls into the realm of good manners. My persistence implementation uses several auxiliary classes that the user knows nothing about. This is a potential problem because someone else might accidentally use one of these class names. This is going to cause quite a bit of consternation when the compiler rejects the second user-supplied definition.
As long as you're inside the namespace (delimited with curly braces), you can use other things defined in the namespace without any fuss. When you're outside the braces, however, you have to identify symbols defined within the namespace explicitly. In the current example, I have to use dynamic:: to identify "fred". You can also create a definition for a class named "fred" outside the namespace, but it is a different class. Think of the namespace name as part of the class name; "fred" and "dynamic::fred" are different classes.
As a convenient shorthand-which I haven't used here, but it's nice to know about it-you can put the statement "using namespace dynamic;" outside the namespace to effectively move all symbols defined in the namespace into the current namespace. Of course, you'll have to deal with any name conflicts that arise as a consequence.
The dynamic namespace in dynamic.h hides the definition of two auxiliary classes. The factory template is also defined in this namespace (which is why I had to say dynamic::factory<...> in the earlier examples).
The factories insert themselves into a "database" (really a linked list) when they are created. They do this using the classes shown in Figure 9. The head-of-list pointer is just a static member of the class. The important member is the "manufacturer" pointer, which points to an actual factory object. Here's the definition:
The virtual create_obj function is passed a class name and returns either a pointer to an object of that class or NULL if it can't make the object. Manufacturing an object is a simple matter of traversing a list of factory_list_element objects and calling create_obj indirectly through the manufacturer pointer until one of the calls returns a non-NULL value.
The list is built on the fly at run time by the factory_list_ele constructor.
inlinefactory_list_ele::factory_list_ele(abstract_factory
*fact)
: manufacturer( fact )
{
next = head;
head = this;
}The function both initializes the manufacturer field and links the object it's creating into the list as a side effect of creation. The destructor (which I haven't shown) removes the object from the list.
All that's left then is generation of a derived class that actually implements the interface defined in abstract_factory for a particular object type.
template <class t>
class factory: public abstract_factory
{
static t an_object;
factory_list_ele manufacturer;
public:
factory( void ): manufacturer( this ) {}
void *create_obj( const char *class_name )
{
return !strcmp( typeid(an_object).name(),
class_name)
? (void*)( new t )
: 0
;
}
};This is a classic example of using a template to automate a boilerplate derivation. All derived-class definitions would look pretty much alike, so it's handy for the template mechanism to make them for us. The template class contains an object of the class being manufactured, and it uses typeid-one of the C++ RTTI features-to tell whether the class whose name is passed to create_obj can be manufactured by the current object. The typeid function returns a pointer to a type_info object, whose name member returns the class name.
The neat thing is that all this works with templates too, even though the actual class name is synthesized by the compiler. For example, given this template definition
template <class t>
class fred : public some_base_class
{
// . . .
}this code prints "class fred<int>":
some_base_class *p = new fred<int>;
cout << typeid(*p).name();This makes the create_obj function easy to write, even though create_obj is a member of a template class and the actual type of t is not known when the class template is defined. The typeid(an_object).name call evaluates to the name of the actual class that t represents in the class template.
There's another function, raw_name, that evaluates to the mangled class name. I didn't use it because I wanted the dynamic-creation stuff to be user friendly. If you don't use dynamic creation for anything but persistence support, changing the name to raw_name will speed things up marginally because the raw_name is more compact.
The only requirement forced on us by using typeid has to do with how the compiler implements the mechanism. The class name is effectively stored in an object's virtual-function table, so only those classes with virtual functions can be created dynamically. Most classes have a virtual destructor, if nothing else, so this restriction hasn't been much of a problem.
The other code of relevance is in dynamic.cpp (see Figure 8). Only two functions are defined here. Create (which was used earlier by the full name dynamic::create) actually manufactures objects. It traverses the linked list of factory_list_element objects and asks each one if it can manufacture an object of the desired class (by calling create_obj). When the loop terminates, new_object either points at an object of the required type or is NULL if no factory exists for that object.
The other function is the factory_list_ele destructor. When a factory is destroyed by going out of scope or being passed to delete, the factory destructor turns around and destroys the associated factory_list_element. The destructor for the list element removes the current element from its list, thereby preventing anyone from creating the associated object (which it can't possibly do because the factory has been destroyed).
With dynamic creation out of the way, let's look at File I/O, which we'll obviously need for storing the data associated with an object. One reason behind the current implementation is to decrease dependence on MFC, so I don't want to use a CFile to do I/O. On the other hand, I still want to use my persistence implementation in a document's Serialize function without having to jump through hoops. That is, all CDocument derivatives use MFC's persistence implementation by necessity. Nonetheless, I often want to use my own persistence system to transfer one of my own objects to or from the disk, and I want to be able to do that from within the CDocument derivative's Serialize function.
I can potentially talk to files using several I/O systems: an ANSI-C FILE pointer, an NT HANDLE, or an MFC CFile pointer (which could point at a CSocketFile if I'm doing network I/O or a COleStreamFile if I'm in an MFC OLE-server app that's talking to an OLE stream owned by the container). However, I don't want to write a separate version of my file I/O functions for each file I/O system. The solution is to create a base class that defines a standard interface, then implement derived classes for specific I/O systems. The persistent_store abstract class (see Figure 10) defines the general interface. Here's the relevant definition:
class persistent_store
{
public:
virtual ~persistent_store(){}
virtual size_t write( const void *buffer,
size_t size, size_t count)=0;
virtual size_t read ( void*buffer, size_t size,
size_t count)=0;
};All my file I/O functions talk to a persistent store using the write or read functions. The persistent_store class, however, is a pure abstract class-there's nothing in it but pure virtual functions. To use it, I'll have to derive several classes from persistent_store-one for each file I/O system that I want to support. I'll pass these derived-class objects to my functions, which will access them through base-class (persistent_store) pointers.
Figure 11 shows a derived class that encapsulates an ANSI-C FILE pointer. Using this derived class, I can do a I/O-system-independent write to a standard ANSI file like this:
void hello_world (persistent_store *out )
{
const char *message = "Hello world\n";
out->write( message, 1, strlen(message) );
}
void f( void )
{
FILE *fp = fopen("somefile", "w");
persistent_file file( fp );
hello_world( &file );
}The hello_world function thinks it's talking to a generic persistent_store when it's really talking to a persistent_file. The code is implemented (with a lot of other stuff) in persistence.cpp (see Figure 12). Bear in mind that my intention is not to implement a full-blown file I/O class, but to get read and write operations using different file I/O systems without caring which file I/O system I'm actually talking to. That's why the class has so few members.
Figure 13 (mfc_pers.h and mfc_pers.cpp) shows the persistent_store derivative for the MFC environment. Here's how to use it from a Serialize function:
some_document::Serialize( CArchive &ar )
{
if( ar->IsStoring() )
{
hello_world(persistent_CFile( ar ));
}
}Unfortunately, the wrapper class uncovers a serious design defect in the underlying MFC implementation of CFile (which is actually a problem with normal MFC persistence as well). You have to use a CFile to do I/O if you intend to take advantage of MFC's OLE 2.0 support for in-place editing. In an OLE app, the CFile passed to a server's Serialize is actually a derived-class COleStreamFile object. This way you can write to a container's OLE compound storage in a document's Serialize override without knowing it. You think you're writing to a normal CFile, but you're actually writing to a stream in some compound-storage object.
Unfortunately, CFile::Write is flawed in that it doesn't return the number of bytes written. In fact, it doesn't return anything. As a consequence, if something goes wrong-if your disk fills, or the CFile turns out to be a CSocketFile and the network connection breaks-there's no way to recover gracefully from the error. CFile::Write throws an exception instead of returning the number of bytes written. Even if you catch the exception, you can't do much because you don't know what's been pumped onto the disk or down the network. If you could guarantee that the CFile is actually a CFile (and not one of CFile's derivatives), you could call CFile::GetPosition before every write and then call CFile::Seek to return to your position before the write if anything goes wrong, but that's an ungodly kluge and won't work with a CSocketFile anyway.
There's no good solution here. There are two options. First, you can catch the CFileException object that's thrown when something goes wrong and then return 0 instead. Second, you can let the exception pass out of persistent_CFile::Write. (I've done the latter.) Either case results in an unrecoverable error. CFile::Write really illustrates why exception tossing isn't a replacement for returning error codes.
We've finally laid enough groundwork that we can actually discuss my persistence implementation (see Figure 14). There are some superficial similarities to MFC's system, but the underlying code is completely different. You must derive persistent objects from the persistent class that I'll discuss in a moment (in a manner similar to CObject), but there's no equivalent to the DECLARE_SERIAL and IMPLEMENT_SERIAL macros. You do need to provide an MFC-like serialize function in your derived class to override the virtual version in the persistent base class. Unlike the MFC Serialize function, you should do all your I/O using the persistent_store passed in as the first argument. The second argument tells you the direction (loading from or flushing to disk). Version-number support is provided here by means of a virtual function (the MFC implementation used the schema argument to the IMPLEMENT_SERIAL macro). Override the version function with one that returns the correct version number for the class definition. This way an error will be returned if you try to read a version from the disk that doesn't match the current class definition.
The process is somewhat simpler inside an MFC Serialize function because you don't have to worry about opening and closing files. If your CDocument derivative had the members
persistent_base *ptr_to_persistent_obj;
CStringArray *some_strings;you could transfer the associated objects to or from the disk in the Serialize function as follows:
/*virtual*/ void some_document::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
ar << some_strings;
ptr_to_persistent_obj->flush(
persistent_CFile(ar) );
}
else
{
ar >> some_strings;
ptr_to_persistent_obj = load(
persistent_CFile(ar) );
ASSERT( \
dynamic_cast<persistent_base*>(ptr_to_persistent_obj)\
)
}
}The persistent_base class is defined in Figure 14 and CStringArray is a standard MFC class. Again, I used the new C++ dynamic_cast mechanism to make sure I got the object I wanted on the load side. The ASSERT will fail if the object read from the disk isn't a member of the persistent_base class or some derivative of the persistent_base class.
Note that you can intermingle my persistence mechanism with MFC's version as I did in my example. As long as you read things from the disk in the same order as you flush them, using the same mechanism used for the flush, there are absolutely no problems.
The only real difference between the previous example and a base-class/derived-class situation is that you'll have to provide serialize functions at both levels and you'll have to remember to chain to the base-class serialize function from the derived-class serialize function. This requirement exactly mirrors the MFC implementation. In a multiple-inheritance scenario, you'll have to remember to chain to all base classes. Unlike MFC, you can (and probably should) make the class persistent a virtual base class, which solves the diamond-shaped class hierarchy problem. Here's a stripped-down example that shows you the structure:
class manager : virtual public persistent
{
virtual persistent::error serialize
(persistent_store &stream,
direction am_flushing);
};
class peon : virtual public persistent
{
virtual persistent::error serialize
(persistent_store &stream,
direction am_flushing);
};
class middle_manager: public employee, public peon
{
virtual persistent::error serialize
(persistent_store &stream,
direction am_flushing)
{
peon::serialize( stream, am_flushing );
manager::serialize( stream, am_flushing );
//serialize middle-manager fields here
}
};Figure 15 shows you how to use my persistence implementation with derived classes and templates.
All of this functionality is implemented with the persistent class declared at the end of persist.h (see Figure 10). The actual work is done in the flush and load functions at the bottom of persistence.cpp (see Figure 12). Notice that I've opted to return error codes (as listed in the enum inside the class definition) rather than tossing exceptions. The code is just cleaner this way.
The flush function in Figure 12 writes out a 126-byte block that contains the class name followed by a two-byte version number. It then calls your Serialize function to get the data out on the disk. Remember that all persistent objects derive from class persistent, of which flush is a member. This, combined with the typeid keyword, makes it easy to get the name of the derived class, even at the base-class level where the derived-class name isn't known at compile time. For example, I've used the following call to copy the class name into buf, even though I don't know the actual class name until run time:
strncpy( buf, typeid(*this).name(), sizeof(buf) );I could have done this with another virtual function provided by the derived class that would return the class name, but it's a lot easier for the compiler to do it. Moreover, there's no way to know the name of a template-generated class when you write the code since the name is created by the compiler. Consequently, you couldn't write a virtual-function overload in a template class that derived from class persistent because you wouldn't know what to return. That's the problem with the MFC persistence implementation when it comes to templates: it's incapable of providing a unique name for each class generated from a template expansion.
The load function at the very bottom of persistence.cpp loads the object from disk. It reads the class name that was stored by the flush function, then uses dynamic creation to manufacture an empty object of the type whose name it just read. Finally, it calls your virtual serialize override to populate the object.
So that's persistence. It's actually more complicated to describe than it is to do, and a persistence implementation is important to most programs, even non-MFC apps. It's a mystery to me why Microsoft hasn't reworked the MFC persistence system to take advantage of templates and the RTTI features of the compiler, but until they do the roll-your-own approach works just fine. Given the dynamic_cast and typeid now in the compiler and the persistence system presented in this article, there's nothing of importance left in CObject. This frees you from the necessity of deriving from it and gives you a lot more flexibility in your class-hierarchy design.
You can still use this new persistence implementation in an MFC app without problems. In fact, if you really wanted to do it, you could rewrite the current code to look more like MFC. Introduce shift operators as aliases for load and flush, define an empty DECLARE_ SERIAL and an IMPLEMENT_SERIAL that expanded to a class-factory definition, and so on. It's really a win/win situation.
From the June 1996 issue of Microsoft Systems Journal.