June 1996
![]()
How COM Solves the Problems of Component Software Design, Part II
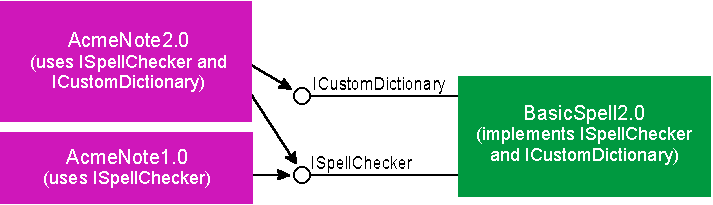
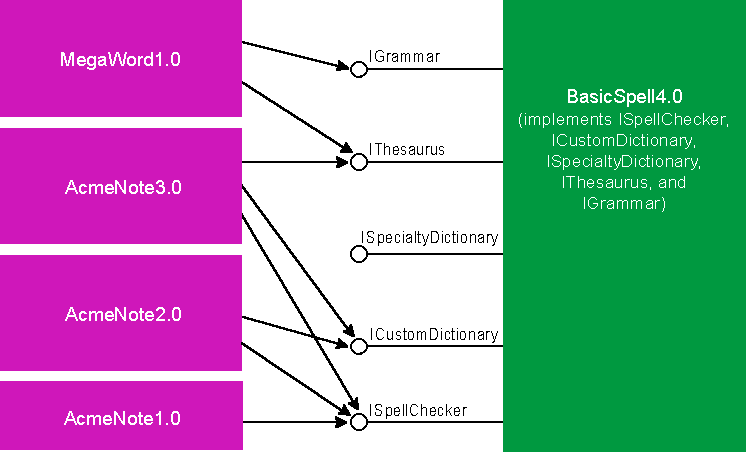
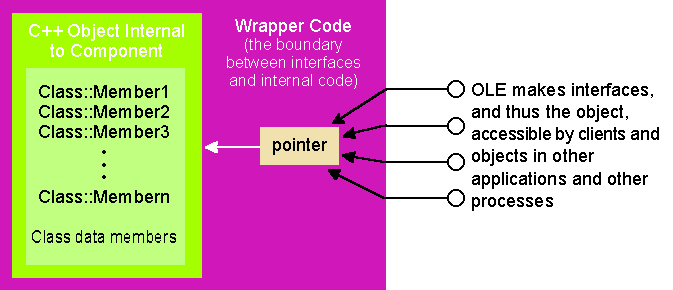
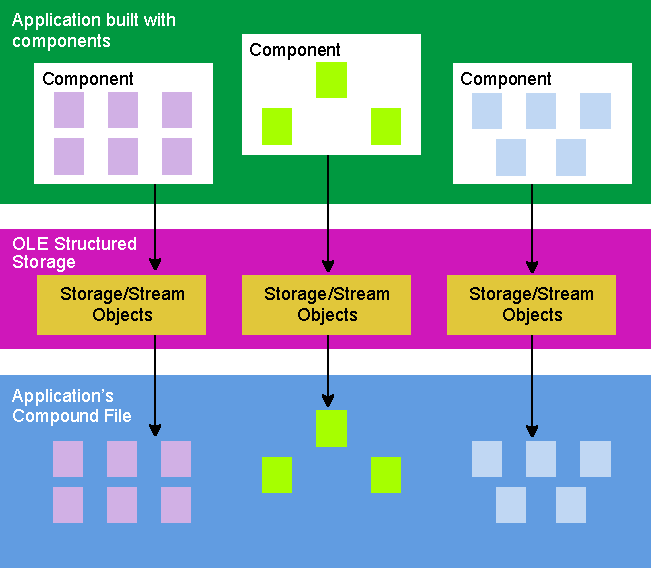
Kraig Brockschmidt Kraig Brockschmidt is part of the OLE design team at Microsoft, involved in many aspects of the continuing development and usage of this technology. He is author of two books, Inside OLE 2 and Inside OLE 2nd Edition (Microsoft Press). The Component Object Model (COM) and OLE solve many problems in component software development. Last month, I examined the fundamentals of the COM architecture, concentrating on versioning. Let's pick up where I left off with QueryInterface and the IUnknown member function. QueryInterface makes multiple interfaces possible; once a client obtains the initial interface pointer to any object, it obtains other interface pointers to the same object through QueryInterface. A concrete example will illustrate how the QueryInterface idea solves the versioning problem. Consider a COM-based specification for the category SpellCheck1.0, which indicates that a spell checker object like BasicSpell1.0 implements the ISpellChecker interface. AcmeNote1.0, the client, uses BasicSpell1.0 through this interface (see Figure 1). At this point in time, there is little tangible difference between the COM design and the old-style DLL programming model with an exported function. Figure 1 A Version 1.0 Object and its Client Say you want to write the SpellCheck2.0 specification, adding a custom dictionary feature that includes the AddWord and RemoveWord functions. With COM, you always introduce these functions in a new interface, but you have a number of ways to do this. First, you could introduce ISpellChecker2, which is derived from ISpellChecker but has an entirely distinct IID, as required. Objects would implement this new interface, thus implementing the ISpellChecker. The advantage here is the two interfaces end up sharing the same vtable, reducing per-instance memory overhead. This is important when the category being defined will typically lead to hundreds or thousands of object instances at run time. Sharing the vtable saves 16 bytes per instance-the lpVtbl pointer plus the IUnknown entries in the table. For custom controls, savings like this are important. A spell checker doesn't need to worry about this because it will usually have only a single instance per process. So in this case this design offers no advantages. A second method is to introduce ICustomDictionary, which would contain the two new functions (plus the IUnknown members). Objects would implement this as another interface alongside ISpellChecker. This is the way most people would do it. Yet another design would be to introduce two new interfaces, say ICustomDictionaryAdditions and ICustomDictionaryEditing, to separate the dictionary features of adding words and editing contents. In the spell checker, there is little to gain from this separation; in other designs different functions may need different interfaces. (You usually want to avoid going to the extreme of defining a bunch of interfaces with single member functions. This complicates client programming by forcing two or three calls per function, one to QueryInterface, one to the member, one to Release, depending on how pointers are cached.) Let's go with the second design and define ICustomDictionary with its own IID: Now that you have the SpellCheck2.0 specification, the developers at Basic Software and Acme Software will eventually decide to upgrade their products to fit it. The old-style DLL model made it difficult for both companies to upgrade their products independently. But this is exactly what COM was designed to support! Either company can add support for the new interface without breaking compatibility with the old version of the other. Say that Basic Software chooses to release BasicSpell2.0 first, where the spell checker object now supports both ISpellChecker and ICustomDictionary. The developers don't have to change anything in the existing ISpellChecker code (except for its QueryInterface implementation)-the version 1.0 code simply continues to exist and COM's multiple interface design encourages this. When AcmeNote1.0 encounters this new object, it sees exactly what it did with BasicSpell1.0 (see Figure 2). Because AcmeNote1.0 doesn't know about ICustomDictionary, BasicSpell2.0 appears to be BasicSpell1.0; that is, the two are perfectly polymorphic, and no compatibility problems arise. Figure 2 Old Clients See Only Expected Interfaces Now suppose the reverse happens and Acme Software releases AcmeNote2.0 first. AcmeNote2.0 is written to enable a custom dictionary feature if the spell checker component it finds supports that feature. At this point, only BasicSpell1.0 exists. But because AcmeNote2.0 has to call QueryInterface for ICustomDictionary to use that feature, it must be coded to expect the absence of the interface! (If a client requests interface ICustomDictionary when initially creating the object, that request will fail and no object is created. A client can specify this interface on creation if it wishes to work only with upgraded objects. The client would then provide a meaningful error message, or at least more meaningful than "Call to undefined dynalink.") The COM programming model forces clients to handle both the presence and absence of a particular interface. Doing this is not at all difficult, but since you have to call QueryInterface you have to be prepared. So when AcmeNote2.0 encounters BasicSpell1.0 as shown in Figure 3, its request for ICustomDictionary fails and AcmeNote simply disables its custom dictionary features. Figure 3 New Clients Degrade Gracefully As mentioned last month, the easiest DLL programming model encourages clients to expect the exported functions. Catastrophic failure results when those functions are absent-it takes extra work to handle such a case robustly. Therefore, few client programs actually bother. In marked contrast, the COM programming model forces a client to prepare for the absence of interfaces. As a result, clients are written to robustly handle such absences. What makes the COM model even more powerful is that when a client discovers the presence of an interface, it achieves richer integration with the object. That is, expecting the absence of interfaces means the client still works in a degraded situation (as opposed to failing completely). When interfaces exist on an object, things just get better. To demonstrate this, let's say that AcmeNote2.0 creates an instance of the spell checker object only when the user invokes the Tools/Spelling command. When a user spell checks with BasicSpell1.0 installed, they'll get the basic features. Without closing AcmeNote2.0, the user now installs BasicSpell2.0. The next time the user invokes Tools/Spelling, AcmeNote2.0 finds ICustomDictionary is present, so it enables additional features unavailable before. That is, once AcmeNote2.0 discovers the availability of the feature, it can enable better integration between it and the component (see Figure 4). Older clients like AcmeNote1.0 continue to work as they always have. Figure 4 Interaction Between Clients and an Upgraded Component This improvement in integration and functionality is instant and occurs while the system is running. Without having to turn everything off, you can install a new component and instantly have that component integrate with already running clients, providing new features immediately. Last month you saw what happened when an older version of a DLL accidentally overwrote a newer version-any clients that were implicitly linked to the newer version started to show "Call to undefined dynalink" messages and wouldn't run at all. COM completely solves this problem. Suppose a user installs another application that itself installs BasicSpell1.0 and accidentally overwrites BasicSpell2.0. If you were using raw DLLs and AcmeNote2.0 had implicit links to BasicSpell2.0, AcmeNote2.0 would no longer run at all. But with COM components, AcmeNote2.0 runs just fine; when the user invokes Tools/Spelling, AcmeNote2.0 would simply not find ICustomDictionary and not enable its custom dictionary features. Again, the client is prepared to work well without certain object interfaces. In addition, since interfaces completely avoid implicit linking, the kernel will never fail to load the application. It should be obvious now that COM's support for multiple interfaces solves the versioning problem discussed last month for at least the first revision. But the same solutions also apply over many subsequent versions (see Figure 5). Here BasicSpell4.0 has ISpellChecker, ICustomDictionary, ISpecialtyDictionaries, and maybe even IThesaurus and IGrammar (extra features, nonetheless). Figure 5 One Object Can Serve Many Different Clients This simple version of the object now supports clients of the SpellCheck1.0 specification, clients of the SpellCheck2.0 specification, and those written to specifications that involve the other three added interfaces. Some of those clients may only be using the thesaurus features of this object, so they never bother with interfaces like ISpellChecker. Yet the single object implementation supports them all. In addition, this new object server can overwrite any old version of the server. Last month you saw that building components in the DLL model typically leads to redundant code living in multiple copies of different DLL versions, like VBRUN100.DLL, VBRUN200.DLL, and so on. COM gives you a way to factor the differences from version to version so that you can keep the old code available to old clients and provide new code to new clients all within one server module. Of course, the newer modules will be larger than the old one�simply because there's more code for every added interface. However, because all the code is encapsulated behind interfaces, the object can employ many different implementation tricks to reduce the basic module size, improve performance, and minimize memory footprint. In COM, an object is not required to allocate an interface's function table until that interface is asked for�each version of an object can thus choose to initially instantiate those interfaces that are used more often, leaving others out of memory completely until needed. An object can also free those interfaces when they are no longer needed, reducing the overall working set. Code-organization techniques help keep the interface code itself out of memory until it is needed. To minimize the server's load time, only a few code pages are marked "preload." Alternately, you can place the rarely used code in another module altogether, using the object-reuse technique called aggregation to instantiate interfaces from that module only when necessary, while still making those interfaces appear as part of the object itself. Over time, the code for the less frequently used interfaces will migrate from being placed in load-on-demand pages in the object module, to being separated into another module, to being discarded altogether when those interfaces become obsolete. At such a time, very old clients may no longer run well, but because they were written to expect the absence of interfaces, they'll always degrade gracefully. COM offers a truly remarkable means for removing obsolete and dead code from a system. There is often a fair bit of debate in the trade media about whether or not COM and OLE compete with or complement "objects" or "object-oriented programming." Some say that OLE doesn't support "real" objects, whatever they are. Some think OLE competes with OOP languages like C++ or with frameworks like MFC. None of these claims are true, because COM and OLE were designed to complement existing object technologies. COM and OLE do not compete with object-oriented languages or frameworks because they solve different problems. Languages and frameworks are for programming the internals of components and objects. When you want different objects written by different people to interoperate, especially at different times and different spaces (in other processes and running on other machines), COM and OLE provide the means for doing so. In fact, it is easy to see how one might take a language-based (such as C++) object and create a code wrapper that factors the language object's interface into COM-style interfaces, as shown in Figure 6. This makes the language object suddenly available to use from any other client process through the COM mechanisms. For more information on creating a wrapping layer for C++ objects that turns the C++ "interface" into COM interfaces, see "From CPP to COM" by Markus Horstmann on the Microsoft Developer Network CD or on http://www.microsoft.com/msdn/library/technote/cpptocom.htm. Figure 6 Wrapping the Language-based Object in Interfaces This is exactly what MFC does to provide OLE support: turn the more complex OLE interfaces for certain high-level features (such as compound documents and OLE controls) into simplified C++ classes. So while object-oriented languages are great ways to express object-oriented concepts in source code and great ways to express implementation details in source code, OLE is the plumbing concerned with the communication between pieces of binary code in a running system. Frameworks like MFC provide default implementations as well as wrappers for the communication layers. COM and OLE are to MFC as mathematics is to a calculator. A calculator makes mathematical operations effortless but you still have to understand why you are using those operations. In the same way, MFC makes certain OLE features very simple to incorporate into an application, but you still have to understand why you want those features. If you can take a language-based object and wrap it in COM/OLE interfaces, is it still an object when seen from a COM/OLE client? Does a client see an entity that is encapsulated? Does that entity support polymorphism? Does that entity support reuse? COM supports all three. Objects in COM behave as "real" objects in all the ways that matter. The expression of the particular concepts is a little different, but the same ends are achieved. How does COM support encapsulation? Easy: all implementation details are hidden behind the interface structures exactly as in C++ and other languages; the client sees only interfaces and knows nothing about object internals. In fact, COM enforces a stricter encapsulation than many languages since COM interfaces cannot expose public data members-all data access must happen through function calls. Certainly language extensions for compilers can let you express public members in source code, but on the binary level all data is exchanged through function calls, which is widely recognized as the proper way to do encapsulation. How does COM support polymorphism? This happens on three different levels. First, two interfaces that derive from the same base interface are polymorphic in terms of that base interface, exactly as in C++. This is because both interfaces have vtable entries that look exactly like those of the base interface. All interfaces are derived from IUnknown and thus look exactly alike in the first three entries of the vtable. When you program COM in C++, you actually use C++ inheritance to express this polymorphic relationship. When programming in C, the interface structures are defined as explicit structures of function pointers where polymorphic interface structures share the same set of initial entries in the structure. Second, object classes (and instances) that support the same interface are polymorphic in that interface. That is, if I have two object classes that both support an interface like IDropTarget, the exact same client code that manipulates the IDropTarget of one object class can be used to manipulate the same interface implemented in another class. Client code for this interface exists in OLE's system-level drag and drop service, which uses this interface to communicate with any potential recipient of a drop operation, which might be an application, a control, or even the desktop itself (on Windows NT� and Windows� 95). Third, object classes that support the same set of multiple interfaces are polymorphic across the entire set. Many service categories expect this. OLE's specification for embeddable compound document objects, for example, says that such objects always support the interfaces IOleObject, IViewObject2, IDataObject, IPersistStorage, and a few others. A client written to this specification can host any embeddable object regardless of the type of content, be it a chart, video clip, sound bite, table, graphics, text, and so on. All OLE controls are also polymorphic in this manner, supporting a wide range of capabilities behind the same set of polymorphic interfaces. How does COM support reuse? You may be wondering if I mean inheritance. No-I mean reuse. Inheritance is not a fundamental OOP concept-it's how you express polymorphism in a programming language and how you achieve code reuse between classes. Inheritance is a means to polymorphism and reuse, not an end in itself. Many defend inheritance as a core part of OOP, but it is nothing of the sort. Polymorphism and reuse are the things you're really after. You've just seen how COM supports polymorphism. It supports reuse through two mechanisms. First, containment simply means that one object class uses another class internally for its own implementation. That is, when the "outer" object is instantiated, it internally instantiates an object of the reused "inner" class, just as any other client would. This is a straightforward client-object relationship where the inner object doesn't know that its services are being used in the implementation of another class-it just sees some client calling its functions. The second mechanism is aggregation, a less common technique through which the outer object takes interface pointers from the inner object and exposes those pointers through its own QueryInterface. This saves the outer object from using any of its own code to support an interface, and it's strictly a convenient way to make certain kinds of containment more efficient. This does require some extra coding in the inner object to make its IUnknown members behave as the outer object's IUnknown members, but this amounts to only a few lines of code. This mechanism even works when multiple levels of inner objects are in use, where the outer object can easily obtain an interface pointer from another object nested down dozens of levels deep. In this case, all delegation of any inner object's IUnknown to the outer object's IUknown is a single call. So now you've seen in this and the previous article why COM is designed like it is and the problems that COM solves. You've seen how COM/OLE complements OOP languages and frameworks. You've seen how COM supports all the fundamental object concepts. So what, then, is OLE itself? Why do people make such a fuss about OLE being big and slow and difficult to learn? The reason is that Microsoft has built a large number of additional services and specifications, like location transparency, on top of the basic COM architecture and COM services. Taken by itself, COM is simple, elegant, and absolutely no more complex than it has to be. With the right approach, any developer can learn the core of COM in a matter of days and see its real potential. However, all the layers of OLE built on COM are overwhelming. There are over 150 API functions and perhaps 120 interface definitions averaging six member functions each. In other words, nearly a thousand pieces of functionality that continue to grow! Trying to understand what everything is about is daunting. It's time for me to provide an overview. All functionality in OLE falls into three categories: API functions and interfaces to expose OLE's built-in services, which includes a fair number of helper functions and helper objects. API functions and interfaces to allow customization of those built-in services. API functions and interfaces that support creation of "custom services" according to various specifications. The following sections describe each of these in a little more detail. One reason OLE seems so large is that it offers quite a wide range of native services, some of which I've already discussed: The services of implementation location, marshaling, and remoting are obviously fundamental for objects and clients to communicate across any distance. As such, these services are a core part of a COM implementation on any given system. Other services are less fundamental. They're implementations of standards that support higher-level interoperability. Structured storage is one such standard. It describes a "file system within a file" service so software components can cooperate in sharing a disk file. Because such sharing is essential to cooperation between components, OLE implements the standard in a service called compound files. This eliminates all sorts of interoperability problems that would arise if every component or client application had to implement the standard itself. To see why a standard like this is important, let's look briefly at how today's file systems themselves came about. When computers first gained mass-storage devices, there wasn't anything called an "operating system." What ran the computer was the application, which did everything and completely owned all system resources. The application simply wrote its data wherever it wanted on the storage device, managing the allocation of the sectors itself. The application pretty much saw the storage device as one large contiguous byte array in which it could store information however it wanted. Soon it became desirable to run more than one application on the same machine. This required some central agent to coordinate the sharing of the machine's resources, such as space on the mass-storage devices. Hence, file systems were born. What a file system does is provide an abstraction layer above the specific allocation of sectors on the device. The abstraction (file) is made up of usually noncontiguous sectors on the physical device. The file system maintains a table of the sequence of sectors that make up the file. When the application wishes to write to the disk, it asks the file system to create a file, which really means "create a new allocation table and assign it this name." The application then sees the file as a continuous byte array and treats it as such, although physically the bytes are not continuous on disk. In this way the file system controls cooperative resource allocation while still allowing applications to treat the device as a contiguous byte array. File systems like this work great as long as all parts of the application itself are coordinated. In the component software paradigm, this is no longer true. Applications might be built from hundreds of components. How can these components work cooperatively in the creation of a single file? One solution would have all the components talk to one another through some standardized interfaces so they can negotiate who gets what part of the file. It should be obvious that such a design would be extremely fragile and horrendously slow. A better solution is to repeat the file system solution-after all, the problem is the same: different pieces of code having to cooperate in utilizing an underlying resource. In this case the resource is a file, not a storage device, although conceptually they're identical. OLE's structured storage specification describes the abstraction layer that turns a single file into a file system itself, in which you can create directory-like elements called storage objects (that implement IStorage) and file-like elements called stream objects (that implement IStream), as shown in Figure 7. Figure 7 OLE Structured Storage Lets Components Share a File OLE's implementation of this standard controls the actual layout of data bits inside the file. The software components themselves see stream objects as contiguous byte arrays, so the experience you have working with files translates directly to working with streams. In fact, there is a one-to-one correspondence between typical file-system APIs such as Read, Write, and Seek and the member functions of the IStream interface through which you use a stream object. Structured storage eliminates the need for each component in the application to negotiate its own storage requirements-instead, this is coordinated in OLE's implementation. The only necessary bit that the application must communicate to components is to pass each of them an IStorage or IStream pointer, depending on the object's persistence mechanism. If an object implements IPersistStorage, it is indicating that it wants an IStorage as a basis for storage. Within the storage object it then creates substorages and streams as necessary. If an object implements IPersistStream, on the other hand, it is indicating that it only needs a single stream. Some of the functions in OLE's API and some of the interfaces deal with customizations to OLE's native services. One example will suffice to describe customization. OLE's implementation of the structured storage model typically works with an underlying file on a file system. You can customize this behavior by redirecting the file image to another storage device through what is called a LockBytes object (that implements ILockBytes). All this object knows how to do is read or write a certain number of bytes in a certain location on some storage device. By default, OLE itself uses a LockBytes that talks to a file on the file system. You can implement your own LockBytes (or use OLE's other implementation that works on a piece of global memory) to redirect data to a database record, a section of another file format, a serial port, or whatever. A few OLE APIs allow you to install your LockBytes underneath the storage implementation. When someone writes data to a stream through IStream::Write, for instance, that data ultimately shows up in your ILockBytes::WriteAt code, allowing you to place it anywhere you want. OLE itself can only provide a limited number of native services-specifically those that need to be centralized and standardized. A great deal of OLE's functionality is there to support the creation of what I call custom services that fit into one or more service type specifications. There are three primary (and sometimes complex) type specifications at present, each of which involves a large number of OLE API functions and interfaces: Each specification describes the general interaction between an object of the type and a client of such an object. You can implement a wide variety of objects that fall into these categories. A sound bite, a video clip, a chart, a picture, a presentation, text, and a table are all instances of the embeddable compound document object type. Buttons, edit boxes, labels, check boxes, radio buttons, tabbed dialogs, list boxes, scroll bars, toolbars, sliders, dials, and status lines are all examples of custom controls, each of which can be implemented as an OLE control. OLE automation is typically used to create objects that expose the functionality of an entire application like Microsoft Word such that a scripting engine like Visual Basic can drive that application to perform certain operations without the need for a user to execute the steps (that is, automation in its most generic sense). In addition to these Microsoft-defined categories, other industry groups have defined service categories for their particular needs, such as real-time market data, health care, insurance, point-of-sale, and process control. Other groups are actively working on more specifications. No matter who defines the service, many people can implement clients or objects according to the specification, which describes the abstraction that both sides use to view the other such that all clients are polymorphic to the objects and all objects of the category are polymorphic to clients. This means that COM is an open architecture. Anyone can create and define new service categories without any input or involvement on Microsoft's part and without any dependency on Microsoft enhancing its operating systems. Anyone can define new service categories, publish them, implement components and clients around them, and deliver those components to customers. The true "openness" of an architecture lies in its design and extensibility, not just in the process through which the design occurs (which at Microsoft is open-it's just not committee-based!). COM and OLE enable decentralized and asynchronous innovation, design, development, and deployment of component software, the absolute essential elements of a successful distributed object system. You've seen why COM and OLE exist, the problems it was designed to solve, the services it provides, and the flexibility inherent to its design. But you're probably asking one question: what does OLE mean to me? OK, two questions: what does OLE mean to my project? If there's one word to describe what OLE is all about-technically speaking-it is integration. Think about what integration means to you and the projects you're working on. Do you think about integration with the system? How about integration with other applications? Or integration with third-party add-on components? Or integration with the World Wide Web? However you answer these questions, OLE probably has an answer for you. For example, the Windows 95 and Windows NT 4.0 shells have extension features based on OLE components. Integration between apps, whether through OLE documents, OLE automation, drag and drop, or other private protocols, almost always involves OLE. COM/OLE provides an ideal architecture for plug-in or add-on models because it solves all those problems that appear across multiple versions and revisions of interfaces. Everything you need to exploit this integration on a single machine is already in place: COM/OLE in its present form shipped nearly three years ago and is already installed in tens of millions of desktops. Since that time Microsoft and other parties have continually added more powerful enhancements that add more capabilities, such as the introduction of Distributed COM in Windows NT 4.0. But what's it all for? OLE's purpose is to make true component software a working reality. Why all this fuss about component software? It is a long-standing dream in the software industry to quickly assemble applications from reusable components. Object-oriented programming brings you closer to that goal to some extent, but it is limited to source code problems. In the real world, problems also need to be solved in a binary running system, because you cannot recompile and redeploy all the software in a system every time one object implementation needs to change. COM and OLE were designed specifically to address this. This is why COM is based on a binary standard, not a language or pseudo-language standard. COM is the glue that makes component integration work. But we must realize that, as an industry, the purpose of component software is more than just making it easier for developers to assemble applications: no matter what your methodology, developer-written code cannot perfectly match customer needs when they arise. The problem is that by the time you can deliver a prepackaged solution, the customer's problems and needs have changed-many times drastically. (Currently the application backlog, as it's called, is three years, not a matter of months.) Customers care about immediate solutions to their present problems, not OOP, languages, or object purity. And if customers care about solutions most, then so should you, because customers are the single source of income in the computer industry. One way we've tried to solve this problem is by creating ever more complex and generic tools. These do-it-all applications, with every feature imaginable, generally require the user to mentally map their problem to the tool. This is exactly why software seems so hard to use, because this mental mapping is so difficult. So what's special about component software? Component software enables users to quickly and easily construct the exact applications they need to solve immediate problems. This might be done by adding a component to an existing application to provide some new capability that wasn't there before. In a sense, the user has created a new application by making a small customization to an existing one. Many customer problems can be solved this way, and it requires a strong component architecture to do it. COM is just such an architecture. But where will these components come from? Today there exists a tremendous amount of software functionality inside large monolithic applications. Unfortunately, being part of a monolith, that functionality is only available to that one application. Through componentization, a large monolithic application is broken into smaller and smaller components, thereby making that functionality available in many other ways. The design of COM and OLE allows this large-scale componentization to occur gradually while allowing reintegration of small components into larger ones. You can first make components available from within a large EXE that is riddled with legacy code. Then, behind the scenes, you can rewrite that code and break it out into smaller and more efficient pieces as you see fit. The COM architecture provides a smooth path through the whole componentization process-from legacy code to small and fast components. You don't have to reengineer everything to receive benefits.
[uuid(8e47bfb0-633b-11cf-a234-00aa003d7352), object]
interface ICustomDictionary : IUnknown
{
HRESULT AddWord([in,string] WCHAR *pszWord);
HRESULT RemoveWord([in,string] WCHAR *pszWord);
}

Overwriting DLLs
COM and OLE's Problem Space
Object Concepts in COM/OLE
What OLE is Made Of
OLE's Native Services
Custom Services
OLE's Purpose in Life