|
Collaboration on the Internet removes the user's dependency on the location of information and services by allowing many users to interact with information freed from the constraints of monolithic applications. But collaboration in an Internet environment is a particularly difficult task.
The Application Building Litmus Test
So you're convinced that you want to take advantage of the Internet for deploying applications. How can you be sure that the tools you select or the methods you employ for building and publishing your applications are going to yield the best results? Let's develop a litmus test to ensure that the solution you choose will meet your objectives. When building applications for the Internet, ask yourself the following questions: What architectural features mesh most logically with the structure of the Internet? What are the requirements for a development framework to create Internet object-based applications using Visual C++? Why didn't I become an accountant? How can I best use an Internet client/server architecture with the Visual C++ development environment I already use? What is a good Internet application development solution, not just for the Internet of today but into the future?
Let's take a brief look at some of the features you need to get your C++ objects to the Web.
Just Enough Java
An important part of the litmus test is the application-deployment mechanism. Applications should be able to run without needing client software or plug-ins to be installed prior to connection. This dynamic deployment mechanism enables all or part of the application to be downloaded to the client machine and run locally, allowing the application to benefit from local machine services such as the display, input devices, and local interactive controls in the user interface. Application performance and interactivity are made possible because code is downloaded and run on the local machine.
What parts of the application really need to be downloaded and run? Certainly not the application logic. Application logic interacts with data not on the client machine (for example, corporate databases, data repositories, and shared information services). In addition, the application logic I'm talking about consists of C++ objects running on the server.
The part of the application that gets downloaded and run on the client machine is the presentation layer. But how do you get the presentation onto the client machine? This presentation layer includes the GUI elements along with just enough application logic to convert user interface events into object state changes. These state changes, and only these state changes, are what your client will send across the Internet to the server.
One way to do this is by using what I call "Just Enough Java." This use of Java
is simply pragmatic. Besides providing a dynamic download of the presentation layer, Java offers platform independence, effectively making your Visual C++ applications
cross-platform. In addition, as a client-side solution, Java takes advantage of its virtual-machine security model.
Thinner is Better
Thinner is better. No, this isn't an infomercial for the Thighmaster. When it comes to Internet clients, thin is definitely in. The interesting thing about the Internet is that most of the data and logic that users want to access is not on their machines. What do you send down to the client machine to successfully access and deploy an application? Here, less is more. Why? Let's review the fat client problem.
Practically all of the work done with Java to date uses a fat client model. That is, the application logic, not just the presentation layer, is downloaded to the client machine for execution. Why is this a bad approach? First of all, by downloading the application logic to the client, the logic is displaced from the content the user is trying to access. This violates the basic object-oriented model of data/logic encapsulation. The application has to be split, code has to be sent down to the client, and a network protocol has to be created and maintained by the developer. The whole process involves creating a distributed application, greatly increasing the complexity of writing an application simply to move it to the Internet.
Another problem with fat clients is the burden that the application places on the client. If too much of the processing burden takes place on the client machine or device, fewer types of client applications and platforms will be able to access and run that application. This will become a problem when Internet appliances become popular. Cramming a large application into a narrow-bandwidth pipe and into a limited-performance client device inhibits your ability to move your application to the net. The fat client approach is not appropriate when you cannot rely on the power or capability of the client. So, if you've got visions of being able to access your Visual C++ application on a Sega Genesis machine, a cellular phone, or a PDA device, remember: the thinner the client, the fewer restrictions on deploying your application.
Fat clients also suffer because of the bandwidth limitations of the Internet. Since the application logic is on the client in a fat client approach, large amounts of data must be moved to the client machine before the application is able to process it for the user. This movement of data puts an unnecessary bandwidth burden on the network connection. This is problematic because the Internet is largely a low-bandwidth, high-latency environment not conducive to large amounts of network traffic.
Finally, the fat client inhibits collaboration. It becomes a burden to replicate a common state across multiple machines when the application object state is controlled in a distributed fashion. In other words, if the client contains logic that changes a shared object's state, that state must somehow be updated on other clients currently looking at or interacting with that object. This becomes a tremendous burden on the developer. The problem can be remedied somewhat through an RPC or object proxy solution, where multiple clients are accessing centralized data at the server. But client synchronization and data access control are typically left to the developer, since RPC-like mechanisms don't deal with the replication issues associated with collaborative applications.
RPC approaches also include the burden of deciding where to split the application between the client and the server. The developer must write a distributed application where some of the code is Java, JavaScript, or VBScript and the rest is a server object written in C++. Doesn't sound like a very scalable development solution, does it? Besides having to decide which parts of the application are where, the developer has to make coding decisions about what data is changed, whether it is shared or not, and so on. Some technologies attempt to abstract the distributed nature of the application, often requiring the use of a proprietary language, generally resulting in a loss of control over performance issues.
When it comes to deploying applications with the Internet architecture, thinner is better because it allows you to distribute the presentation, not the application. Rapid application access is possible since you do not have to download the entire application. A minimal burden is placed on client resources (or smaller dependency on hardware configuration), and development complexity is reduced because you don't have to write a distributed application. So the litmus test includes a check for thin client Internet application deployment.
Transparent Collaborative Support
Another issue for the litmus test is in the area of collaboration. Collaboration should be a central theme when you talk about the Internet. A Web development effort should not be considered without taking into account how multiple simultaneous users will access that application. Any environment or framework should be able to abstract or automate collaborative capability at some level.
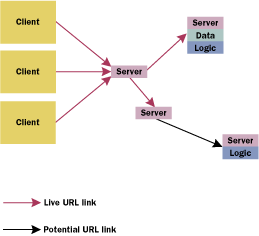
I believe that there are two ways in which collaboration can be made possible with minimal developer involvement. The first would be through a codeless presentation model. By codeless I mean that the presentation layer of an application would contain as little application logic as possible (or none) that directly manipulates shared object states. What this means is that object state manipulation code shouldn't be downloaded to the client machine. In an ideal codeless presentation model, the presentation logic executed on the client machine deals only with user interaction (GUI events), transforming those events into data state change commands. Client data state changes should then be packaged and sent to the server to update its objects' states and, in turn, update any other interested clients currently looking at the state of those server objects. The logic that operates on the shared data would be an encapsulated C++ object running on the server machine. The presentation layer would represent a remote client to that object's services. The central shared object would be accessed by multiple simultaneous clients.
Another collaboration technique allows many clients to have simultaneous dynamic access to a running application. An application framework with such a runtime binding capability could allow clients to attach or detach a particular application during program execution. Since application logic is just another kind of content that can be encountered on the Internet, the same should be the case for applications as well. Runtime binding on an application would allow a client to access an application object's state without involving the shared object directly. By dynamically allowing access to the C++ object, the details for client attachment to that object wouldn't have to be handled by the implementor of the class. This general lack of direct developer involvement in the control of collaboration access would greatly simplify the process of writing a multiuser-access Internet app.
State Change-based Client/Server Connection
Available bandwidth has always been a limiting factor for effective deployment of applications over the network, so the litmus test should include an examination of the bandwidth impact.
Where do you divide an application to ensure that the minimum amount of presentation logic is sent to the client and that the application runs optimally over the net? The division shouldn't take place at the event level, since many more events occur on the client than are necessary to maintain an application object's state. Passing events from one side to the other causes the application to create many data round trips before users see the results of their interaction on the screen.
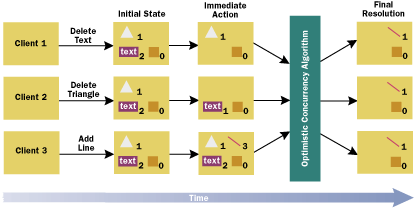
For example, many events happen with a scroll bar interactor, but the important piece of information is the thumb position produced through user interaction. If the scroll bar controls the value of a numeric data member of a C++ object, then only the final scroll bar thumb position value needs to be sent across the network to update the server-side object. This transfer of state information is the minimum information exchange necessary to maintain synchronized application state over a network. To minimize state-transfer bandwidth, you need to send only that part of an application object's semantic state that is currently relevant to the presentation. A core question of GUI research over the last decade has been how best to implement the state transfer.
A model is needed that utilizes the state-based nature
intrinsic to object-oriented development. Such a model is essential for optimal communication between the server application and the many clients that can simultaneously access that application. Ideally, the implementation of C++ objects need not be involved directly with this state-change notification scheme. Object state management would then remain external to the application object in the same way a client would access the services of an object without the object being concerned with the details of how it is being used. This approach is appealing because it is not cluttered with unnecessary dependencies such as how the object is used, deployed, accessed, and so on.
Thin Client Three-tier Architecture
The litmus test just created effectively defines a new application architecture for the Internet. This model, which I call the thin client three-tier architecture, can be differentiated from the traditional three-tier client/server approach in two ways. First of all, in the thin client model, all the application-specific logic is running on the server. The logic could be distributed on the server side over many machines, but the approach is inherently server-side. Secondly, in the thin client model, only state changes are exchanged between the client and the server. In the traditional three-tier model the communication between the client and the server is based on remote procedure calls (RPCs). Implementing an application with RPCs requires application-specific logic on the client. Application partitioning is typically left to the developer. The problem with the traditional three-tier architecture with respect to the Internet is that it exhibits many fat client characteristics. It is important to note that a thin client approach allows objects to be accessed by multiple clients simultaneously and in real time.
Traditional client/server approaches, allowing only a single client to access a server process, were OK for the single-user desktop application, but inadequate and too inflexible given the multiclient access capabilities of the Web. Traditionally, multiuser access to data was limited to the multiuser capabilities of the database engine. The thin client approach enables multiuser control of data and services of application objects. The traditional client/server approach controls data and services at the level of the database engine where the context of the data with respect to its associated logic is limited or nonexistent.
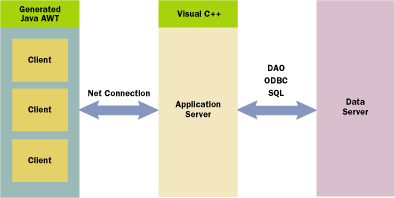
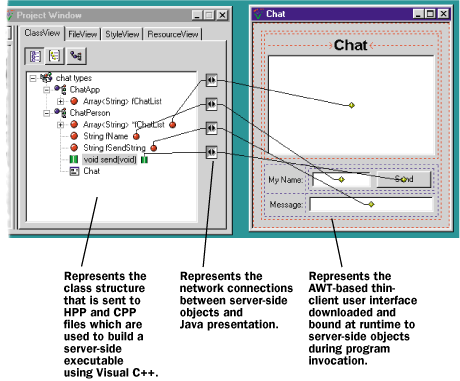
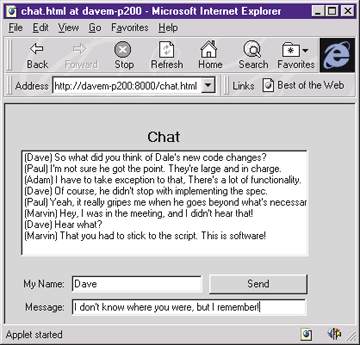
Let's take a look at the implementation of the thin client three-tier architecture. Client, server, and database pieces can be interchangeable. The Java AWT toolkit provides the API for the user interface of an application. The presentation layer (the thin client) can actually be an applet downloaded from the server and run within an Internet browser. The applet contains user-interface widgets such as scroll bars and buttons and enough embedded network communication machinery to respond to and initiate state changes between the client and the server.
A client-side visual element is associated with a specific server-side object. For example, an AWT edit box on the client can be "connected" to a data member of a C++ object running on the server. When a value is typed into the edit box on the client-side applet, a data state change message is sent to the server. In this example, an edit box is a Java applet with a "network" line connected to a server-side object's data member. Any other clients viewing that data member through their interfaces will also update automatically to reflect the object's new state.
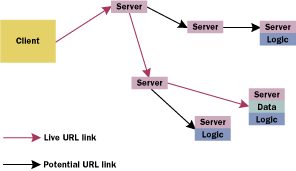
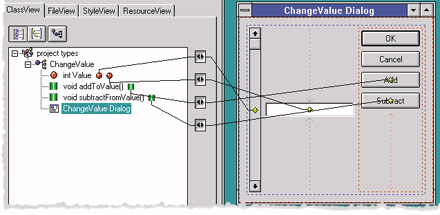
Although the client is small, it is also smart enough to know the kind of C++ objects running on the server to which it is connected. The client sends network messages when the user interacts with the AWT control, and receives state changes initiated by the server (for example, when the application logic changes the data member). The generated presentation layer then becomes a client to the server-side C++ objects. The entire client can be generated so that, by default, the developer isn't required to write any code (see Figure 6).
|