By Luke Chung
The ability to analyze data in Access is a fundamental skill that all developers must master. The better you are at organizing your data and knowing how to analyze it, the easier your application development will be. There are lots of ways to analyze data, and different techniques must be used, depending on your goal. However, there are two fundamentals that must be understood:
There are lots of articles and books on data normalization. They usually scare people, including me. I'm not going to get into a theoretical discussion of the pros and cons of data normalization levels. It comes down to storing and retrieving data efficiently. Achieving this depends on the database used, so the more you understand how to manipulate data in Access, the more obvious the way you should store data in tables and fields becomes.
A primary goal of good database design is to make sure your data can be easily maintained. A database is great at managing additional records. However, it's terrible at managing additional fields (columns), because all its queries, forms, reports, and code are field-dependent.
Data normalization is a particularly difficult concept for spreadsheet experts. Having been a spreadsheet developer before using databases, I sympathize with those struggling to make the transition. The main reason you're using a database rather than a spreadsheet is probably because you have so much data you can't manage it properly in Excel. The fundamental advantage of a database is that it allows your data to grow without causing other problems. The big disaster in most spreadsheets is the need to add new columns or worksheets (for new years, products, etc.), which causes massive rewrites of formulas and macros that are difficult to debug and test thoroughly. Been there!
Designed properly, databases let your data grow over time, without affecting your queries or reports. You need to understand how to structure your data so your database takes advantage of this. How you store your data is totally different from how you show it. So stop creating fields for each month, quarter or year, and start storing dates as a field. You'll be glad you did.
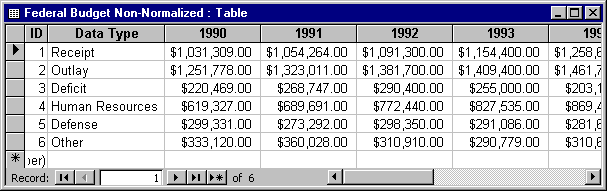
The tables shown in FIGURES 1 and 2 contain the same data, but in markedly different ways. Notice how the normalized table lets you easily add more records (years) without forcing a restructuring of the table. In the non-normalized table, adding next year's data would require adding a field. By avoiding the need to add a field when you get more data, you eliminate the need to update all the objects (queries, forms, reports, macros, and modules) that depend on the table. Basically, in databases, new records are "free," while new columns are "expensive." Try to structure your tables so you don't need to modify their fields over time.
FIGURE 1: Non-normalized "spreadsheet" data.
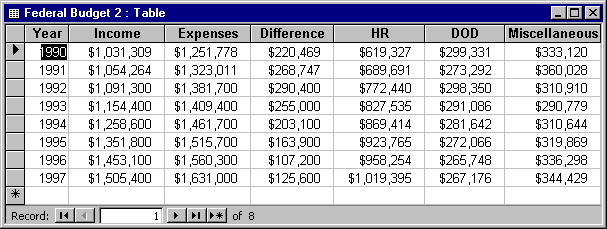
FIGURE 2: Normalized data.
Efficient Storage and Unique IDs
A fundamental principle of data normalization is that the same data should not be stored in multiple places. Information that changes over time, such as customer names and addresses, should be stored in one table, and other tables referencing that information should link to it.
Unique IDs (key fields) with no connection to the data are used to link between tables. For instance, customer information should be stored in a Customer table, with a Customer ID field identifying the record. Access 97 lets you use an AutoNumber field to automatically assign new ID numbers. It doesn't matter what the ID number is, or whether they are consecutive; the ID number has no purpose other than identifying the record and letting records in other tables link to that record.
I've seen databases where people use ID numbers that combine a few letters of the last name, first name, and number. That makes no sense, and creates a mess over time. The ID should simply be a number; if you want your data sorted in a particular order, use a secondary index.
It's important to not take data normalization to extremes in Access. Most people are familiar with separating Customers into their own table. If not, they quickly discover why they need to. But what about optional fields like telephone numbers: business phone, fax number, mobile phone, modem, home phone, home fax, etc.? Most customers won't have all those numbers, but you may want to store them for those that do. There are three approaches:
There are arguments for each alternative and, to some extent, it depends on how well you know your data. Data normalization purists and programs (such as Erwin from Logic Works; http://www.logicworks.com), often suggest separate tables. Obviously, option 3 is the most flexible, because it allows you to support an unlimited number and type of phones. If you cannot limit the number of alternatives, it's your only choice. However, if you can limit the types, choose option 1 in Access.
First, Access stores data in variable length records. One of the reasons for data normalization is to save disk space. Old file formats such as dBASE, FoxPro, and Paradox store data in fixed-length records, with each record taking the same space even if its fields are blank. The more fields, the larger the table. Not only is disk space cheap today, Access records only grow if data is contained in them. Therefore, this kind of data normalization is not necessary for efficient data storage in Access.
Second, and more important, the retrieval of data across multiple tables may be an unnecessary hassle. If you are always going to show the customer's phone and fax number, retrieving those records out of another table is unnecessary, and will hurt performance. The way Access is designed, it is much easier to simply pick the fields from the Customer table, rather than using a separate query or sub-report to grab each telephone type separately.
It's important to remember that there are situations where you must store what seems like duplicate data. This is most often related to the passage of time and the need to preserve what happened. The typical case is an order entry form, where you have an Invoice table linked to Customer and LineItem tables. Each record in the LineItem table is linked to a Product lookup table containing product descriptions and pricing. The LineItem table stores a ProductID to designate which product was purchased.
However, this is not sufficient; the LineItem table must also store the price and description at the time of the order. Over time, prices and descriptions in the Product table often change. If it's not preserved in the LineItem table, you will be unable to view or print the original invoice, which could be a disaster (you would actually show the current description and price). Therefore, during data entry, when a product is selected, you also need to retrieve the price and description to fill in those fields in the LineItem table. The customer information may also change, but that's good, because we want the latest customer address to appear.
Converting Non-normalized Data
In FIGURES 1 and 2, we show non-normalized and normalized tables. How do you get from one to the other? You could manually run queries, but that would be very cumbersome. A simple solution is to use Excel's Transpose feature. In Excel, highlight the data to transpose, copy it, then select Edit | Paste Special and select the Transpose option.
Within Access, the solution requires some code, as shown in FIGURE 3. In the TransposeData Sub procedure, we iterate through each year in the original table (Federal Budget Non-Normalized), and create a new record in the target table (Federal Budget). Because we know the column names are years, we use a For loop to step through each year to transpose. The fields in the target table correspond to the value in the original table's Data Type field. A more general procedure is included in the database that accompanies this article (see end of article for download details).
FIGURE 3: The TransposeData Sub procedure.
Sub TransposeData()
Const cstrInputTable = "Federal Budget Non-Normalized"
Const cstrOutputTable As String = "Federal Budget"
Dim dbs As Database
Dim rstInput As Recordset
Dim rstOutput As Recordset
Dim intYear As Integer
Set dbs = CurrentDb
Set rstInput = dbs.OpenRecordset(cstrInputTable)
Set rstOutput = dbs.OpenRecordset(cstrOutputTable)
If Not rstInput.EOF Then
' Create a record in the output table
' for each column in the Input table.
For intYear = 1990 To 1997
rstInput.MoveFirst
rstOutput.AddNew
rstOutput![Year] = intYear
' Go through every record in the Input table
Do
rstOutput(rstInput![Data Type]) = _
rstInput(CStr(intYear))
rstInput.MoveNext
Loop Until rstInput.EOF
rstOutput.Update
Next intYear
End If
rstInput.Close
rstOutput.Close
dbs.Close
End SubSeparating Application and Data Databases
Because Access stores all its objects in one .MDB file, it's important to separate your application and data into separate databases. This can be a hassle during development, because it makes it difficult to create and modify tables. Before you put your database into production, however, you need to separate the two, and have your application database link to the tables in the data database. The main reason is so you can update the application without wiping out the data (assuming your users are adding and editing data). It's also important if you're deploying a multi-user application. The application MDB should include all the queries, forms, reports, macros, and modules. It should also include any tables that are user-specific (tables to store user options, temporary tables, etc.).
Done properly, you can deliver a new version of your application, replace the existing ones, and use the current data. If structural changes are necessary with the tables, you will then need to manually modify the data database. The application database can be linked to the data database through the Linked Table Manager under the Access Tools | Add-Ins menu.
You can also write some module code to update a linked table, as shown in FIGURE 4.
FIGURE 4: The ReLinkTable_TSB Sub procedure (from Total Access SourceBook, copyright FMS Inc.).
Function ReLinkTable_TSB(strTable As String, _
strPath As String) As Boolean
' Comments : Re-links the named table to the named path.
' Parameters: strTable - Table name of the linked table.
' strPath - Full path name of the database
' containing the real table.
' Returns : True if successful, False otherwise.
Dim dbsTmp As Database
Dim tdfTmp As TableDef
Dim strPrefix As String
Dim strNewConnect As String
On Error GoTo PROC_ERR
Set dbsTmp = CurrentDb()
Set tdfTmp = dbsTmp.TableDefs(strTable)
strPrefix = Left$(tdfTmp.Connect, _
InStr(tdfTmp.Connect, "="))
strNewConnect = strPrefix & strPath
tdfTmp.Connect = strNewConnect
tdfTmp.RefreshLink
ReLinkTable_TSB = True
PROC_EXIT:
dbsTmp.Close
Exit Function
PROC_ERR:
ReLinkTable_TSB = False
Resume PROC_EXIT
End FunctionFor the most part, separating the data into a data database doesn't affect your application. The queries based on the linked tables remain the same, as do your forms, reports, and code. The main exception are Seek statements. Seek statements are used in code to find a record. They are very fast because they use an index you specify. For example, for a given table (strTable), index (strIndex), and search values (varValue1 and varValue2):
Dim dbs As Database
Dim rst As Recordset
Dim fFound As Boolean
Set dbs = CurrentDb
Set rst = dbs.OpenRecordset(strTable)
rst.Index = strIndex
rst.Seek "=", varValue1, varValue2
fFound = Not rst.NoMatch
However, this code fails if the table is linked. This is frustrating, and many developers resort to the FindFirst command instead. Unfortunately, FindFirst is very inefficient. It doesn't use an index, and performs a sequential search through the entire table — a search that can be painfully slow for large tables. The good news is that you can use Seek on linked tables. It's a matter of properly identifying the database where the table resides. Often, you will know the linked database name, and you can easily set the database variable (where strLinkedDB is the linked database name):
Set dbs = DBEngine.Workspaces(0).OpenDatabase(strLinkedDB)
The example in FIGURE 5 is a general solution where the code tests a table and changes the database variable if it is linked.
FIGURE 5: This code tests a table and changes the database variable if it is linked.
Dim dbs As Database
Dim tdf As TableDef
Dim strConnect As String
Dim strLinkedDB As String
Dim rst As Recordset
Dim fFound As Boolean
Set dbs = CurrentDb
Set tdf = dbs.TableDefs(strTable)
' Connect = "" if it's not a linked table.
strConnect = tdf.Connect
If strConnect <> "" Then
' Database name follows the "=" sign.
strLinkedDB = Right$(strConnect, _
Len(strConnect) - InStr(strConnect,"="))
' Change database handle to external database
dbs.Close
Set dbs = _
DBEngine.Workspaces(0).OpenDatabase(strLinkedDB)
End If
Set rst = dbs.OpenRecordset(strTable)
rst.Index = strIndex
rst.Seek "=", varValue1, varValue2
fFound = Not rst.NoMatchBy normalizing your data and splitting your database into separate application and data .MDB files, you'll go a long way toward establishing a solid foundation for your database development efforts. Data normalization not only makes your data more accurate, it makes it easier to analyze. More importantly, it makes it easier to maintain and expand. Separating your application and data databases enables you to support multiple users and upgrade the application, without affecting client data.
Download source code for this article here
Luke Chung is the president and founder of FMS, Inc., a database consulting firm and the leading developer of Microsoft Access add-in products. He is the designer and co-author of several Access add-ins, including Total Access Analyzer, Total Access CodeTools, Total Access Detective, Total Access SourceBook, and Total Access Statistics. He has spoken at a variety of conferences and user groups, and can be reached at LChung@fmsinc.com. The FMS Web site (http://www.fmsinc.com) offers a variety of Access resources, including technical papers, utilities, and demonstrations.