![]()
This article assumes you're familiar with Database basics
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Say UDA for All Your Data Access Needs Aaron Skonnard |
| UDA is the data-access portion of the Windows DNA initiative. It clarifies and streamlines the Microsoft data-access strategy by combining ADO, OLE DB, and ODBC. |
|
Today, developers building database solutions face many challenges as they seek to integrate the variety of data found across most enterprises. More than ever, integrated database solutions need to access data stored in both DBMS and non-DBMS information sources. DBMS sources used heavily in today's workplace include mainframe databases such as IMS and DB2, server databases such as Oracle and Microsoft® SQL Server™, and desktop databases such as Microsoft Access, Microsoft FoxPro®, and Paradox. Non-DBMS sources, on the other hand, could include information stored in file
systems (on multiple platforms),
indexed-sequential files, email, spreadsheets, project management tools, and any other type of data
used regularly.
Just the thought of having to interface with all of these data sources within a single database solution is overwhelming. If you've worked with any of these data sources in the past, you'll appreciate the challenge of becoming proficient with the tools and interface of even a single package. As data storage continues to evolve, you will be faced with new challenges from new data formats. What you really need is a simple yet universal data access strategy that is capable of interfacing with virtually any present or future data format.
Microsoft Universal Data Access
Windows DNA
Guiding Principles
|
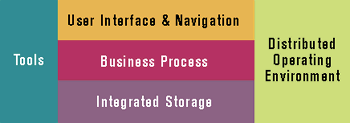
Figure 1 illustrates the Windows DNA architecture. As you can see, Windows DNA addresses requirements at all tiers including user interface, navigation, business rules, and integrated storage. However, the tier that I'm most interested in is data storage. UDA is the central component of the Windows DNA data storage strategy. In fact, UDA was designed to provide all data services to Windows DNA-driven applications, with a COM-based architecture that provides a unified model for accessing all types of data that fits perfectly into the Windows DNA architecture.
UDA Overview
UDA offers a number of benefits. First, UDA provides high performance by offering the ability to scale applications to support concurrent users without taking a performance hit. Second, UDA provides increased reliability by reducing the number of components that need support on the PC, which in turn reduces possible points of failure. Third, UDA has broad industry support from tool vendors, data access component developers, and DBMS vendors. These are the types of benefits that most customers are looking for in today's business solutions.
Figure 2 briefly describes the role of each MDAC component. MDAC 1.5, which can be downloaded from http://www.microsoft.com/data, was designed to achieve the
following goals:
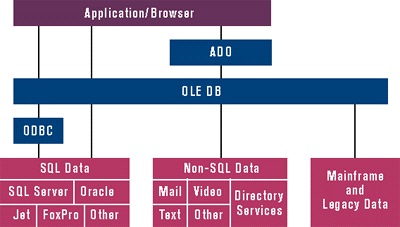
Figure 3 illustrates how each component fits into the overall UDA architecture. ADO is an application-level programming interface to data and information. ADO supports a variety of development needs including front-end database clients and middle-tier business objects using applications, tools, languages, or browsers. RDS, previously known as the Active Data Connector, is a client-side component that interfaces with ADO and provides several important features such as providing cursors, remote object invocation, explicit recordset remoting, and implicit remote recordset functionality such as fetch and update. OLE DB provides the low-level interface to data across the enterprise. While ADO
interfaces with OLE DB behind the scenes, applications can still access OLE DB directly. And finally, you have the ODBC components that have become the standard for working
with relational data. While the emphasis in UDA is on
OLE DB native providers, ODBC is still a backwards-
compatible solution.
Let's look at a few scenarios that show how a user would employ this model to query data. First, let's suppose the data resides in a relational database for which there is an ODBC driver but no OLE DB provider. According to Figure 3, the application has a few options. The application can talk directly to ODBC to query the data, at the price of coding to the lower level. It can also use ADO to talk to the OLE DB provider for ODBC, which would in turn load the appropriate ODBC driver. If the data resides in a data source for which there is an OLE DB provider, the application uses ADO to talk directly to the OLE DB provider.
Next, let's assume that the data resides in Microsoft Exchange Server, for which there is an OLE DB-based interface. This OLE DB provider would not process SQL queries since it doesn't contain SQL data. The application instead would use ADO to talk with the data provider and use the OLE DB query processor component to handle querying.
Finally, let's assume that the data resides in the Windows NT® file system. In this case, the data is accessed with a native OLE DB provider working on top of Microsoft Index Server, which indexes the contents and properties of documents in the file system.
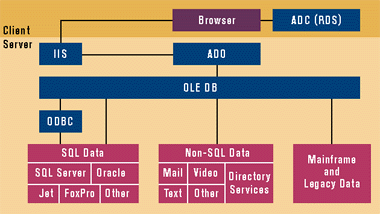
Figure 4 illustrates the role of RDS. As I mentioned previously, RDS is responsible for client-side services such as caching and updating data and binding data to controls. RDS controls use ADO as their data source, then the cursor engine in RDS talks OLE DB with ADO. RDS is a valuable component of the UDA architecture because it is responsible for improving client-side performance and flexibility in the Windows DNA environment.
These examples illustrate how UDA makes it possible to access different types of data (relational and nonrelational) using a very similar approach. UDA is able to achieve this with a minimum number of components. If an additional component is
required (like the OLE DB query
processor component), it's loaded
when needed. This component-based COM model contributes to UDA's
high performance.
OLE DB
OLE DB is the foundation of the UDA architecture. It's a specification for a set of COM-based data access interfaces that encapsulate various data management services. These interfaces define how a multitude of data sources can interact seamlessly. To become an OLE DB provider, you simply implement OLE DB components from the well-defined OLE DB interfaces for the level of OLE DB support you want. This component-based model allows you to work with data sources in a unified manner and allows for future extensibility.
OLE DB components can be broken down into three categories: data providers, data consumers, and service components. The key characteristic of a data provider is that it owns the data it exposes to the outside world. While each provider handles implementation details independently, all providers expose their data in a tabular format through virtual tables. A data consumer is any component—whether it be system or application code—that needs to access data from OLE DB providers. Development tools, programming languages, and many sophisticated applications fit into this category. Finally, a service component is a logical object that encapsulates a piece of DBMS functionality. One of OLE DB's design goals was to implement service components (such as query processors, cursor engines, or transaction managers) as standalone products that can be plugged in when needed. Figure 5 illustrates some of the OLE DB interfaces.
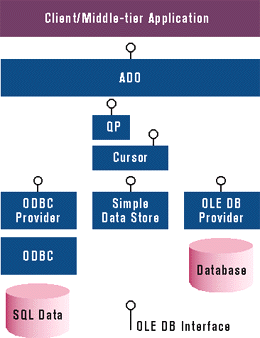
The OLE DB object model consists of seven core components, as described in Figure 6. Figure 7 illustrates how these components interact. The data source object is the first object returned by an enumerator and contains the necessary machinery to connect to the underlying data source. You can instantiate a Data Source object by calling CoCreateInstance with a specific OLE DB provider's globally unique class ID (CLSID). The Data Source object is like the interface of an ODBC data source and should be conceptually familiar to most ODBC developers. It defines context, authentication, and data
provider properties.
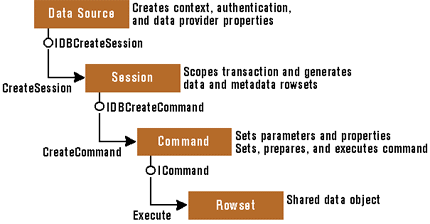
The Session object controls the scope of transactions and is responsible for generating data and metadata rowsets from the underlying data source. Multiple sessions can be associated with a single Data Source object. If the OLE DB provider supports commands, the Session object also acts as a class factory for Command objects (class factories are responsible for generating COM objects upon request). Like the Data Source object, the Session object also encapsulates the ODBC connection functionality.
If the OLE DB provider supports queries, it must also expose a Command object. There can be multiple Command objects associated with a single Session object. The Command object, generated by the Session object, is responsible for specifying, preparing, and executing text commands (queries) represented in the data definition language or the data markup language. Command objects encapsulate the functionality of an ODBC statement in an unexecuted state. The following steps show how you can accomplish this:
OLE DB Provider Minimum Requirements
Obviously, all data providers are going to have different functionality specific to their data source. In fact, it would be impossible for all data providers to expose the same level and range of functionality. At the same time, you should be able to expect a basic level of functionality from all data providers. This minimum level of functionality is at the heart of the OLE DB design and allows you to work with multiple data sources transparently. OLE DB requires that all data providers support the objects and interfaces described in Figure 8.
OLE DB in Action
To help put this new concept in perspective, let's look at an example of how a typical application can take advantage of OLE DB. (Note that Microsoft encourages MDAC users to adopt ADO as the consumer interface, not OLE DB.) Using OLE DB for any purpose can be broken down into the following five general steps:
IDBInitialize** ppIDBInitialize
// Create an instance of the ODBC provider (MSDASQL)
CoCreateInstance(CLSID_MSDASQL, NULL, CLSCTX_INPROC_SERVER, IID_IDBInitialize,
(void**)ppIDBInitialize);
pIDBInitialize->Release();
CoUninitialize();
ADO in Action
If you're familiar with data access technologies such as Data Access Objects (DAO) and Remote Data Objects (RDO), you will recognize the interfaces supported by ADO. In fact, ADO makes huge improvements to these existing models by fixing or removing awkward tasks and beefing up performance. The main goal of ADO is to make it easier to do anything that the underlying data provider can do. Since ADO uses OLE DB, you'll notice many similarities between the objects, interfaces, and overall functionality of both technologies. ADO also hides many incompatibilities between various OLE DB providers and makes up for missing functionality in some providers.
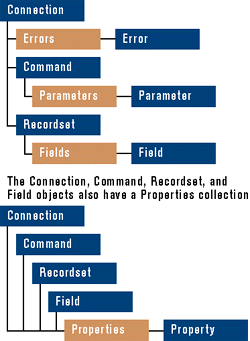
First, let's take a look at the ADO programming model as illustrated in Figure 10. All objects represented in Figure 10 can be created independently except for the Error and Field objects. The hierarchy that you're probably used to from previous models has purposely been deemphasized in the ADO model. This gives you much more flexibility to reuse objects across context boundaries. For example, in ADO you can create a single Command object and use it with more than one Connection object. To help you better understand ADO, let's cover each ADO object in more detail.
The Connection interface represents a connection to the underlying data source (refer to the Data Source object in the OLE DB model). The Connection interface exposes an Execute method for executing data source-related commands on the connection. If the command generates rows, a default Recordset object will be returned. However, if you need to use a more specialized or complex Recordset object with data returned from the Connection, you should create the new Recordset object (specifying the way you need it to behave), bind it to the Connection, and open the cursor.
The Command object in ADO is equivalent to the Command object in OLE DB. This object is optional in ADO since some providers don't even provide command execution. Nevertheless, if the provider supports it, so does ADO. The basic purpose of the Command object is to execute queries, provider-specific statements, or even stored procedures. Like the Connection object, the Command object supports an Execute method. The Command object can also be associated with a Recordset object when opening the cursor. Another interesting feature of the Command object is the use of a Parameter object collection to hold command-specific parameters.
The Parameter interface represents a parameter of a command. You can explicitly create Parameter objects and add them to the parameter collection to avoid the expensive task of going to the system catalog to populate the parameter binding information automatically.
All of the cursor information is contained in the Recordset interface, so the Recordset interface is by far the most complex. With a few exceptions, the Recordset object is very much the same as those used in today's data access models. Improvements to the Recordset object include the addition of optional arguments that reduce the number of lines of code for common scenarios, changing obsolete defaults for certain parameters, and cleaning up functionality that's repeated elsewhere.
The Field interface simply represents a column in a recordset that you can
use to obtain and modify values as well as learn more
about column metadata. This interface is almost identical to past models.
The Error interface represents an Error object returned from a data source. This interface is optional, however, and is only useful when the underlying data provider can return multiple errors. If the data provider is unable to return multiple errors for a single function call, the provider will use the normal COM error mechanism.
Figure 11 illustrates how you can use ADO in a Visual Basic-based application. The example shows how to open a connection, open a recordset, modify recordset properties, add a new record to the database (through the Recordset.AddNew method), and close both the Recordset and Connection objects. The example assumes that there is a SQL Server data source named Pubs and a table named Employee, both of which are standard SQL Server samples. I've provided a similar example written in VBScript (see Figure 12) that can be used within an ASP file. This second example assumes that you have a system data source called AdvWorks and a table named Customers.
Remote Data Service
As I mentioned earlier, one of the main goals of the UDA components was to integrate remoting capabilities, which consisted primarily of merging the ADO functionality with the Active Data Connector functionality. The Active Data Connector has become RDS, a service of ADO.
RDS provides remote (client-side) and middle-tier caching of ADO Recordset objects and improves overall performance by minimizing the number of network roundtrips. RDS achieves this by retrieving large resultsets (recordsets) as a binary feed. To simplify programming, RDS also provides a simple mechanism for binding Recordset objects to the data-bound controls found on a Web page. For applications that need to browse records or connect to live data,
consider using RDS because of these simple performance-boosting features.
While RDS greatly improves client-side data access, it lacks the flexibility of ADO, and it's not meant to be a replacement or substitute for it. ADO allows you to specify the type of Recordset object you want to create, while RDS handles this for you behind the scenes. Furthermore, ADO allows you to maintain database connections while RDS always works with disconnected data. Therefore, if your application requires a high degree of data access functionality, ADO is probably a better choice than RDS. Nevertheless, because of the flexible UDA architecture, you can choose to use ADO, RDS, or both as part of your complete data access solution.
How RDS Works
Let's take a look at how RDS works in a Web-based application. Figure 13 illustrates how a Web browser would use RDS to view data stored in a server-side database. The RDS components are hosted by an ActiveX-enabled Web browser such as Internet Explorer 4.0 and use the HTTP protocol to communicate with the Web server. (Since Internet Explorer 4.0 includes RDS, applications that standardize on Internet Explorer 4.0 will have less to worry about at deployment time.)
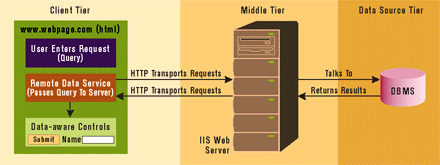
When the user makes a request, the client-side RDS component sends a request to the Web server, which then processes the request and sends it on to the underlying data source. After the data source processes the request, it will send the result back to the Web server, which transforms it into ADO Recordset objects. The Recordset objects are transported back across the Internet to the RDS component that initiated the request. Once the RDS component receives the response, the data is displayed in the data-aware controls bound to the RDS component. At this point, the data is cached locally. Further trips to the server are required only for additional data requests or updates.
RDS Objects
There are three RDS objects: RDS.DataControl, RDS.DataSpace, and RDS.DataFactory. The RDS.DataControl object is responsible for actually binding data-aware controls to ADO Recordset objects. In fact, one RDS.DataControl is capable of channeling data to many data-aware controls. The RDS.DataSpace object creates client-side proxies to custom business objects located on the middle tier. The RDS.DataFactory is the default server-side business object that implements methods that provide read/write data access to specified data sources for client-side applications.
Figure 14 shows how to use the RDS.DataControl object in an HTML page. While this example sets the parameters at design time, it's also possible to let the user specify them at runtime. This example binds the RDS.DataControl to the Sheridan Grid control and uses the ODBC data source called ADCDemo.
When this Web page is requested and loaded, the Sheridan Grid control will be bound to the ADCDemo data source automatically and will display the rows returned by the query specified in the SQL parameter ("Select * from Employee for browse"). The user can browse the data found in the Sheridan Grid control without requiring additional network traffic.
ODBC
One interesting thing to note from Figure 3 is that OLE DB is capable of accessing relational databases through existing ODBC drivers. It achieves this through an OLE DB provider for ODBC, which happened to be the very first OLE DB provider that Microsoft developed. Microsoft did this for a reason. Since ODBC was already a standard, they wanted to make sure developers could continue using it under the new UDA architecture. For now, the Microsoft plan is to work with primarily non-SQL database vendors to support the OLE DB interfaces and extend existing ODBC technologies (through native OLE DB providers) for relational databases.
ODBC Versus OLE DB
OLE DB is being positioned as the successor to ODBC. In fact, if you need to access relational SQL databases, OLE DB native providers will be the eventual solution in UDA. ODBC still fits the bill if there's no OLE DB provider available for a data source. If you want to expose a data interface to non-SQL data or you're programming in an OLE environment, OLE DB is a better choice. Furthermore, if you want to build interoperable database components, OLE DB is the only possible solution. Nevertheless, the role of ODBC in UDA is still a valuable one.
There are several differences between ODBC and OLE DB. Using a pure OLE DB provider for relational SQL data provides much better performance than ODBC. The problem lies in the often costly and time-consuming transition. Microsoft wanted to keep ODBC part of the UDA architecture to give customers the ability to continue using ODBC and allow them to decide when to take advantage of the new OLE DB providers as they become available.
So why should you use the OLE DB ODBC provider instead of just using straight ODBC? If you employ the OLE DB ODBC provider, you'll be able to take advantage of some new OLE DB features that aren't available in ODBC. For example, a new interface that is exposed through OLE DB knows how to interface with the ODBC driver even though the ODBC driver doesn't expose the same functionality. With this approach, both existing and new applications are capable of gaining the additional data access features provided by OLE DB while still using the native ODBC drivers.
While Microsoft has included ODBC in the overall UDA architecture, using pure OLE DB drivers for even relational SQL data is a more certain long-term strategy. As more and more OLE DB providers are developed and released, ODBC will probably be replaced by OLE DB's more integrated solution. For the short term, however, ODBC provides a proven interface to relational data.
Conclusion
Hopefully the concepts of UDA and the smörgasbord of UDA components are starting to make some sense. For
complete and up-to-date information on UDA, visit Microsoft's Universal Data Access Web site at http://www.microsoft.com/data. For more detailed product and technical information, refer to the UDA whitepaper and other technical notes found on the Web site. Also, ADO, RDS, OLE DB, and ODBC have their own reference materials available for download.
In the months ahead, Microsoft will be releasing a new Data Access SDK containing a complete set of tools and samples to assist in developing UDA-based solutions. The Data Access SDK will contain MDAC 2.0 along with tools for using and testing data access components. The Data Access SDK will be the official source of information on UDA development for both data consumers and data providers.
Microsoft and data vendors are committed to UDA as part of the overall Windows DNA architecture. While COM-based distributed architectures are taking hold of today's computing environment, the need to marry the Web with the
flexibility and control of today's PC applications is
continuing to grow. As Microsoft's evolutionary Windows DNA architecture becomes the industry standard, UDA's role will become crucial to the continual progress of your
software solutions.
I would like to give special thanks to David Lazar who authored the "Microsoft Strategy For Universal Data Access" whitepaper. Much of the material presented here is based on his whitepaper and the plethora of information found on the Microsoft UDA Web site.

From the April 1998 issue of Microsoft Interactive Developer.