Although it might be heretical to say so in these days of object-oriented fervor, there are situations in typical data processing applications where a fully populated object model introduces unnecessary overhead that can severely degrade the performance of the application. In this article, R.L Parker demonstrates a technique called "just-in-time instantiation" that allows the data to be treated in far more efficient two-dimensional arrays, while still retaining the benefits of a good object-oriented design.
Ever since the release of Visual Basic 4.0 with its support for classes, a veritable army of VB programmers has learned the techniques of object-oriented development and has largely become convinced of its benefits. I won't review those techniques or benefits in this article -- to do so adequately would require a book, and good ones such as Deborah Kurata's Doing Objects in Microsoft Visual Basic 5.0 already exist.
But perhaps the pendulum has swung too far. Applications are being developed and deployed that use objects too much for their own good. Is such a thing possible? I think so, because objects have their own overhead; if an application uses too many of them, or uses them in inappropriate situations, its performance might suffer.
The problemLet's assume that we're developing an application for a mail order company that sells music CDs, and that we're working on a subsystem that will be used by the customer service department clerks to answer questions about existing orders. During the analysis phase, we determined that the application must support these requirements (among others):
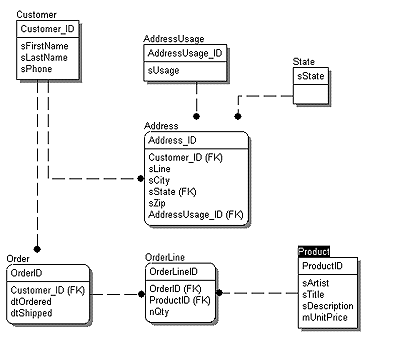
A logical model and user interface that will support these requirements are shown in Figure 1 and Figure 2.
Figure 1: A logical model that supports the storage and retrieval of customer and order information
Figure 2: A Rudimentary user interface design that supports the display of customer and order information
An object-oriented solutionAs object-oriented programmers, we'd look at the requirements and the logical model and decide that the following classes are needed in our application:
Also, our business layer functionality should be contained in a class called clsBusinessLayer. This class has two jobs: to encapsulate any business rules that must be executed when data is retrieved, inserted, or updated, and to act as the go-between for application layer and the data layer. This separation of functionality is often called three-tier or n-tier architecture.
As a first cut (see BL1.WRI and CUST1.WRI in the accompanying Download file), we decide that our business layer object needs to provide a method called GetCustomers on its interface. When GetCustomers is called, it returns a collection of fully populated Customer objects. By "fully populated," I mean that all the objects -- including each Customer and the Customer's address(es) and order(s) -- have been initialized from the data source. The appeal of this approach is that all the front end has to do is call this single method, then simply sit back and navigate through the object model as the customer service clerk moves around through the application.
In a perfect world, this design might be ideal. But during testing, it turns out that our application's performance makes molasses look zippy. Why? Because objects and, especially, collections of objects have a high runtime cost (see the sidebar "Rolling My Own Benchmark").
Okay, let's refine our design. We could change GetCustomers() so that instead of returning the fully populated object model, it returns only the top level of the model -- the Customers collection. Then, we'd wait and get the Addresses and Orders collections only for each specific Customer when selected. This makes a noticeable improvement; are we out of the woods?
Another solutionThere are situations where neither of these approaches will provide acceptable performance. First of all, we might decide to put the business layer object in an OLE server executable. Why would we want to do that? Two reasons are usually cited: so the business rules object can run on a powerful "application server" machine, and so the business rules can be modified without re-distributing applications all the way to the desktop. If the business layer is put in a separate EXE, it will run out-of-process, and we'll find that it isn't a good idea to return objects or collections of objects from the methods of our business layer. Because of cross-process marshaling, performance suffers terribly.
Instead, the data needs to be returned from our business layer as a Variant variable, which holds two-dimensional arrays. Variant variables can be marshaled relatively efficiently. (See BL2.WRI in the accompanying Download file.)
You'll notice that several changes have been made to clsBusinessLayer. First, the return type of GetCustomers() has been changed from "Collection" to "Variant". Instead of being packaged into a fully populated object model, the raw data is returned to the application layer in a two-dimensional array (in a Variant variable). This 2-D array has a row and column for each corresponding row and column in the result set that's obtained from the data layer.
The client-side code (see Listing 1) must manage this 2-D array. Especially, it must be able to find whatever it needs in this raw data. This is where our classes come back into the picture. We don't have to -- indeed we shouldn't -- discard our class design. We mainly discard the collections because of their inefficiency. And we can add a couple of methods to the remaining application classes that help the application find what it needs in the raw data.
Listing 1. The modified version of clsCustomer (see CUST2.WRI in the accompanying Download file).
Option Explicit
Private mlCustomerID As Long 'the primary key
Private msFirstName As String
Private msLastName As String
Private msPhone As String
'these constants define the order of the columns found
'in the raw data
Private Const cColID = 1
Private Const cColFirstName = 2
Private Const cColLastName = 3
Private Const cColPhone = 4
Private Const cColLastCol = 4
Public Property Get CustomerID() As Long
CustomerID = mlCustomerID
End Property
Public Property Let CustomerID(lID As Long)
mlCustomerID = lID
End Property
Public Property Get FirstName() As String
FirstName = msFirstName
End Property
Public Property Let FirstName(sName As String)
msFirstName = sName
End Property
Public Property Get LastName() As String
LastName = msLastName
End Property
Public Property Let LastName(sName As String)
msLastName = sName
End Property
Public Property Get Phone() As String
Phone = msPhone
End Property
Public Property Let Phone(sPhone As String)
msPhone = sPhone
End Property
Public Sub InitFromRow(aData As Variant, lRow As Long)
'initialize an instance of this class by
'extracting a row (specified by lRow) from the
'raw data (a 2-dimensional array in aData)
If IsArray(aData) Then
If (lRow >= LBound(aData, 2)) And (lRow <= _
UBound(aData, 2)) Then
mlCustomerID = aData(cColID, lRow)
msFirstName = aData(cColFirstName, lRow)
msLastName = aData(cColLastName, lRow)
msPhone = aData(cColPhone, lRow)
End If
End If
End Sub
Public Function SaveAsRow() As Variant
'return a 1-d array image of the object
'in the same column order defined in InitFromRow
Dim aRow As Variant
ReDim aRow(1 To cColLastCol)
aRow(cColID) = mlCustomerID
aRow(cColFirstName) = msFirstName
aRow(cColLastName) = msLastName
aRow(cColPhone) = msPhone
SaveAsRow = aRow
End FunctionYou'll notice that, like clsCustomer, each application class has two new methods -- InitFromArray and SaveAsRow. These methods are used to move data from and to, respectively, a two-dimensional array to a class instance. As we loop through our ersatz collection, now represented by the two-dimensional array, we can use InitFromArray to "reconstitute" an object from a row in the two-dimensional array. I call this "just-in-time" instantiation because, instead of a collection of object instances, we only have one object instance. The data is put into this object instance (via the call to InitFromArray) just in time for us to use its properties and methods; then the object is re-used to represent the next row in the result set.
In our sample customer service application, we turn a row into an object so that the data can be displayed in detail panels. The following code fragment from the application layer (frmCustomerService.DisplayDetail) shows how we use InitFromRow and then use the reconstituted object's properties to display the details for an order line object:
Private Sub DisplayDetail()
Dim oOrderLine As clsOrderLine
...
Set oOrderLine = New clsOrderLine
oOrderLine.InitFromRow maOrderLines, mlDetailIndex
'reconstitute the object from a row in the raw data
txt(cTxtDetailID) = oOrderLine.OrderLineID
txt(cTxtArtist) = oOrderLine.Artist
txt(cTxtTitle) = oOrderLine.Title
txt(cTxtDesc) = oOrderLine.Description
txt(cTxtPrice) = oOrderLine.UnitPrice
txt(cTxtQty) = oOrderLine.Qty
...
End SubThen, when the user navigates to the next row of data, we reconstitute that row into our object instance so that it can be displayed. Because our sample application is read-only, there's no need to store any changes back into the 2-D array result set. But if we did, we could use the SaveAsRow method that we've added to each class.
The sample code in the accompanying Download file is in VB4, but if you were to implement this application in VB5, you might consider creating an "abstract base class" that has InitFromArray and SaveAsRow in its interface. Then, all appropriate application classes could implement that interface -- that way, you'd be guaranteed that InitFromArray and SaveAsRow are available in all necessary classes.
Obviously, this technique requires more coding and maintenance on the client side. This is a trade-off that you must evaluate using your professional judgment. If you decide to use just-in-time instantiation, you'll almost certainly need to declare constants (probably maintained by the programmer responsible for the data layer) that define the column order for each "get" method in the data layer and business layer interfaces. The application class programmer will use these constants to implement InitFromRow and SaveAsRow. For example, here's the relevant code showing how to implement InitFromRow from clsOrderLine:
'these constants define the order of the columns found
'in the raw data
Private Const cColID = 1
Private Const cColFirstName = 2
Private Const cColLastName = 3
Private Const cColPhone = 4
Private Const cColLastCol = 4
...
Public Sub InitFromRow(aData As Variant, lRow As Long)
'initialize an instance of this class by
'extracting a row (specified by lRow) from the
'raw data (a 2-dimensional array in aData)
If IsArray(aData) Then
If (lRow >= LBound(aData, 2)) And (lRow <= _
UBound(aData, 2)) Then
mlCustomerID = aData(cColID, lRow)
msFirstName = aData(cColFirstName, lRow)
msLastName = aData(cColLastName, lRow)
msPhone = aData(cColPhone, lRow)
End If
End If
End SubPerformance considerations must be taken into account early in the design process. Depending on the application requirements, deployment strategy, and object model complexity, business layer methods might need to return variants that contain raw data in 2-D arrays rather than returning collections of objects. If so, a technique by which objects can be "reconstituted" from a row in the raw data is necessary.
This technique isn't intended to replace good object-oriented design methodology. Rather, it's a compromise implementation made necessary in the interest of performance. It should be used after -- not instead of -- the object-oriented design.
R. L. Parker is a Microsoft Certified Solution Developer and senior technical lead at DBBasics, Inc. in Raleigh, NC, who specializes in custom development of mission-critical database applications. rlp@dbbasics.com.
Sidebar: Rolling My Own BenchmarkWhen I started to write the accompanying article ("Just-in-Time Instantiation"), I knew that large, fully populated object models cause performance problems. But how large is "large," and when exactly do the performance problems occur?
To find out, I wrote two different benchmark programs. The first one simply adds n instances of a simple object to a collection, and then deallocates the collection. Table 1 and Table 2 show the results. I was surprised to learn that there's a bigger performance problem with deallocating the collection than with creating the instances and adding them to the collection in the first place. You'll see that allocation time increases linearly with respect to n. But deallocation time increases at an increasing rate when n gets large.
Table 1. The initial Collection_Perf benchmark using a 133 MHz Pentium with 32M RAM running VB4 under Win95.
| n | allocate (ms) | deallocate (ms) |
| 100 | 21 | 18 |
| 200 | 41 | 28 |
| 400 | 83 | 81 |
| 800 | 164 | 206 |
| 1600 | 419 | 599 |
| 3200 | 798 | 1899 |
| 6400 | 1604 | 7032 |
| 12800 | 3134 | 30158 |
| 25600 | 7354 | 133067 |
The same code run on a machine with a lot more horsepower, but running under NT 4.0 Workstation instead of Windows 95, shows similar behavior, except that the definition of "large" increases.
Table 2. The initial Collection_Perf benchmark using a 200 MHz Pentium with 64M RAM running VB4 under NT4 Workstation.
| n | allocate (ms) | deallocate (ms) |
| 100 | 20 | 0 |
| 200 | 40 | 10 |
| 400 | 80 | 30 |
| 800 | 190 | 90 |
| 1600 | 380 | 291 |
| 3200 | 972 | 1071 |
| 6400 | 2423 | 4507 |
| 12800 | 7371 | 17245 |
| 25600 | 26017 | 80666 |
The second benchmark (see Listing 1a) might be more representative of real-life object models with a parent class that owns several collections.
Listing 1a. A parent class that owns several collections.
Option Explicit
Public ClassName As String
Public RedChildren As Collection 'of clsRed instances
Public OrangeChildren As Collection 'of clsOrange insts
Public YellowChildren As Collection 'of clsYellow insts
Public GreenChildren As Collection 'of clsGreen insts
Public BlueChildren As Collection 'of clsBlue insts
Public IndigoChildren As Collection 'of clsIndigo insts
Public VioletChildren As Collection 'of clsViolet insts
Private Sub Class_Initialize()
ClassName = "clsParent"
Set RedChildren = New Collection
Set OrangeChildren = New Collection
Set YellowChildren = New Collection
Set GreenChildren = New Collection
Set BlueChildren = New Collection
Set IndigoChildren = New Collection
Set VioletChildren = New Collection
End Sub
Private Sub Class_Terminate()
Set RedChildren = Nothing
Set OrangeChildren = Nothing
Set YellowChildren = Nothing
Set GreenChildren = Nothing
Set BlueChildren = Nothing
Set IndigoChildren = Nothing
Set VioletChildren = Nothing
End Sub
Public Sub AddChildren(lNumber As Long)
Dim lLoop As Long
Dim oRed As clsRed
Dim oOrange As clsOrange
Dim oYellow As clsYellow
Dim oGreen As clsGreen
Dim oBlue As clsBlue
Dim oIndigo As clsIndigo
Dim oViolet As clsViolet
For lLoop = 0 To lNumber - 1
Set oRed = New clsRed
RedChildren.Add oRed
Set oOrange = New clsOrange
OrangeChildren.Add oOrange
Set oYellow = New clsYellow
YellowChildren.Add oYellow
Set oGreen = New clsGreen
GreenChildren.Add oGreen
Set oBlue = New clsBlue
BlueChildren.Add oBlue
Set oIndigo = New clsIndigo
IndigoChildren.Add oIndigo
Set oViolet = New clsViolet
VioletChildren.Add oViolet
Next
End SubYou can see from the numbers in Table 3 that performance for a relatively large object model degrades very rapidly as n increases. In applications with large object models, especially if those models are repeatedly allocated and deallocated, a technique such as "just-in-time" instantiation might be necessary to achieve acceptable performance.
Table 3. The Collection_Perb benchmark using a 200 MHz Pentium with 64M RAM running VB4 under Windows NT 4 Workstation.
| n | allocate (ms) | deallocate (ms) |
| 10 | 110 | 20 |
| 20 | 421 | 160 |
| 40 | 2093 | 1993 |
| 80 | 11386 | 34189 |
| 160 | 107875 | 652959 |