![]()
This article assumes you're familiar with Active Server Pages, ADO 1.5 and
SQL Server 6.5.
Download the code (6KB)
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Top Ten Tips: Accessing SQL Through ADO and ASP J. D. Meier |
| Using SQL and ADO to provide data for your Web application can seem daunting, but these ten tips can noticeably improve your results. |
|
Retrieving data from a SQL Server™ database using ActiveX® Data Objects (ADO) and Active Server Pages (ASP) challenges many Web developers. It can be hard to maximize performance, scalability, and robustness in a specific installation. This article offers specific recommendations to help improve your data access. While much of this information can apply to other databases, I'll focus on SQL Server and use the familiar Pubs sample database for illustration purposes.
Tip 1: Use Stored Procedures for Performance
|
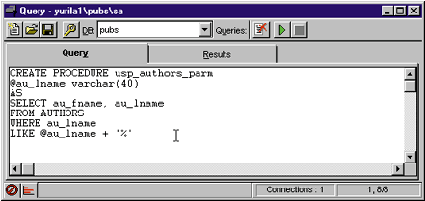 |
| Figure 3: ISQL |
|
It is always a good idea to test your stored procedure directly from ISQL before implementing it from ASP. To do this, ISQL allows you to make a direct call to it by entering the call just below the stored procedure text in the Query window (see Figure 4). You can then select the string to execute (in this case, it's "usp_authors_parm ‘m'"), and click the green arrow to run it. If you don't highlight the statement before clicking the arrow, ISQL will recreate the stored procedure. This operation would fail because the stored procedure already exists at this point. |
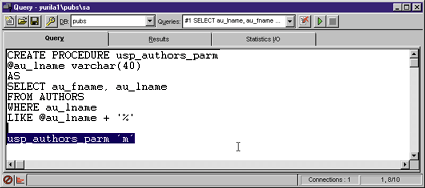 |
| Figure 4: Testing a Stored Procedure |
|
Once you're able to retrieve the correct results through ISQL, you can write the necessary ASP code to call the stored procedure. While there are various methods for calling stored procedures, for the sake of simplicity I will use the Execute method of the ADO Connection object. The ASP page CallStoredProc.asp (see Figure 5) calls the usp_authors stored procedure, passing the argument M. This is one way to call a stored procedure. In Tip 2 I'll show you a more elegant approach that provides more control over the stored procedure's execution while minimizing network activity.
Tip 2: Explicitly Create Your Parameters
Tip 3: Avoid Blobs
|
|
| retrieve your records using the following SELECT statement: |
|
|
There is another point to be aware of concerning presentation. If you will be retrieving images from your database through ASP, you will need to manipulate the HTTP header information. If you were to retrieve a GIF image from the database, you'd need to first clear out any existing HTTP header information, then set the ContentType to Image/Gif. See the article "Delivering Web Images from SQL Server," by Scott Stanfield (MIND, July 1998), for a complete discussion of how to do this effectively. To put additional text on the returned page, you need to create a separate page to host the image. Figure 8, RetrieveImage.asp, demonstrates how you can retrieve an image from Pubs. Notice how this page doesn't write any text with the Response object. Since I would like to provide some text with the image, I created an additional page, ShowImage.asp (see Figure 9). Another page is necessary because once you have set Response.ContentType to Image/Gif, you cannot write text to the ASP page. ShowImage.asp actually displays the image by referring to the RetrieveImage.asp in the IMAGE tag's SRC argument. |
 |
| Figure 10: ShowImage Output |
|
This two-page trick comes in handy for operations such as providing dynamic banners while minimizing work for your server. Simply create a static HTML page, then reference the ASP page through your IMG tag. The ASP page would be responsible for choosing which banner to display. Figure 10 shows the output of ShowImage.asp.
Tip 4: Pick the Right Cursor for the Job
|
|
|
This would produce the output seen in Figure 12. Figure 13 charts recordset properties by cursor type, while Figure 14 lists the recordset methods available by cursor type. |
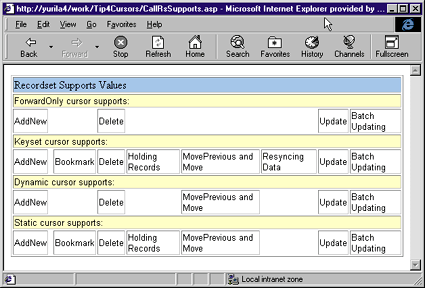 |
| Figure 12: Testing Recordsets |
|
Tip 5: Pool Your Connections Wisely
Tip 6: Avoid Putting ADO Objects in Sessions
Tip 7: Create Useful Indexes
|
|
|
You can then add a CLUSTERED index to your table based on another column that may be more effective. In this case, I chose to create a CLUSTERED index on the hiredate column because the application will frequently retrieve employees sorted by their hire dates: |
|
|
When you're determining which columns to include for indexes, consider how you will use the data. If you will be performing queries involving WHERE clauses, consider each column in the clause as a candidate for an index. Also, remember that column order is important when defining an index. As in the case of a composite key (a key composed of more than one column), you need to make the most distinguishing column the leftmost part of the index. Suppose you have a composite key made up of the au_fname and au_lname columns within a table. In the Pubs database, these columns in the authors table represent an author's first name and last name. For the index to be useful to a query such as "WHERE au_lname = ‘Gringlesby'" or "WHERE au_lname = ‘Gringlesby' AND WHERE au_fname = ‘Burt'", the au_lname column must be on the left of the index. However, this column order would not be useful for a query such as "WHERE au_fname = ‘John'". You would need to create an additional query on just the au_fname column. Consider indexing columns used for joins. This is particularly important because, while an index is created for you automatically when you create a PRIMARY KEY constraint, the index is not created automatically when in a FOREIGN KEY constraint. A few additional guidelines apply when designing your indexes. First, keep your indexes narrow. In other words, try to avoid multicolumn, compound indexes. Instead, create a larger number of narrow indexes. This provides the optimizer with more possibilities to choose from. Keep in mind that creating a large number of indexes will not guarantee the best performance. The query optimizer usually uses only one index per table per query—the rest are overhead. Be sure to continually evaluate the purpose and usefulness of your indexes. The most important thing to remember about choosing indexes is that empirical testing will be your best guide. Experimenting with indexes is cheap and the rewards are great. During development, create numerous indexes and test their performance. Keep the best and drop the rest; unused indexes create unnecessary overhead. On a side note, it is recommended that every table contain a primary key. That is not only good design; some ADO operations actually require that the underlying table has a primary key defined.
Tip 8: Optimize Your Queries
|
|
|
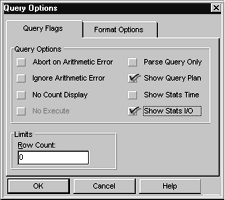
You can then bring up Query Options by pressing the button with the picture of a wrench on the ISQL toolbar (see Figure 16). Once you have brought up the Query Options window, choose Show Query Plan and Show Stats I/O as shown in Figure 17. Once you set these options, run the query. The output will show the results of your SQL statement, along with performance information (see Figure 18). |
 |
| Figure 16: Accessing Query Options |
Show Stats I/O allows you to examine the I/O consumed by the query. Note the count of logical page I/Os. The optimizer's goal is to minimize I/O count. Make a record of the logical I/O count and experiment with different queries and indexes to improve performance. Place more emphasis on Show Stats I/O when analyzing your query performance. It may take more time to become familiar with the output, but it may well be the most definitive tool for gauging your query's performance.
Tip 9: Isolate Your Errors
|
 |
| Figure 19: SQL Trace |
|
Once you have named your filter, click Add to apply it. This will cause SQL activity to be logged to the screen for further analysis. Figure 20 shows some sample output. Notice that the full SELECT statement is captured in the output in Figure 20. This can be useful feedback when you are sending SQL statements from an ASP page because you can confirm how SQL is executing the statements. Tracing is expensive in terms of server resources, so avoid it during heavy traffic, and limit it to your development server whenever possible. Another extremely useful tool for diagnosing ADO errors that occur under ASP is ODBC Trace. You can use ODBC Trace to create a dump of all traffic through any of your ODBC drivers. The tool is configurable through the ODBC Manager option in the Control Panel. Typically, due to its voluminous output, you will want to configure this to run one time only. Once you have set this option, press the Start Trace button as shown in Figure 21. |
 |
| Figure 21: ODBC Trace |
|
The beauty of ODBC Trace is that you can look at how the ODBC driver handles your SQL call. Many of the problems you encounter will leave clues here. These problems are beyond the scope of this article, but the ODBC SDK provides a great reference for helping you read through the trace log. There is always the Errors collection, of course, which can be accessed directly from your ASP script. The ADO Connection object provides this object, which you can drill into and reveal a more informative error message. When the datasource generates and returns errors, this is where you'll find them. Here's an ASP script that uses the Errors collection to check for any errors generated when opening the connection to the database: |
|
|
The Errors collection has two properties: Count and Item. Count will return the number of Error objects in the collection. Item will return a specific Error object from the collection, which you can then inspect for its properties. The Error object's properties are listed in Figure 22. In addition to the provider errors that are described in the Error object and Errors collection, ADO itself may return errors to the exception-handling mechanism of your runtime environment. Figure 23 shows both decimal and hexadecimal error code values.
Tip 10: Use TCP/IP as Your Network Library
|
 |
| Figure 24: Network Library Support |
|
Using TCP/IP as your network library limits you to standard security within SQL Server. This can work out well for a number of reasons. Using integrated security can severely limit the effectiveness of connection pooling in your Web application. For integrated security to work as expected, you need to enforce authentication from the Web server. Authenticating each user allows SQL Server to map the Windows NT® accounts to their corresponding SQL logins, but creates a problem: since each user has a unique login, you've avoided the mechanisms that give you the
performance benefits of connection pooling. Remember, for a connection to be reused, a request for the resource must include a user name and password identical to the existing connection. Many developers choose integrated security, attempting to leverage existing Windows NT accounts, but don't realize that they are sacrificing performance. For one thing, integrated security requires a trusted connection, which means you cannot choose TCP/IP as your network library. The biggest hit is the problem with connection pooling. While it is possible to use connection pooling in conjunction with integrated security by mapping the Anonymous account to a valid SQL account and only allowing anonymous access to your Web site, this is usually not how it's implemented. When sites choose integrated security, they typically also choose challenge/response (currently only supported by Internet Explorer) or basic authentication from the Web server to enforce individual connections to SQL Server. If you choose integrated security and SQL Server is installed on a different server than your Web server, you cannot enable challenge/response from the Web server. In this case, your only authentication options on the Web server are anonymous and basic authentication. If you choose to allow anonymous, you must either create a local account on the SQL Server host machine that has an identical user name and password as the Web server's anonymous account, or you must specify a domain account as the anonymous account on the Web server. This domain account must have appropriate permissions on both machines, including the right to log on locally.
Conclusion
|
From the November 1998 issue of Microsoft Interactive Developer.