Greater Java
By Christoph Lürig
Many Java applets on the Web today have been implemented to perform special effects that cannot be accomplished in HTML. Some common applications of these applets include navigational tools, marquee tools, and banner applets, which show a sequence of images that could be linked to another Web page.
The problem one encounters during the design of Java applets for Web effects is providing flexibility and ease of parameterization for the user who wants to apply it. The standard approach to tackling this problem is to use the PARAM tag in conjunction with the APPLET tag. This way, it's possible to influence the behavior of an applet without manipulating its code. (Further information about the use of the PARAM tag can be found in David Flanagan's Java in a Nutshell [O'Reilly & Associates; 1996] and Stephen R. Davis' Learn Java Now [Microsoft Press, 1996].)
The possible complexity of this approach is limited, as every parameter has to be addressed directly by the source code, and the readability and ease of modification decreases rapidly with increasing demands concerning the parameter section. This is especially true if the number of parameters should be flexible. In this case, parameter names must be provided for the maximum number of parameters that could be used. Regarding slide shows or banners, the use of animated GIFs is a very popular alternative. This solution is very flexible, but is also quite bandwidth-intensive if many images and transitional effects are required.
In this series of articles, we will discuss the architecture of a slide show applet that overcomes the complexity problem of the parameter section and provides a large variety of transitional effects for the images in a slide show. The principal idea in solving the parameter problem is to transfer the information normally given in the parameter section into a separate file that is read by the applet during the initialization phase. The idea to move the parameters into a separate description file can also be found in the Web-based application of ActiveX controls. (Further information about the parameterization of ActiveX controls can be found in Understanding ActiveX and OLE by David Chappell [Microsoft Press; 1996].)
In contrast to the description file read by ActiveX controls, which still uses a parameter name-parameter value structure, the presented proposal uses some kind of simple programming language that describes the slide show. A description of a slide show consists of an arbitrary long sequence of image descriptions that must be displayed sequentially. These descriptions include information about the location of the image file to be displayed, the display time, a possible URL connection, and the transitional effect to blend over to the next image, including the necessary parameters for the effect. As direct naming of any parameters is not required in this technique, it's possible to process an arbitrary long sequence of images in the slide show. As every transitional effect has different parameters and even a different amount of parameters, the use of the standard parameter section in the applet would become very confusing here.
Every transitional effect is a function that maps two input images and a blending parameter to an output image. The blending parameter describes the state of transition between the two images to be blended. Based on this idea, an architecture is constructed where each blending effect is a sub-class of the abstract Effect class. Every effect consists of a parser, which is capable of parsing the effect-specific parameters, and a method that computes the blending function described previously. The most powerful effects of this applet, which provide some pseudo three-dimensional impressions, are based on scan-line-oriented techniques, known in the computer graphics community for polygon drawing and texture mapping purposes. This technique, which reduces arithmetical operations to a minimum by incrementally solving the problem, is necessary to provide sufficient performance for the application of the relatively slow image-manipulating methods provided by Java. (For further information about the computer graphics background of scan-line-oriented techniques, have a look at Computer Graphics Principles and Practice by Foley, van Dam, Feiner, and Hughes [Addison-Wesley, 2nd edition, 1996].)
Due to the complexity of this problem, the overall description of this approach is split into a series of three articles, this being the first installment. This article concentrates on the overall architecture of this applet and the file-parsing mechanism. The next installment will explain some basics of image manipulation and the construction of the pseudo three-dimensional effects using the scan-line-oriented approach, including its mathematical background. It will provide more detail than this article, which focuses more on the global aspects of the applet.
The following section addresses the overall architecture of the applet, which provides a great amount of flexibility. A section about general file parsing follows. It includes a description of language specification in BNF and parser construction using the recursive descent method (both described in Ullmann Aho's Principles of Compiler Design [Addison-Wesley, 1979]). It concludes with a section about practical file parsing in Java.
Architecture
The main tasks that have to be solved by this applet are:
parsing the description of the slide show,
going through the single steps of the show, and
performing the effects.
Every effect is a sub-class of the abstract class Effect, which has a single abstract function overloaded by each effect class.
package luerig.banner;
import java.awt.Image;
import java.awt.image.*;
import java.applet.Applet;
import java.awt.Graphics;
// Effect
// This is an abstract class for all effects
public abstract class Effect {
// Description: This methods perfoms the effect. Given
// two images and their extensions, it draws an image
// sequence to the applet window.
public abstract void performEffect(Image start,
Image ending, int width, int height, Applet applet,
Graphics graph);
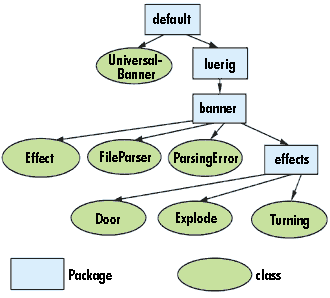
}It requests the image, the blending effect to start with, and the image to end with. All other classes are allocated in the luerig.banner package, except for the main class, UniversalBanner, which is allocated in the default package (see Listing One). The name of this class has to be inserted in the APPLET tag in order to bind this applet into a Web page. The package structure is illustrated in Figure 1.
Figure 1: The package structure of the applet.
Begin Listing One — UniversalBanner.java
import java.applet.*;
import java.awt.*;
import java.awt.image.PixelGrabber;
import java.awt.image.MemoryImageSource;
import java.util.Vector;
import java.io.StreamTokenizer;
import java.io.IOException;
import java.net.URL;
import java.net.MalformedURLException;
import luerig.banner.FileParser;
import luerig.banner.Effect;
import luerig.banner.ParsingError;
public class UniversalBanner extends Applet
implements Runnable {
private Thread m_UniversalBanner = null;
private String m_DescriptionFile = "";
private String m_ServerCode = "";
private int m_xDimension = 0;
private int m_yDimension = 0;
// Parameter name for description file.
private final String PARAM_DescriptionFile = "DescriptionFile";
// The Vector where the images will be stored.
private Vector m_images = new Vector();
// The Vector where the effect objects will be stored.
private Vector m_effects = new Vector();
// URL connections that will be activated.
private Vector m_connections = new Vector();
// The time each image is shown.
private Vector m_times = new Vector();
// Indicates whether an URL is specified for this image.
private Vector m_enabled = new Vector();
// The number of images used in the animation.
private int m_maxNumber;
// The actual number of the image shown.
private int m_actualNum = 0;
// Indicates that loading was successful.
private boolean m_dataOK;
// The parser error message.
private Label m_message = null;
// Used for double buffering.
private Image m_backImage;
private Graphics m_backGraphics;
// Used for the error messages.
private Frame m_frame = null;
private FileParser m_parser = null;
public UniversalBanner() {
}
public String getAppletInfo() {
return "Name: UniversalBanner\r\n" +
"Autor/Autorin: Christoph Lürig\r\n" +
"Erstellt mit Microsoft Visual J++ Version 1.1";
}
public String[][] getParameterInfo() {
String[][] info = {
{ PARAM_DescriptionFile, "String",
"The source of the description file" },
};
return info;
}
// This routine activates the parsing process and
// prepares the applet for double buffering.
public void init() {
String param;
URL connection;
m_dataOK = true;
param = getParameter(PARAM_DescriptionFile);
if (param != null)
m_DescriptionFile = param;
m_xDimension = size().width;
m_yDimension = size().height;
resize(m_xDimension, m_yDimension);
m_frame = new Frame("Error message");
m_backImage = createImage(m_xDimension, m_yDimension);
m_backGraphics = m_backImage.getGraphics();
// Parse the file.
try {
connection = new URL(getDocumentBase(),
m_DescriptionFile);
m_parser = new FileParser(
new StreamTokenizer(connection.openStream()), this);
m_maxNumber = m_parser.getData(m_images, m_effects,
m_times, m_enabled, m_connections);
}
catch (MalformedURLException exception) {
m_message = new Label(
"URL of description file malformed");
m_dataOK = false;
}
catch (IOException exception) {
m_message = new Label(
"Could not find URL of description file");
m_dataOK = false;
}
catch (ParsingError e) {
m_message = new Label(e.getMessage());
m_dataOK = false;
}
}
public void destroy() {
}
public void paint(Graphics g) {
// Just put the stored image to the screen.
g.drawImage(m_backImage, 0, 0, null);
}
// We want to avoid to draw the background before drawing
// the true image.
public void update(Graphics g) {
paint(g);
}
// Starts the slide show thread, eventually pops up error
// message if an error is present.
public void start() {
if (m_UniversalBanner == null) {
if (m_dataOK) {
m_UniversalBanner = new Thread(this);
m_UniversalBanner.start();
}
else {
m_frame.show();
m_frame.setLayout(new FlowLayout());
m_frame.add(m_message);
m_frame.resize(new Dimension(600, 100));
}
}
}
// Stops the animation thread and hides the error frame.
public void stop() {
m_frame.hide();
if (m_UniversalBanner != null) {
m_UniversalBanner.stop();
m_UniversalBanner = null;
}
}
// Checks if the dimensions of the image positioned in
// the image vector at index matches the dimensions of
// the display area of the applet. If this is not the
// case the image is resampled to fit the area. Aspect
// ratio may be distroyed here.
private void checkDimensions(int index)
throws InterruptedException {
Image image = (Image)(m_images.elementAt(index));
int width = image.getWidth(null);
int height = image.getHeight(null);
double xstep, ystep;
int dataA[];
int dataB[];
double xorig, yorig;
int i, j;
PixelGrabber grabbera;
Image result;
if ((width != m_xDimension) ||
(height != m_yDimension)) {
dataA = new int[width*height];
dataB = new int[m_xDimension * m_yDimension];
xstep = ((double)(width)/(double)(m_xDimension));
ystep = ((double)(height)/(double)(m_yDimension));
grabbera = new PixelGrabber(image, 0, 0, width,
height, dataA, 0, width);
grabbera.grabPixels();
xorig = yorig = 0.0;
for (j = 0; j<m_yDimension; j++) {
for (i = 0; i<m_xDimension; i++) {
dataB[i + m_xDimension*j] =
dataA[(int)xorig + (int)yorig * width];
xorig += xstep;
}
yorig += ystep;
xorig = 0.0;
}
MemoryImageSource source = new MemoryImageSource(
m_xDimension, m_yDimension, dataB, 0, m_xDimension);
Image trans = createImage(source);
m_images.setElementAt(trans, index);
}
}
// This method performs the slide show. It cycles
// through all images and effects. It displays the images
// and performs the effects. The handling of the parsing
// error is inserted here, if one image does not exist.
public void run() {
Image first, next;
int lastNum;
while (m_dataOK) {
try {
m_parser.syncImage(m_actualNum);
checkDimensions(m_actualNum);
first = (Image)(m_images.elementAt(m_actualNum));
m_backGraphics.drawImage(first, 0, 0, null);
repaint();
Thread.sleep((int)(1000.0*((Double)(
m_times.elementAt(m_actualNum))).doubleValue()));
lastNum = m_actualNum;
m_actualNum = (m_actualNum+1)%m_maxNumber;
m_parser.syncImage(m_actualNum);
checkDimensions(m_actualNum);
next = (Image)(m_images.elementAt(m_actualNum));
((Effect)(m_effects.elementAt(lastNum))).
performEffect(first, next, m_xDimension,
m_yDimension, this, m_backGraphics);
}
catch (InterruptedException e) {
stop();
}
catch (ParsingError e) {
m_frame.show();
m_frame.setLayout(new FlowLayout());
m_frame.add(new Label(e.getMessage()));
m_frame.resize(new Dimension(600, 100));
m_dataOK = false;
}
}
}
// Check if the actual image URL is defined and whether
// we can jump to a new URL.
public boolean mouseDown(Event evt, int x, int y) {
if (((Boolean)(m_enabled.elementAt(
m_actualNum))).booleanValue())
getAppletContext().showDocument((URL)(
m_connections.elementAt(m_actualNum)));
return true;
}
}End Listing One
As the constructor of every effect class has the possibility to parse its own parameters, extending the variety of effects mainly means constructing a new sub-class of the effect class. These effect classes compute the interpolating images of the slide show on the fly. (The function of the blending effects will be discussed in more detail in the next installments of this series.)
The parsing of the description file is done by the FileParser class (see Listing Two), which constructs mainly five vectors containing the information of the animation for each image. These vectors contain:
Begin Listing Two — FileParser.java
package luerig.banner;
// FileParser
import java.applet.Applet;
import java.io.StreamTokenizer;
import java.io.IOException;
import java.util.Vector;
import java.net.URL;
import java.net.MalformedURLException;
import java.awt.MediaTracker;
import java.awt.Image;
import luerig.banner.ParsingError;
import luerig.banner.effects.*;
// This class parses the desciption file and generates the
// necesarry vectors to perform the animation tasks.
public class FileParser {
private StreamTokenizer m_tokenizer;
private Applet m_applet;
private MediaTracker m_tracker;
// Initializes the file parser. The applet parameter is
// used to fetch the images from the server.
public FileParser(StreamTokenizer tokenizer, Applet applet) {
tokenizer.eolIsSignificant(false);
tokenizer.slashSlashComments(true);
tokenizer.quoteChar('"'); // Initialize the parser.
m_tokenizer = tokenizer;
m_applet = applet;
m_tracker = new MediaTracker(m_applet);
}
// This method forces the file parser to load the image,
// that is indicated by the number handed over.
public void syncImage(int number)
throws InterruptedException, ParsingError {
String Snumber = (new Integer(number+1)).toString();
m_tracker.waitForID(number);
if (m_tracker.isErrorID(number))
throw new ParsingError(
"Image file does not exist in image description " +
Snumber);
}
// This method will perform the whole parsing process.
// It returns all the vectors for every image, with its
// effect that will turn it into the next one, the timer
// vector an enabling vector if any connections can be
// made and a vector with the connections itself. Returns
// the number of images read.
public int getData(Vector images, Vector effects,
Vector times, Vector enables, Vector connections)
throws ParsingError {
int actToken;
ParsingError error = null;
int numbers = 0;
try {
actToken = m_tokenizer.nextToken();
while (actToken != StreamTokenizer.TT_EOF) {
m_tokenizer.pushBack();
readImageComplex(numbers, images, effects, times,
enables, connections);
numbers++;
actToken = m_tokenizer.nextToken();
}
} // We have read the complete description file
catch (IOException exception) {
error = new ParsingError(
"File corrupted EOF missing");
throw(error);
}
return numbers;
}
// Load a single image form the server
private void readImage(int number, Vector images)
throws ParsingError {
int tokenType;
String Snumber = (new Integer(number+1)).toString();
Image transIm;
URL imageresource;
try {
imageresource = new URL(m_applet.getDocumentBase(),
m_tokenizer.sval);
transIm = m_applet.getImage(imageresource);
m_tracker.addImage(transIm, number);
images.addElement(transIm);
}
catch (MalformedURLException except) {
throw new ParsingError(
"Malformed URL for image in image description " +
Snumber);
}
}
// Reads a description of a single image description. It
// parses linearly.
private void readImageComplex(int imageNumber,
Vector images, Vector effects, Vector times,
Vector enables, Vector connections)
throws ParsingError, IOException {
int tokenTyp;
String tokentext;
String number;
int frames;
number = (new Integer(imageNumber+1)).toString();
tokenTyp = m_tokenizer.nextToken();
if ((tokenTyp != m_tokenizer.TT_WORD) ||
(!m_tokenizer.sval.equals("IMAGE")))
throw new ParsingError(
"Token IMAGE expected in image description " +
number);
tokenTyp = m_tokenizer.nextToken();
if (tokenTyp < 0)
throw new ParsingError(
"Image description expected in image description " +
number);
readImage(imageNumber, images);
tokenTyp = m_tokenizer.nextToken();
if (tokenTyp != m_tokenizer.TT_WORD)
throw new ParsingError(
"Token URL or TIME expected in image description " +
number);
if (m_tokenizer.sval.equals("URL")) {
tokenTyp = m_tokenizer.nextToken();
if (tokenTyp<0)
throw new ParsingError(
"Url for linkage expected in image description " +
number);
enables.addElement(new Boolean(true));
connections.addElement(new URL(
m_applet.getDocumentBase(), m_tokenizer.sval));
tokenTyp = m_tokenizer.nextToken();
}
else {
enables.addElement(new Boolean(false));
connections.addElement(null);
}
if ((tokenTyp != m_tokenizer.TT_WORD) ||
(!m_tokenizer.sval.equals("TIME")))
throw new ParsingError(
"Token TIME expected in image description" +
number);
tokenTyp = m_tokenizer.nextToken();
if (tokenTyp != m_tokenizer.TT_NUMBER)
throw new ParsingError(
"Time value expected in image description" +
number);
times.addElement(new Double(m_tokenizer.nval));
tokenTyp = m_tokenizer.nextToken();
if ((tokenTyp != m_tokenizer.TT_WORD) ||
(!m_tokenizer.sval.equals("FRAMES")))
throw new ParsingError(
"Token FRAMES expected in image description " +
number);
tokenTyp = m_tokenizer.nextToken();
if (tokenTyp != m_tokenizer.TT_NUMBER)
throw new ParsingError(
"Number of frames expected in image description " +
number);
frames = (int)(m_tokenizer.nval);
tokenTyp = m_tokenizer.nextToken();
if ((tokenTyp != m_tokenizer.TT_WORD) ||
(!m_tokenizer.sval.equals("EFFECT")))
throw new ParsingError(
"Token EFFECT expected in image description " +
number);
readEffect(imageNumber, frames, effects);
}
// Description: Dispatches the effect type and constructs
// object of a Effect subclass.
private void readEffect(int imageNumber, int frames,
Vector effects) throws ParsingError, IOException {
int tokenType;
String Snumber =
(new Integer(imageNumber+1)).toString();
tokenType = m_tokenizer.nextToken();
if (tokenType != m_tokenizer.TT_WORD)
throw new ParsingError(
"Effect Description expected in image description "
+ Snumber);
if (m_tokenizer.sval.equals("FLYING"))
effects.addElement(new Explode(m_tokenizer, frames,
Snumber));
else if (m_tokenizer.sval.equals("TURNING"))
effects.addElement(new Turning(m_tokenizer, frames,
Snumber));
else if (m_tokenizer.sval.equals("DOOR"))
effects.addElement(new Door(m_tokenizer, frames,
Snumber));
else
throw new ParsingError(
"Unknown effect in image description " + Snumber);
}
}End Listing Two
the images to be displayed;
the time each image should be shown before being switched over to the next one;
a vector that indicates whether the image to be displayed should be linked to another document; and
one vector where the URL of the document to be displayed is stored.
The FileParser class itself analyzes all parameters except for the effect-specific ones. When the effect is specified, the token stream needed in the parsing process is handed over to the constructor of the corresponding effect class. The resulting effect object is then inserted into the effect vector. The FileParser class is also responsible for the loading of the images via a media tracker.
The syncImage method (see Listing Two) forces the applet to load the image file from the server. Because this method is called immediately before the image is displayed, not all images must be loaded during the initialization phase at once.
The exception class, ParsingError, has been designed to pass any syntactical and simple semantic errors to the main class and to the user:
package luerig.banner;
import java.lang.Exception;
// ParsingError
// Just to get a special type for this exception.
public class ParsingError extends Exception {
public ParsingError(String message) {
super(message);
}
}Next, we'll look at the construction and the functionality of such a file parser.
The main class, which subclasses the Applet class, is the UniversalBanner class (again, see Listing One). Its most important instance variables are the five vectors generated by the parser class. The instance variables, m_backGraphics and m_backImage, are used to perform a double-buffering technique (described in Special Edition Using Visual J++ by Culverhouse, Walnum, Howell, Perry [Que Corporation, 1996] in full detail). This double-buffering technique avoids flickering if the applet window is redrawn. The thread spawned by an object of this class cycles through the images in the vectors, displays the images, waits a certain amount of time, and activates the appropriate effect class to blend over to the next image.
The only error that may occur at this stage is that an image can't be loaded from the server. This also evokes a ParsingError. If the loaded image does not fit the required applet dimensions, the rescaling method checkDimensions, which resamples the loaded image to fit the required size, is applied. The mouseDown event handler checks if a link for the displayed image is defined and activates a jump to the corresponding URL if this is the case.
File Parsing
One of the main components of the applet under discussion is the file parser, which provides the flexibility in this applet. The application of such a parsing mechanism is necessary because the exact structure and length of the file is unknown. There may be an arbitrary number of effects and images to be displayed, and there may or may not be an URL link. The type and number of effect specific parameters depends on the effect. This means that a straightforward file reading is not sufficient. The solution to this problem is to apply parsing techniques, which are usually used in the implementation of compilers. This section discusses the general theory of parser construction; the following section addresses the implementation of such mechanisms in Java.
[Note: A file parser per se isn't a necessity. An alternate architecture is to use an independent application that presents a user interface where the user chooses files and effects, sets effect parameters, and saves the results as serialized Java objects. The applet would then stream in the serialized objects without needing a special parser. This architecture shifts some of the programming and run-time burden from the applet to an off-line application, both of which have distinct advantages, most notably a smaller applet to download and faster loading of parameters.]
The problem addressed by file parsing includes transforming a stream of characters into an internal representation that may be easily processed. This transformation may be divided into two major steps: the lexical and the syntactical analysis (explained in Ullmann Aho's Principles of Compiler Design [Addison-Wesley, 1979] and shown in Figure 2).
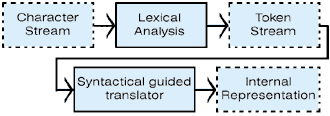
Figure 2: The transformation of a stream of characters into an easily-processed internal representation takes two major steps: a lexical and syntactical analysis.
The lexical analyzer reads in the raw character stream and performs some simple preprocessing. This includes transforming carriage returns into white spaces, eating up extra white spaces between words, and deleting the comments. Special reserved words and numerical or string parameters are identified here. The result of this analysis is a token stream that is processed by the syntactical guided translator. This is a producer-consumer process. The lexical analysis abstracts from pretty printing file lay-outs and comments, which are irrelevant for the generation of the internal representation.
The more complex part is the syntactical guided translator. The basic idea of this translator is that the language used for the description file is described by a certain grammar. The internal representation is then generated by applying this grammar to the analyzed token stream. This identifies the structures of the description file. This process is described in more detail in the following paragraphs.
The kind of grammar applied here for the syntactical guided translation is the so-called context-free grammar. A context-free grammar is defined by four items:
A set of terminal symbols.
A set of non-terminal symbols.
A set of production rules in the form of Left Right, where Left is a non terminal symbol and Right is an arbitrary sequence of terminal and non-terminal symbols.
A start symbol, which is an element of the set of non-terminal symbols. This symbol is sometimes called the axiom.
A terminal symbol represents a word that may appear in a language. The non-terminal symbols represent certain grammatical categories that may be substituted directly or indirectly by a number of terminal symbols. The production rules describe how non-terminal symbols may be substituted by a sequence of terminal — and possibly non-terminal — symbols. If these production rules are iteratively applied to the start symbol until the generated sequence of words does not contain any non-terminal symbols, all sequences of words of this language may be generated. This is explained by an example oriented at Patrick Henry Winston's Artificial Intelligence, 3rd edition [Addison-Wesley, 1993] (see Figure 3).
| Terminal symbols | {the, to, a, Sarah, book, returns, library} |
| Non-terminal symbols | {Phrase, VerbalPhrase, NounPhrase, PrepositionalPhrase, Verb, Noun, Preposition, Specifier} |
| Production Rules | { PhraseNounPhrase VerbalPhrase PrepositionalPhrase, NounPhrase Noun, NounPhraseSpecifier Noun, PrepositionalPhrasePreposition NounPhrase, VerbalPhrase Verb NounPhrase, Verbreturns, Nounbook, Nounlibrary, NounSarah, Specifierthe, Specifiera, Prepositionto } |
| Start symbol | Phrase |
Figure 3: Context-free grammar is defined by four items.
The following sequence of words would be syntactically correct according to the defined grammar: Sarah returns a book to the library. This can be illustrated by means of the parsing tree, which sketches the applied production rules (see Figure 4). Basically, all parsing mechanisms should be able to generate such a tree. All symbols may carry some extra attributes that are used later on for the construction of the internal representation. The production rules are marked with some rules on how to combine the results of the derived symbols. This annotation information is usually collected in a depth-first manner. In our case, the symbols evoke the construction of Java objects that are accumulated to larger objects.
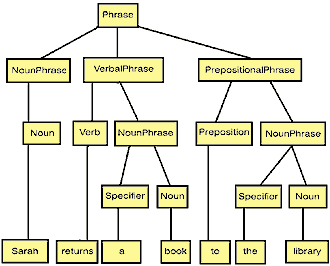
Figure 4: The parsing tree.
As the definition of grammar is quite difficult to read, a special form of notation, the BNF, has been invented. Syntactical specifications of program languages are usually presented in this notation. All non-terminal symbols are marked by corner brackets and all production rules that have the same left-hand side are accumulated into one rule, using the pipe ( | ) symbol as a separator. Using this form of notation, the presented little grammar would look like this:
<Phrase>::=<NounPhrase> <VerbalPhrase> <PrepositionalPhrase>
<NounPhrase>::=<Noun> | <Specifier> <Noun>
<VerbalPhrase>::=<Verb> | <NounPhrase>
<PrepositionalPhrase>::=<Preposition> <NounPhrase>
<Noun>::=Sarah | book | library
<Verb>::=returns
<Specifier>::=a | the
<Preposition>::=toHere, again, the start symbol is <Phrase>. This specification still describes the same grammar, but is far easier to read and to understand. The grammar of the description language for the banner applet, where <slideshow> is the start symbol, is a bit more complex and looks like this:
<slideshow>::=<imageDescription> |
<imageDescription> <slideshow>
<imageDescription>::=IMAGE <string> <connection> <float>
FRAMES <integer> EFFECT <effect>
<connection>::=URL <string> TIME | TIME
<effect>::= FLYING <flyEffect> | TURNING <integer> |
DOOR <doorEffect>
<flyEffect>::=<direction> <flyTurn>
<direction>::=IN | OUT
<flyTurn>::=XTURN | YTURN | NOTURN
<doorEffect>::=<doorDir> <float>
<doorDir>::=OPEN | CLOSEPlease note that the parser is case-sensitive.
The non-terminal symbol <float> stands for an arbitrary float value, <integer> for an integer value, and <string> for a string value.
As an example, a legal description file could look like this:
IMAGE "Bilder/Firma.jpg" URL "index.html"
TIME 2 FRAMES 40 EFFECT FLYING OUT XTURN
IMAGE "Bilder/Image2.gif"
TIME 3 FRAMES 40 EFFECT TURNING 1
IMAGE "Bilder/Firma.jpg" URL "index.html"
TIME 3 FRAMES 40 EFFECT DOOR CLOSE 0.8
IMAGE "Bilder/Image6.gif"
TIME 3 FRAMES 40 EFFECT DOOR CLOSE 0.8The major question remaining is how to construct a parsing mechanism for a specified grammar that is capable of constructing a parsing tree and the appropriate internal representation. Luckily, there are methods to transform a certain grammar directly into a parsing mechanism. The method applied here is the method of recursive descent. This method constructs the parsing tree in a top-down fashion. It is of linear-time complexity and does not need any backtracking, but it imposes a few extra restrictions onto the context-free grammar. The restriction is that if there is the possibility of a multiple substitution for a non-terminal symbol, these possibilities must result in different terminal symbols, in the first position of the finally resolved terminal symbol of the right-hand side. This restriction guarantees that it is sufficient to have a look at the next token of the incoming stream to decide which rule to apply.
The parser is now constructed by writing one procedure (for every production rule) that reads the tokens from an incoming stream and performs recursive calls for every non-terminal symbol to parse. The return value of such a procedure is the internal representation of the analyzed token stream. The results from the recursive calls of the procedure for the non-terminal symbols that are on the right-hand side of the regarded production rule are integrated into the current result. If there is a multiple-choice option in one production rule, the correct choice is made by regarding the next token to be read. Due to the restriction to the general context-free grammar described above, it's possible to base the correct decision on this single token only. Error checking for syntactical or some semantic errors can also be done in these procedures. If the method for the start symbol is then called with the overall token stream, the inner representation of the description is generated.
The following section describes practical implementation aspects of file parsing in Java.
Practical Aspects of File Parsing in Java
To implement a file parser in Java, a lexical analyzer and the syntactical guided translator have to be implemented. Luckily, a lexical analyzer is already shipped with the Java core classes — the StreamTokenizer class, which is part of the java.io package. The basic idea of it is that it takes an input stream in the constructor and delivers the tokens via the nextToken method. The result of this method is whether a token was detected, the end of the file, a numeric value, or the end of a line.
As described in the next paragraph, the detection of line endings is disabled in this application. The string and token values are written into the sval variable, while the numerical results are written into the nval variable. Another very practical method is the pushBack method, which pushes back the last token read. This method is very useful in combination with the recursive descent analysis. If the parser runs into a multiple-choice situation, the decision of which branch to descend is made by the next token to be read. If this decision is made, the last token read is pushed back, so that the next parsing procedure can read it again.
Before the StreamTokenizer class is used to deliver the tokens, a few parameters have to be set that determine how to perform the lexical analysis. In this case, the eolIsSignificant method has been used to make the tokenizer ignore the ends of lines and treat them as white space. The slashSlashComments method is used to indicate that text behind a double slash should be ignored, as this is a C++-style comment and should not be passed on to the syntactical guided translator. Finally, the quoteChar method indicates the character that encloses strings, which are returned in a single block by the tokenizer object.
To implement the syntactical guided translator, a parsing method should be implemented for every production rule displayed in the grammar definition. However, to keep the program simple and efficient, only three levels of recursion have been implemented, which does not change the basic idea of the recursive descent. The top method that parses the overall file, which is represented by the <slideShow> symbol, is the getData method, which constructs the five main vectors with the slide show description. According to the grammar, it should recursively call itself until all image descriptions are read. This recursive descent is linearized into a while loop for efficiency reasons and to keep the stack memory requirements low.
There is another — and perhaps better — reason that the loop is easier to understand than recursion in this case. Without a tail-recursive compiler (and I know of no Java compiler that implements tail recursion), the recursion stack would grow to the number of images. Because you never want an unbounded execution stack, use of the while loop is sound choice.
The readImageComplex method parses the <imageDescription> symbol. The parsing of the <connection> symbol is also done in this method, as the calling of a new method to parse this item would not be appropriate. The parsing of the <effect> tag is also done in the readImageComplex method for the same reason. Depending on the name of the effect, which is always a terminal symbol appearing in front of the effect-specific parameters, different constructors for the according effects are invoked. All effect-specific parameters are parsed by the constructors of the indicated effect. These constructors return the objects for the specific parameters, which are then inserted into the Effect vector, so the pieces of the internal description of the slide show is pieced together from the leaves of the parsing tree up to its root.
(Note: This example used 13MB of RAM with Netscape 4.0 in a Windows 95 machine with 64MB RAM and 500MB virtual memory, and 80-110MB using Internet Explorer 4.0.)
Conclusion
After an overview of the slide-show applet and the major tasks it addressees, the overall architecture has been described, followed by a detailed explanation of the file parser and its principles. This file parser provides the flexibility that is necessary to implement an applet or application with a wide variety of parameterization possibilities. The question remaining is how to construct and implement the image blending effects that make up the real application of this applet. These effects will be discussed next month.
The project referenced in this article is available for download from the Informant Web site at http://www.informant.com/ji/jinewupl.htm. File name: JI9810CL.ZIP.
Born in Germany, Christoph is currently working on his PhD thesis in Computer Graphics. Published work includes a Computer Graphics International Paper and two IEEE Visualization papers (further information and the text can be found at http://www9.informatik.uni-erlangen.de). After receiving his PhD, Christoph plans to apply for a job in the games industry. His platform experience covers SGI IRIX, Win32, and Sony Playstation. Christoph can be reached at CLuerig@aol.com.
Download source code for this article here.