April 1998
![]()

Download Apr98Bugslayer.exe (147KB)
|
John Robbins is a software engineer at NuMega Technologies Inc. who specializes in debuggers. He can be reached at john@jprobbins.com. |
|
Here is the scenario: you are quietly plugging
away at work, minding your own business, when
the Vice President of ThankYouWellcome comes into your office screaming about how your application crashed. You calmly ask what he was doing when it crashed. At the top of his lungs, the VP bellows "Demoing it!" After giving the VP a very cool look you say, "That doesn't really give me a whole lot to go on." The VP then turns red and says that he wrote down some of the things that were on the screen and one of them said something about "address" and "crash." At this point the VP gives you the really big hairy eyeball and says "You're a programmer. You know what an address is. Fix it or else!"
We've all been in that situation. Most of the time there is just not much you can do with a crash address—until now. In this month's column, I will explain how to easily find the exact function, source code file, and line where a crash occurred when given nothing more than the crash address. These techniques work for both Visual C++® and Visual Basic®-based code. First, I will give you some very simple bugslaying rules to follow during development that maximize your chances of always finding the crash location. These rules might be old hat to some, but I want to make sure that everyone—especially anyone who's new to Windows®-based development—is up on them. Second, I will present the appropriately named CrashFinder app that does all the work of finding a crash for you.
A Few Simple Bugslaying Rules
One misconception people have about creating debug symbols for an application is that they can only be created with a debug build. Fortunately, with Microsoft® compilers this is not the case; debug symbols can be created no matter how much optimization you are asking the compiler to perform. One difference between a debug build and a release build is that single-stepping through a release build with symbols can sometimes mean the source lines are not executed in order. This is because the optimizer reordered the code to make it faster. Another difference is that the call stack and some local symbols might not be available when running under a debugger because the code can be optimized so that the stack frame is not there. However, if you read Matt Pietrek's February 1998 column (Under the Hood), his crash course in assembler shows you how to figure out exactly what is happening. Another misconception is that building your application with debug symbols will make it possible for others to reverse engineer your application and steal all of your secrets. The PDB symbol format does not store any information in your binary other than the name of the PDB file. This adds 1KB to the size of your application. You can afford the minimal extra space to get the huge benefit of being able to debug your release builds. The second simple rule is to save in a safe place exact copies of the binaries that you send to testers or others. This includes copying all the associated PDB files. Again, this might seem like common sense, but I have seen too many cases where someone slipped in a "minor little change" before the source code was marked in the version control system. Therefore, there is no way to get the same build that has the crash in it. Saving all the binaries and PDB files maximizes your CrashFinder usage, as I will show you later. The third simple rule is to always rebase your DLLs and OCXs so that they load at unique addresses in your address space. If you ever see the following notification in the debugger output window, you need to stop and fix the load addresses of the conflicting DLLs immediately: |
|
|
The xxx and yyy in this statement are the names of the DLLs that are conflicting. DLL load address conflicts are very bad because different machines and operating systems can load the DLL into different places. This means that if the relocated DLL crashes, you have no idea which DLL the crash occurred in since the operating system just reports the main executable that crashed, not the DLL. The other reason to make sure load addresses are unique is that when the operating system relocates a DLL, it can slow your application down. When relocating, the operating system needs to read all the relocation information for the DLL, run through each place in the code that accesses an offset into the code, and change it. If you have a couple of address conflicts in your app, it sometimes makes your startup more than twice as slow!
There are two ways to set the load addresses for your application. The best method is to use the REBASE.EXE utility that comes with the Platform SDK. While REBASE.EXE has many different options, the best thing to do is to call it using the –b command-line option with the starting base address and put all of your DLLs on the command line. The MSDN™ documentation for REBASE.EXE suggests a rebasing scheme based on the alphabetical sorting of the DLL names. To keep life simple, I have always followed that scheme. You should run REBASE.EXE as part of your build process to ensure that it is always done. The other method of setting a load address is to specify it when you link each of your DLLs. In Visual C++, specify the address with the /BASE option to LINK.EXE. In the Visual Basic Project Properties Compile Tab, set the address in the DLL Base Address field. While it is preferable to use REBASE.EXE, you might need to set the address manually if you are working around third-party DLLs and OCXs. If you look at the Visual C++ project for BugslayerUtil.DLL, you'll see that I used this method to set the base address in an attempt to avoid conflicts if other applications eventually use it. The default base address for all DLLs is 0x10000000 and I did not want to conflict with that. The fourth simple rule is, yet again, along the common sense line: try to maximize the information your users or testers can give you about a crash. You can do this by writing crash handlers either in your application or by specifically asking the user for the Dr. Watson logs for your crash. Crash handlers are exception handlers. They trigger on crashes and dump the state of the application. I will be discussing these in a future column. Getting the Dr. Watson log can be a godsend. It will list all sorts of information about the state of the system and will even walk the stack to give you additional addresses that you can look up with CrashFinder. If you are sending out beta versions, you might want to remind your users to set up Dr. Watson and send you the logs for any crashes that occur with your application. An even better idea is to have your installation program check that Dr. Watson is already installed in the HKEY_LOCAL_MACHINE\SOFTWARE\ Microsoft\Windows NT\CurrentVersion\AeDebug key. Of course, you should only do this check during your beta cycle.
The IMAGEHLP.DLL Saga
Using CrashFinder
|
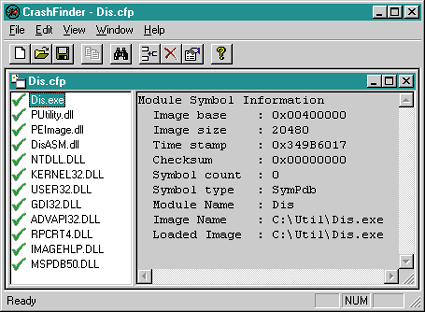 |
| Figure 1 CrashFinder UI |
|
Adding a binary image to a CrashFinder project is done through the Edit|Add Image menu command. When adding binary images, CrashFinder will only accept a single EXE for the project. For your applications comprised of multiple EXEs, create a separate CrashFinder project for each one. Since CrashFinder is an MDI application, you can easily open all the projects for each of your EXEs to locate the crash location. When adding DLLs and OCXs, CrashFinder checks that there are not load address conflicts with any other DLLs already in the project. If there are, CrashFinder will allow you to change the load address for the conflicting DLL just for the current instance of the CrashFinder project. This is very handy when you have a CrashFinder project for a debug build and you just built a single DLL without rebasing the whole debug build.
As your application changes over time, you can remove binary images by selecting the Edit|Remove Image menu item. You can also change the load address for a binary image through the Edit|Image Properties menu at any time. Also, it's a good idea to add any system DLLs that your project uses so you can find places where you caused a crash in them as well. The important part about CrashFinder is finding a crash address. Selecting the Edit|Find Crash menu option brings up the Find Crash dialog. Figure 2 shows an example of finding an address. All you need to do is type the hexadecimal address in the edit control and press the Find button for each address that you want to look up. |
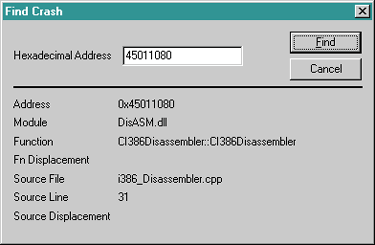 |
| Figure 2 Finding a crash address |
|
The lower part of the dialog lists all the information about the last address looked up. Most of the fields in the lower part of the dialog should be obvious. The Fn Displacement field shows how many code bytes from the start of the function the address is. The Source Displacement field tells you how many code bytes the address is from the start of the closest line. Remember that many assembler instructions can make up a single line, especially if call functions are part of the parameter list.
Keep in mind when using CrashFinder that you cannot look up an address that is not a valid instruction address. If you're programming in C++ and you blow out this pointer, you can cause a crash in an address like 0x00000001. Fortunately, those types of crashes are not as prevalent as the usual memory access violation crashes, which are easily found with CrashFinder. If your current application is perfect and you do not have any crashes to look up, I included a small sample application in the source code for this month's column that you can use to test out CrashFinder. This application, CrashOmatic, is a simple console executable with two DLLs that can crash in different places. The README file explains how to build it. Now that you know a little about using CrashFinder, I want to point out some of the implementation highlights.
Implementing CrashFinder
Exercises for the Reader
Wrapup
Da Tips!
|
|
|
I have often spent 10 or 15 minutes tracking down a
bug where it turned out I forgot to initialize one of these structs with the #!$% size! (Thanks to Paul DiLascia, askpd@pobox.com.)
Have a tricky issue dealing with bugs? Send your questions or bug slaying tips via email to John Robbins: john@jprobbins.com
|
From the April 1998 issue of Microsoft Systems Journal.