June 1998
![]()

Download Jun98CQAcode.exe (16KB)
|
Paul DiLascia is the author of Windows ++: Writing Reusable Code in C++ (Addison-Wesley, 1992) and a freelance consultant and
writer-at-large. He can be reached at askpd@pobox.com
or http://pobox.com/~askpd.
|
|
Q I am trying to build an MFC app in which individual classes can handle menu commands. Unfortunately, it is either so hard that no one wants to discuss it or so easy that it does not require discussion.
In my MDI project I added several items to one of the menu popups. The command handlers for these items are in classes CItem1 and CItem2, which are defined and implemented in their own files: item1.h, item1.cpp, item2.h, and item2.cpp. Everything works fine when I put the handlers in my frame window class, but when I try to let CItem1 or CItem2 handle the messages, nothing happens. For example, if I add |
|
| to CItem1 and CItem2, and then add |
|
|
to their respective implementation files item1.cpp and item2.cpp, then the commands are visible in the menu, but they are disabled.
The ultimate goal is to implement classes that have several specific functions that would be activated by the user menu selections. Some of the functions do not display anything, so I don't see the benefit of using the doc/view architecture. Kriss Ashley
A
What you're trying to do is quite natural and should be encouraged. After all, the main idea of object-oriented programming is to encapsulate object-specific behavior within classes. In a Windows®-based app, that would include handlers for menu commands. If a particular class handles a particular command, why should the frame have to get involved?
One of the great features of MFC is that it provides a way for any kind of object—not just windows—to handle menu commands. For example, in a typical MFC doc/view app, the document handles File | Save. You probably never even noticed anything unusual about this, but it is unusual. Why? Because a document is not a window. Under Windows, only windows can process commands since only windows get WM_COMMAND messages. But MFC has a mechanism to translate WM_COMMAND messages into a more general notion of "command" that other kinds of objects can handle. The catch is, it requires a few lines of code to set things up. |
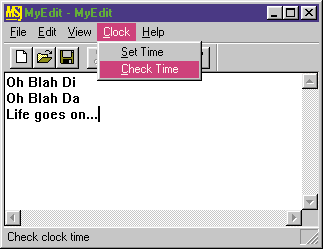 |
| Figure 1 MYEDIT with Clock |
|
|
|
| To create a clock object, I put an instance as a data member in my main frame class, CMainFrame. |
|
All this should seem pretty simple and straightforward. The only problem is, if you write and compile the code as shown so far, the Clock | Set Time and Clock | Check Time functions will appear disabled because as far as MFC can tell, there's no handler for either command. Why doesn't MFC recognize my CClock handlers? Because the clock isn't hooked up yet.
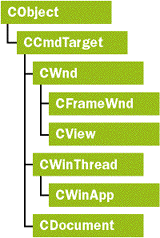
To understand what I'm talking about, let's take a look at how MFC routes commands in a vanilla app. The standard AppWizard-generated app has application, frame, view, and document classes and objects. As Figure 3 shows, all of these classes are derived from CCmdTarget. When the user invokes a menu command, say File | Save, Windows sends the frame window a WM_COMMAND message with ID_FILE_SAVE as the command ID. A veritable flurry of activity ensues—all sorts of processing and calling of functions—but eventually CWnd packages the WM_ COMMAND arguments and passes them to a virtual function called OnCmdMsg. You don't really need to understand what the arguments are, all you really need to know is that, collectively, they describe the command-for example, its ID. (For more detail, see my article, "Meandering Through the Maze of MFC Message and Command Routing," in the July 1995 issue of MSJ.) OnCmdMsg is a CCmdTarget function, but since it's virtual, CFrameWnd is free to override it: | ||||
|
|
One interesting thing about this function is that it doesn't actually do anything! It merely passes its arguments to the OnCmdMsg functions of other objects within the system—first the active view, then itself, then the application object. Likewise, CView::OnCmdMsg has a similar implementation that passes the arguments to its own base class OnCmdMsg first, then its document's OnCmdMsg function—which explains how the document gets in on the action. CMDIFrameWnd has an OnCmdMsg function that calls OnCmdMsg for the active child frame. None of these OnCmdMsg functions do any work; they just pass their arguments to other objects, including themselves. The only function that does anything is the base class CCmdTarget::OnCmdMsg, the same base class implementation used for all command targets.
When a class calls its own base class OnCmdMsg, control eventually arrives at CCmdTarget::OnCmdMsg, which is where the real action takes place. CCmdTarget::OnCmdMsg deciphers the arguments and determines whether the object (the this pointer) has a message map with an ON_ COMMAND handler for the command. If so, CCmdTarget:: OnCmdMsg calls the handler and returns TRUE (handled); otherwise it returns FALSE (not handled). If any object's OnCmdMsg returns TRUE, CFrameWnd:: OnCmdMsg returns TRUE; otherwise, it calls the next object. In this manner, each object—view, doc, frame, or app—gets its crack at the command. MFC has gone a bit over the top in recent years, but this command routing system is one of the really neat and clean core features. The only problem is, it's so neat you don't even notice it. Like you said, either it's so hard no one wants to discuss it or it's so easy it doesn't require discussion. The truth is, it's so easy no one remembered to discuss it. Let's assume you've already derived your class from CCmdTarget and written command handlers for it. The only thing you still must do to hook your object up to the command system is call its OnCmdMsg function from the OnCmdMsg function of some other class that's already hooked up. In a typical doc/view app, that would be the frame, doc, view, or app's OnCmdMsg function. Which should you use? The obvious answer is whichever object owns your new command target. In my case, CClock is instantiated as a member of CMainFrame, so CMainFrame is where I hook it into the command system. |
|
| That's all you have to do. If your object were created within, say, a document, then you'd write a CMyDoc::OnCmdMsg function similar to the one above. Don't forget to call the base class OnCmdMsg if your object doesn't handle the command! Otherwise, none of the other objects in the routing chain will get their crack at the command.
If you've been paying attention, you will have noticed that I didn't have to implement CClock::OnCmdMsg. That's because the implementation CClock inherits from CCmdTarget is just fine. It parses the arguments and looks in the message map to determine if CClock has a handler for the command, and if so, yada yada yada.... In general, unless you're doing something truly funky (it's been known to happen), you never implement OnCmdMsg for your own command targets. Rather, you implement it for some other class to call your class's OnCmdMsg. If you do implement OnCmdMsg for your new class, it's only to pass the arguments to yet other OnCmdMsg functions. Ultimately, every object calls its own base class CCmdTarget::OnCmdMsg, which does the work to send the command to its proper handler function. This very same mechanism also works for ON_COMMAND_UPDATE_UI handlers. So if you want your new command target to check or uncheck, enable or disable, or even change the name of a menu item, you can do it the standard way—by implementing an ON_COMMAND_UP-DATE_UI handler for it. While OnCmdMsg does wonders to make my clock sample an object-oriented app, it's not a completely happy solution for a couple of reasons. First, it requires modifying CMain-Frame::OnCmdMsg. Even if it's only one function with three lines of code, why should the frame have to hook the clock up? To be truly independent, CClock should be able to hook itself up. All the frame should have to do is instantiate the clock as a member and voilà—CClock processes its commands. Unfortunately, there's no way to do it. But you can come close. If you only have a few classes, then I suggest you use the scheme I just described for MYEDIT. But if you're building a big system with lots of command targets that handle their own commands, you might consider a slightly enhanced version of the above, one that uses a list of CCmdTargets stored as a global, or perhaps in the application object. |
|
| The OnCmdMsg function for CCmdTargetList would simply walk the list m_targets, calling each target's OnCmdMsg function. Your main frame would call the global list like so: |
|
|
Or maybe you'd call it from CYourApp::OnCmdMsg.
Either way, once you've set up something like this, any object can hook itself into the command superhighway just by adding itself to the global list of command targets by calling |
|
|
from within its constructor. Likewise, each object could remove itself in its destructor. (Of course, this only works for global objects like CClock; it doesn't work for command targets that logically belong to the document, view, or some other object that has a notion of the current active instance.) The main benefit of the global list is that once you set it up, you don't have to modify CMainFrame every time you add a new kind of command target to your system. New targets can hook themselves up autonomously.
Well, almost. There's still one more little problem to contend with, a perpetual bane for anyone who's ever tried to develop self-contained user interface classes like CClock that can be just plopped into an app: the command ID. Notice that Clock.h #includes Resource.h. That's where the command IDs ID_CLOCK_SET and ID_CLOCK_CHECK are defined. CClock needs these symbols for its message map. Resource IDs are a real pain when you're trying to build truly object-oriented systems because they're effectively a global ID—space that must be known at compile time. It's simply impossible to build a shrinkwrapped CClock for someone else's app because you don't know what values to use for your menu IDs. Whatever values you choose might conflict with values already used in the app. To build truly autonomous command targets, you'd need some sort of mechanism whereby your command target (CClock) could request an unused menu item ID from the app, then dynamically add its commands to the menu using the obtained IDs. Then the message map would use ON_ COMMAND_RANGE with the range from 0 to 0xFFFF (that is, all IDs), and the handler function would check for the actual ID at runtime. All this is, of course, way more trouble than it's worth. Better to simply swallow your OO pride, hardcode the IDs, and #include the darned Resource.h. If I were building CClock as a library for someone else, I would put all my command IDs in a header file, all defined as offsets from some base like ID_CLOCK_COM-MAND_BASE, and the instruction manual would tell the programmer to #define this symbol so as to not conflict with her or his own IDs. One more thing: the routing order is not usually an issue when handling commands since each different class will handle certain commands and no other class will handle those same commands. For example, only the document handles ID_FILE_SAVE, and only the clock handles ID_ CLOCK_SET. However, there are cases when you want more than one class to handle the same command. For example, many classes might want to handle ID_VIEW_ REFRESH for a View | Refresh command that tells each object to update itself. That's why MFC has ON_COMMAND_EX, which lets you return a BOOL to indicate whether MFC should continue routing the command. If your ON_COMMAND_EX handler returns FALSE, OnCmdMsg returns FALSE and the higher-level OnCmdMsg function continues routing the command. But if any handler returns TRUE, c'est finis. In this situation, the routing order may or may not be important. But I guarantee you, if your app depends on the order in which commands are routed, it's way too complicated and you probably need to get some anti-stress pills.
Q I have read in many places, and even seen in one of the Visual C++® tips, that you should always declare a destructor virtual. Why is this so? And if it is true, why doesn't C++ always make the destructor virtual by default?
Kees Vandersen
A I always love these C++ 101 questions; they're so pure. They make me feel like the title of my column is justified, when usually the stuff I write about has nothing to do with C++ per se. Plus, they usually have a definitive answer that doesn't require writing a lot of code. Not that you should feel unschooled or anything; I'm quite sure many experienced C++ programmers could not answer this question correctly.
The destructor should always be declared virtual to avoid the following situation. Suppose you have a base class called Animal. |
|
| Suppose you derive a new class, MadCow, from Animal. |
|
| This makes sense because a MadCow is a kind of Animal. Now suppose somewhere in your code you have some lines like these: |
|
|
Even though pa is declared as Animal*, it's OK to assign a MadCow to it since a MadCow "is a" Animal.
The interesting question is, what happens when you delete pa? Does C++ call the destructor for Animal or for MadCow? The answer is, C++ calls the destructor for Animal because the pointer is declared as Animal*. C++ has no way of knowing that pa is "really" a MadCow. If you don your special decompiler X-Ray goggles and looked at how C++ compiles the delete statement above, you would see it goes like this: |
|
|
So even though pa is really a MadCow, C++ calls the destructor for Animal, bypassing the one for MadCow. If the MadCow constructor creates objects that are destroyed in its destructor, this code would result in a memory leak.
"But wait," I hear you say. "C++ knows pa is a MadCow because I created it as a MadCow!" True, but in general it doesn't. To see this, suppose you decided to violate the rule that every object should be destroyed from the same place it was created and encapsulate the destruction in a function, Exterminate, because you also want to use it for ToxicChickens. |
|
| Now it should be obvious that within the context of the Exterminate function, C++ has no way of knowing whether pa points to a MadCow, a ToxicChicken, or any other kind of Animal—not unless the destructor is virtual. If the destructor is virtual, the delete call compiles to something like this: |
|
|
vtbl is the object's virtual function table, a table of all its virtual functions, and dtor represents the destructor within this table. In general, the whole point of virtual functions is to let you write po->foo and have the compiler call the foo function for whatever kind of object po really is, not the kind of object the pointer po is declared as.
So the general rule of thumb is to always declare your destructor virtual. If you're using MFC, this isn't necessary for objects that derive from CObject since CObject's destructor is already declared virtual. Once a class function is declared virtual, it's virtual in all derived classes too, whether or not you write the virtual keyword. However, it's considered polite to always write virtual before a virtual function's name, even if its virtuality is assured by way of inheritance, in order to remind humans with brains that don't operate as quickly as compilers that the function is virtual. But for some peculiar reason I cannot determine, many programmers, including yours truly, often omit the virtual keyword for destructors. As to why C++ doesn't always make the destructor virtual, the answer is because there are times when you don't want a virtual destructor. Usually it's because you want to keep the object small, or because you want it to match some non-C++ object. Remember, once you add even a single virtual function to a class, objects of that class have a memory representation that carries with it as the first element a pointer to the vtbl. In other words, it's as if the class were declared like so: |
|
|
This not only increases the size of the object (usually by four bytes), it also messes things up if you want your C++ object to exactly match some C struct. A typical case in point is the MFC classes CPoint and CSize, derived from the C structs POINT and SIZE. These tiny objects are only four bytes each (two bytes each for x and y, or cx and cy), so you don't want to double the size by adding a virtual function table. And you do want the memory representations of CPoint and CSize to exactly match those of POINT and SIZE. That's why neither of these classes has a virtual destructor.
Q I encountered a strange (at least for me) behavior from Visual C++ 4.x. In one of my modules, I had a class hierarchy like this: |
|
|
Notice that I have a pure virtual destructor in the CAbstract class. The compiler should have given an error! But the error was reported at link time, not compile time. I wasted a lot of time figuring out that I had declared a pure destructor. Why wasn't the error reported at compile time?
Rajiv Malik
A Well, now we are moving from C++ 101 into the truly ethereal outer twilight of C++. But since I'm on the subject of destructors, why not? The short answer to your question is that the compiler is correct. Amazing! In C++, it is perfectly legal to have a pure destructor. However, if you do, you must define the function. That is, you must implement a function like this:
|
|
|
Now, I know it seems bizarre to implement a pure virtual function because normally when you write "= 0" after a virtual function in order to make it pure, you think of this as setting the vtbl pointer for that function to NULL. But destructors are a special case. You must implement a pure destructor because, even though it's pure, it will be called from the destructor of any class derived from it.
Using the decompiler X-Ray goggles from the previous question, if you peer inside the destructor for CDerived, you'll see it looks like this: |
|
|
This is, after all, how the constructors and destructors of C++ objects get called. In every constructor, C++ compiles a hidden call to the base class constructor as the first line of code. Likewise, every destructor contains a hidden call to the base class destructor as the last line of code. This explains why you got a link error: because the CAbstract constructor is missing. It's exactly as if you declared some function, called it somewhere in your program, but forgot to implement it. The linker reports an error.
If this seems confusing, it is. Pure destructors work differently from other pure virtual functions. For any other kind of function, when you make the function pure by writing |
|
|
you don't implement the function. But for a destructor, you must. Not only that, your implementation will be called. The simple program in Figure 4 illustrates this.
So what exactly is a pure destructor, and why would you want to use one? The only answer I can image is that you may want to make a class abstract, but you have no virtual functions to make pure, so you use the destructor. Personally, I've never seen this, but I suppose it can happen. When you make the destructor pure, the class does in fact become abstract. In other words, you can't create an instance of it; you can only create instances of classes derived from it. But one thing is certain: pure destructors are more useful as C++ Trivial Pursuit subjects than they are for real programming tasks. |
|
|
From the June 1998 issue of Microsoft Systems Journal.