![]()
|
cutting@microsoft.com Download the code (58KB) |
| Dino Esposito |

|
The XML Mission
The Web interface has popularized the Internet because it makes it easy for people to exchange information. First CGI and Perl, then ISAPI, ASP, and server scriptlets have provided the means for sending and receiving data between the client and the server. The data transferred back and forth reside in HTML code pages. HTML pages are the atomic units that glue together the presentation layer and the data.
When you issue a query to a remote database, the server gives you back an HTML page-say, a table of records. The logical data that comprises the recordset has meaning only if you know the data format. It doesn’t come with a "data stylesheet" that defines the information’s layout. In HTML, tags can only be used to describe display features.
XML provides a way of defining structured data that’s independent from the application that reads it. The tags used in XML documents are not predefined. Any descriptive string can be used (as long as it uses the approved character set). Moreover, the data defined by these tags can be displayed in any way you like.
XML adds a new, intermediate level of abstraction between the data source on one hand and the user interface on the other. This layer lets you access cross-platform data from any system that does XML. Since the data is completely separate from the user interface, you can perform client-side processing before displaying the data.
XML is already used internally in a number of commercial products, notably the new version of Microsoft Commerce Server. Flavors of XML also can be found inside Microsoft Office, server scriptlets, Active Channels,™ and Microsoft Internet Explorer. Internet Explorer 4.0 was the first browser to fully support XML, and it offers a powerful COM object to parse and componentize the data stream. A typical and effective use of XML was presented by Joe Graf in the July 1998 issue of MIND.
Although you can use any tag you like to describe your data, it is expected that certain standards or traditions will develop over time. For example, there may be a standard for describing books in print. This will allow users to search across databases for books by a particular author. With current technology, there is no way to distinguish between books about an author versus those by an author.
A universal syntax for describing data also makes it much easier to move data between disparate systems. If you’re designing a system that needs to integrate with the rest of the world, you’ll find XML especially useful.
Channel Definition Format (CDF) and Open Software Distribution (OSD) are XML-based languages meant for
use in specific contexts like Web subscriptions and auto-
update software. Both CDF and OSD were covered in Cutting Edge last year by John P. Grieb (MIND, November and December 1997).
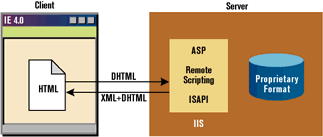
XML also can help if you need to store information for use by your programs. You can create a generic layer of data between a client and a server (see Figure 1). For example, a server can send its data formatted according to the XML syntax so that you can arrange the final output knowing what each chunk of data represents. The same advantage can be gained in reverse, when a client sends information to the server. A server on any platform will be able to parse and store the data.
Another use for XML is configuring programs (see Figure 2). Most of today’s programs need some kind of configuration. It may vary quite a bit from user preferences to program settings, or from state information to internally created documents. XML can do the work with greater flexibility than INI files or registry keys.
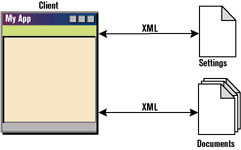
XML can also be used instead of traditional databases to build easy-to-read and easy-to-share systems. Small repositories, user documents, and structures for internal use are all contexts in which XML may be of help (see Figure 3).
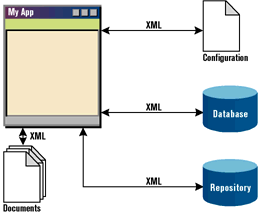
Figure 4 provides a brief list of the pros and cons of XML. One of the major plusses of XML is its intrinsic flexibility. But this doesn’t mean that there are no syntactic rules. Let’s go over a few XML rules. First, each attribute must be enclosed between double or single quotes.
<tag attrib="data">…</tag> <tag>…</tag> <tag1>…<tag2>…</tag2>…</tag1> This is a <tag>.
XML-driven Program Configuration
Most presentations of XML discuss its value solely in terms of the Web. However, its easy-to-read format also makes it adaptable for traditional desktop applications. In the rest of this article, I’ll show you how to take
advantage of XML
to store configuration settings for a Windows-based program. I’ve always been a fan of INI files, and always used them to store the information that my programs rely upon. Sure, the registry is "in," and INI files are "out," but sometimes it’s still easier to pop a couple of values in an INI file where users can quickly get to them and transport them across machines. INI files, however, are flat files. While
it’s possible to store structured data in an INI file, the work is up to you.
The registry, in contrast, is a generic hierarchical repository for any kind of data. It does have certain advantages, like allowing a program to handle multiple users without additional work. But it’s not a simple text file. Let’s see how XML helped me write a program whose behavior is coded once, but whose user interface and data can change. New behavior is often needed when data changes, but thanks to XML’s flexibility there’s no need to update the code.
XML Explorer
This month’s sample source program is a Visual Basic-based application called XML Explorer. It was built using the Visual Basic 5.0 AppWizard, and employs an interface much like that used by Windows Explorer. When started, it reads a template file that tells it how to fill the left-hand tree view pane, where to search for document files, and how to display them.
This program's interface is data-driven, but the behavior is always the same. As you'll soon see, when you change the underlying XML templates, it will appear to be two
different applications. Figure 5 shows the demo program running one of the
predefined templates. As you can see, I
endeavored to give the program a compelling user interface.
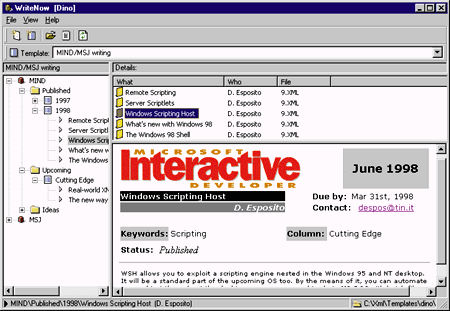 |
| Figure 5: XML Explorer in Action |
|
The idea behind my XML Explorer program is the same idea that makes, for example, Microsoft Transaction Server (MTS) Explorer work as a particular instance of Microsoft Management Console (MMC). Both provide a common layer of code that is customized to some extent by added modules. In the case of MTS Explorer, things are a bit more complex since you have to write a snap-in module made up of several COM interfaces in order to communicate with and extend the MMC. For XML Explorer, it is sufficient to use an XML file to completely change the program's user interface, while the global behavior of the program remains unchanged.
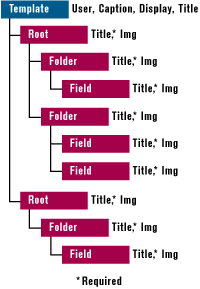
The XML Explorer client area is divided into three panes: a tree view, a report list view, and a WebBrowser control. The tree view delineates a kind of hierarchical repository with multiple root nodes and two additional levels called folder and field. Both the icons displayed and the names used may be decided at runtime by reading from an XML template file. The caption of the window may be set from the template, too. Figure 6 shows the XML template file that renders the structure depicted in Figure 5. This template lets me store information about my MIND and MSJ articles.
I've designed the structure so that these three levels of depth are necessary and only the <field> tags can define actual information as the leaves of the tree. The whole collection of nodes defines the namespace of the application. When you change the namespace (via a new template file), you change the application. Each node may use a varying number of the attributes, as depicted in Figure 7. The XML Explorer core application provides a default value for nodes. |
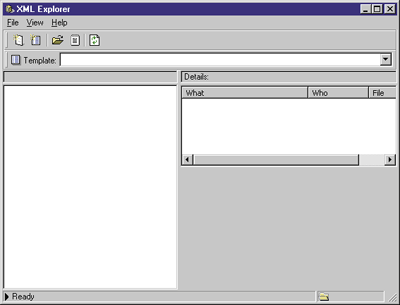 |
| Figure 8: XML Explorer Without a Template |
How XML Explorer Treats Documents
|
|
|
The information section (marked by an <info> tag) contains the records that describe the items defined in the XML file. A <record> tag marks the description of each item—be it an article idea, a memo, a to-do list, or other type. A single XML file can include multiple <record> tags, making it a kind of database (see Figure 12).
All of the records in an XML file share the same link information. Each record in this file has two required attributes, called What and Who. They are concatenated and displayed in the tree view, and also form the rows in the report list view shown in Figure 5. In Figure 12, the records are depicted by the turquoise blocks that replace the "Free Tags" blocks of the tree. |
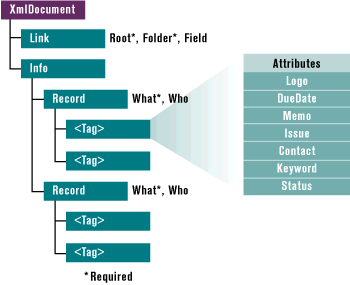 |
| Figure 12: Record Tags |
|
I've filled in the tree view with the available folders, and I've filled in the report list view with the current folder's records. I have the name of an XML file and a reference to a given record inside it. The next step is figuring out a creative way to render the XML data stream for the user.
HTML is a great language for presenting data. As mentioned earlier, the lower portion of the right pane in XML Explorer is a WebBrowser control, so displaying an HTML page is no problem. I decided to associate each template (and hence, each namespace) with a fixed layout for displaying data. The template's display attribute is the name of an HTML file to be displayed by the WebBrowser. This file will initially contain every object that does not need to be replaced when a given record is displayed. These mostly consist of images, separators, and labels. The file also will include placeholders for the specific record tags. Once you've created a new namespace (that is, a new, custom collection of folders and record descriptions), it's easy to produce an HTML file that can be used to display the information. All you need is a way for the program to associate each tag with a given HTML element. In other words, you need a way to tell the WebBrowser control to fill specific fields with specific record content. Basically, there are two solutions. The first one involves the creation of a new, temporary HTML page that uses the first one as a template. This is the typical approach of most existing CGI applications. A better approach is to use Dynamic HTML (DHTML)to update the page being viewed. Linking the existing HTML fields with the record information can be done via the tag ID. DHTML lets you assign a string ID to any tag, be it visual such as <A> or <IMG> or nonvisual like <DIV> or <SPAN>. The idea is to arrange an HTML layout where many of the tags have IDs whose names match the XML tags.
The Default DHTML Layout
|
|
|
but if the type is, say, img, then it sets the src property of the underlying <IMG> tag. If the type is email, the href property will be prefixed with "mailto:"
|
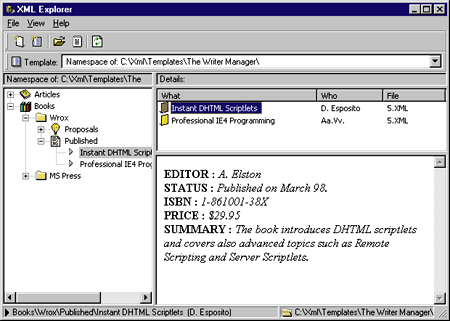 |
| Figure 16: Default Layout View |
| Figure 16 illustrates what happens in the absence of a custom layout for the view. In this case, the document is formatted dynamically: |
|
|
The resulting string overwrites the body of the existing document, no matter what the record's tags are. If you realize that you forgot an important tag, just add it to the XML file and press F5 to refresh the view.
The MSXML Component
|
|
| The XML object then exposes a hierarchy of items that fully describe the content of the XML document. Traditionally, the XML file is rendered as a tree, where each subtree corresponds to a browsable collection. The main node is accessed via |
|
| while each subsequent node, say the nth, is given by |
|
| Alternatively, you can get a reference to a given tag by name: |
|
|
For a complete reference for this component, refer to the article by Joe Graf in the July 1998 issue of MIND, or to the Internet Client SDK.
A Quick XML Viewer
|
|
|
While it succeeds in scanning all the nodes, it fails to enumerate the attributes since they're not available as a collection. Figure 17 shows how it handles one of the demo channel files (color.cdf) provided with the Internet Client SDK.
|
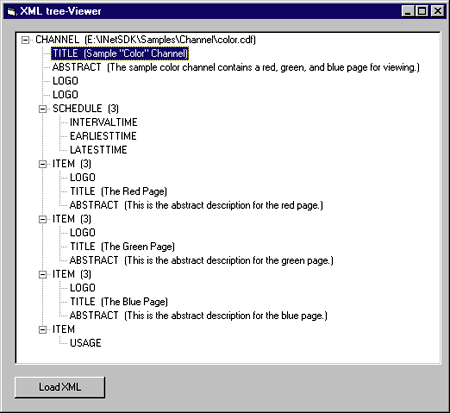 |
| Figure 17: XML Tree Viewer |
|
I attempted to load the code from the XML-based server scriptlet presented in the May 1998 Cutting Edge column, but I encountered some errors! These errors had two main causes. While it is a commonly accepted practice for a server scriptlet to omit quotes when specifying the value of an attribute, leaving out quotes when parsing with MSXML produces an error. Second, the presence of a < sign in a <script> tag is a source of confusion for the parser.
Using XML Explorer
|
|
| The file view.htm is the HTML layout for presenting information. Since the information is mostly about articles, typical fields would include the title, author, summary, and so on. Here's an example: |
|
| Figure 18 shows the same application discussed previously with this completely different data set. |
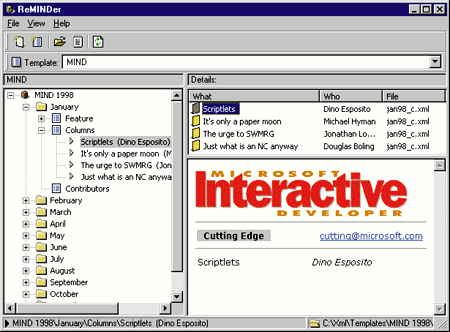 |
| Figure 18: Another View of XML Explorer |
|
Summary
|
From the September 1998 issue of Microsoft Interactive Developer.