June 1998
![]()

Download Jun98hoodcode.exe (1KB)
| Matt Pietrek does advanced research for the NuMega Labs of Compuware Corporation, and is the author of several books. His Web site at http://www.tiac.net/users/mpietrek has a FAQ page and information on previous columns and articles. |
|
Apparently, there's quite a bit more interest in
Win32® assembly language than I had originally
thought. After the February 1998 issue of MSJ hit the stands, I received quite a bit of positive email and favorable comments from folks at trade shows. Many readers said, "Have you also thought about covering...?"
My February 1998 column could have been called "Just Enough Assembly Language to Get By." Since it was such a hit, it's time for the sequel: "Just Enough Assembly Language to Get By, Part II." I'll look at additional instructions and instruction sequences that come up often. I'll also describe some of the most common scenarios when an instruction faults, and what to look for. Before JMPing into the details, make sure you're at least familiar with the Intel x86 registers and instruction addressing modes. I covered both subjects in my February column. Also note that none of the instructions mentioned in my February column—and none of the ones I'll mention here—require anything more than an 80386 system because the subset of instructions that compilers typically use was standardized at least 12 years ago. Common Instructions Instructions INC value, DEC valueThe INC and DEC instructions are used to increment and decrement values kept in memory or registers. As you might imagine, these instructions map precisely to the ++ and - - operators in C++ for standard integer operations. You could use the ADD or SUB instructions to achieve the same effect as INC and DEC, although it would be more expensive in terms of size. Since they are so commonly used, the smallest versions of the INC/DEC instructions take only a single byte. Looking at the Intel opcode map, you'll see that there's an opcode for each of the eight general-purpose registers that INC can be used against (EAX, EBX, ECX, EDX, ESI, EDI, ESP, and EBP). Another eight opcodes are used for the DEC instruction and the same set of registers. Instructions MUL value, value DIV value, valueI didn't cover the ADD and SUB instructions in my February column since their operation is straightforward. However, the MUL and DIV instructions have some quirks that make them difficult to read and downright quirky to write. Throughout this column, when I mention (E)AX, I'm referring to AL, AX, or EAX. Likewise, when I mention (E)DX, I'm referring to DL, DX, or EDX. Both MUL and DIV treat their operands as unsigned values. The operands can't be immediate values (such as 3); rather, they must be in registers or memory. You may have noticed that the destination value (the first argument) always seems to be (E)AX. This is by design. The use of the (E)AX register is an implicit part of the instruction. Beyond the implicit use of (E)AX, the (E)DX register is also silently involved. The high bits of the MUL instruction end up in (E)DX. Likewise, for the DIV instruction, E(DX) holds the remainder and (E)AX holds the quotient. If you write any assembler code, MUL and DIV get even weirder. The assembler (both MASM and the Visual C++® inline assembler) won't let you specify the (E)AX operand. Thus, if you want the instruction MUL EAX,ECX, you would write MUL ECX—just another example of the intuitive language syntax that's made assembly language wildly popular in recent years. Instructions IMUL value, value IDIV value, valueThe IMUL and IDIV instructions treat the operands as signed values. Contrast this to MUL and DIV, which work on unsigned values. IDIV uses (E)AX as the implicit first operand, just as DIV does. Also, like its DIV counterpart, IDIV only works with register or memory values. IMUL, on the other hand, doesn't fit the general patterns of MUL, DIV, and IDIV. It can work with immediate values and it can have a non-(E)AX register as the destination. There's even a form of the IMUL instruction that takes three operands. To my knowledge, this is the only instruction in the Intel opcode set with this distinction. Instructions PUSHAD, POPADPUSHAD and POPAD push or pop EAX, ECX, EDX, EBX, ESP, EBP, ESI, and EDI on the stack, in that order. These instructions are used in situations where many registers may be modified and the programmer wants to leave no evidence of the execution in the code. Although interrupt handlers are passé for most programmers, they're a perfect example of where PUSHAD and POPAD come in handy. Besides taking fewer opcodes than eight individual PUSH instructions, they also execute faster (five clock cycles on a Pentium). Instructions PUSHFD, POPFDIn some cases, it's inconvenient to use the flags set by a prior operation immediately. Alternatively, you may want to make sure that some operation you're about to execute won't change the current flag values. For these situations, PUSHFD and POPFD are the easiest methods to save and restore those bits. PUSHFD is one of the atomic components of an interrupt. When an interrupt or an exception occurs, the following code effectively executes: Instructions SHL, SHR, SHLD, SHRDThe SHL and SHR instructions are logically equivalent to the C++ << and >> operators. Many of you probably recall that bitwise shifting is a quick way to perform multiplication and division by powers of 2. For example, the SHL EBX,3 instruction has the same effect as multiplying EBX by 8 (23 == 8). Indeed, if you write C++ code that multiplies or divides an unsigned value by 2, 4, 8, 16, and so on, it will most likely compile to a SHL instruction. When shifting left, the low-order bits are filled with zeroes. The final high-order bit that's "shifted out" is moved to the carry flag (CF). In other words, the carry flag is like a virtual 33rd bit. When shifting right, the high-order bits are filled with zeroes, and the last bit shifted out moves to the carry flag. Instruction ADD [EAX],ALYou may see a lot of this particular instruction, and you'll probably see it repeated. However, ADD[EAX], AL has no special significance. The opcode bytes for this instruction are 00 00. In other words, it's what you'll see if you're viewing a series of data bytes that all contain the value 0. Nothing to see here. You can all go home now. Instruction CLDIn my February 1998 column, I described the string instructions LODSx, SCASx, STOSx, and MOVSx. Each of these instructions uses the ESI or EDI register to point at the memory to be read or written to. These instructions are typically used in conjunction with the REP, REPE, or REPNE prefixes, which cause the string instruction to execute several times until some specific condition is met. After each REPx-induced iteration, the CPU changes the ESI or EDI register to point to an adjacent memory location. The direction in which the registers move is given by the direction flag. If the direction flag is clear, ESI or EDI is incremented after each instruction (thus causing the next higher memory location to be referenced in the next iteration). When the direction flag is set, ESI or EDI decrements after each iteration. Most of the time it's easiest to work moving forward in memory (toward higher addresses) so that the direction flag is usually clear. However, it's generally not safe to assume that the flag is clear. Thus, you'll often see the CLD instruction somewhere before a string operation such as REP MOVSB. Instructions NOT value, NEG valueThe NOT instruction does ones-complement negation. That is, it applies the NOT operation to each bit in the operand. An initial value of 0 will become 0xFFFFFFFF after a NOT instruction. The C++ ~ operator is typically implemented via the NOT instruction. The NEG instruction does twos-complement negation. (If you're not 100 percent up on ones versus twos-complement negation, don't feel bad. I learned this stuff 10 years ago in college, and I've completely forgotten it!) An easier way to think of the NEG instruction is that it puts a - sign in front of the value. Thus, using NEG on -3 yields 3, while NEG applied to 4 yields -4. To summarize, you can think of NOT as affecting individual bits, while NEG operates on the entire value. Instruction NOPThe NOP instruction does nothing and affects nothing. It's a single-byte opcode that executes in one clock cycle and is primarily used to pad code. For example, a compiler might want the beginning of a procedure to start on a 16- byte boundary. The compiler/linker would insert enough NOP instructions between the end of one procedure and the beginning of the next procedure to create the desired alignment. If you're confident in your assembler abilities, the NOP instruction can be applied to code in memory or in the executable file. You might know that some instruction you're about to execute will cause a fault in a debugger. If you want to skip that instruction, use the debugger to write enough NOP opcodes (0x90) to eliminate the instruction. This is useful to squash hardcoded INT 3 breakpoint instructions while you're running under the debugger, effectively not stopping at the breakpoint. Really advanced users can implement NOP instructions to obliterate entire regions of code in an executable. (Warning! Harder than it looks.) Another advanced use of the NOP instruction is when you want to make it easy to patch or hook into your code. At the beginning of a procedure or block of code, put in enough NOP instructions for the desired goal. Subsequent patching or hooking code can write JMPs, CALLs, or whatever into the NOP area. Instruction INT 3INT 3 has two uses—one intended by the original CPU designers, the other accidental. The INT 3 instruction is the standard method to suspend a program and transfer control to a debugger. In normal use, programs don't include INT 3 instructions in their code. Rather, when you set a traditional breakpoint with a debugger, it temporarily overwrites the target instruction with an INT 3 instruction. (The LODPRF32 program from my July 1995 column illustrates this.) Note that an INT 3 instruction is the heart of the DebugBreak API for Intel CPUs. The other offbeat use of the INT 3 instruction is as a paranoid NOP. In those cases where a NOP would be used for padding (and theoretically never executed), an INT 3 can be used instead. Like NOP, an INT 3 instruction is only a single byte. The key difference is that if a bug crept in and you executed the INT 3 instruction, you'd pop into the debugger. In the same scenario, the CPU would blithely sail through NOP instructions and wreak havoc someplace farther away from the original error. The Microsoft® linker uses INT 3s as paranoid NOPs when creating padding for incremental linking. The linker also uses them as padding between procedures it wants to align on a particular memory boundary. Usually this alignment is on a multiple of 16 bytes unless you have the "optimize for size" compiler option set. Figure 1 shows a section of code from CALC.EXE that illustrates INT 3 padding in action. Instruction LOCKTechnically speaking, LOCK is an instruction prefix rather than an instruction in its own right. In a multiprocessor environment, multiple processors could access the same memory location at the same time. The LOCK prefix insures that the instruction associated with it will have exclusive access to the destination memory location. If you've ever examined the EnterCriticalSection API, you'll see that if the critical section isn't currently held, the code essentially just increments a counter. A LOCK prefix is used with an INC instruction to guarantee that one thread won't increment the counter while another thread on another CPU is reading it. You'll also see the LOCK instruction used with multiprocessor synchronization APIs such as InterlockedExchange and InterlockedIncrement. A final thought on the LOCK prefix: you may recall a bug on older Pentium CPUs where a particular instruction sequence could cause the CPU to freeze up. (See the February 1998 Editor's Note if you need a refresher.) That instruction sequence isn't a valid sequence, and the LOCK prefix plays a vital role in the ensuing CPU meltdown. Common Instruction Sequences Sequence CMP register_X, immediate_value_AThis sequence (compare and JMP if equal) is the most straightforward encoding of a C++ switch statement that I've seen. It's also very easy to pick out when you encounter it in a debugger. In the example code, the switch statement would look something like this: |
|
|
The trick to understanding this code sequence is realizing that compiler-generated code for switch statements usually differs from your mental model. The code for all the case comparisons is usually generated in one place. Following the value comparison code are discrete blobs of code that implement the code specified for a particular case. The value comparison code is optimized to quickly figure out just which case blob to jump to.
By no means is this sequence the only encoding for switch statements. More efficient encodings may involve JMP tables or subtractive countdowns using the zero flag. However, these encodings definitely don't fit into my criteria of "just enough to get by." Sequence opcode [register+offset]Here's a common scenario: you have a pointer to a structure or class instance with which you read, write, or otherwise manipulate some field. In this situation, the compiler typically puts the pointer value into a register. The offset of the specified field within the structure is then added to the register. For instance, consider this structure: |
|
| If you had a pointer to an instance of this structure and wanted to add 2 to each structure member, the code would look something like this (assuming ESI points to the structure instance): |
|
|
Note that for the first structure field (i ), the field offset is 0, so no addition is needed. The i field is 4 bytes long, placing the next field (j) at offset 4. The j field is a short, so it's only two bytes long. The final field (k) is at offset 6, which I arrived at by adding 4 and 2.
Compilers must place structure fields into memory locations in exactly the same sequence as the structure is declared. Thus, you can usually look at any structure or class definition and figure out the offsets of various fields. Be aware that compilers often place padding between structure fields so that each field starts at some natural boundary (typically 4 or 8 bytes). Using #pragma pack lets you specify the exact padding (or lack thereof) in your structure definitions. Sequence MOV value,EAX, many times in a rowWhen a collection of variables is assigned the same value, the compiler may load the value into a register and copy the register into each of the variables. For example, at the beginning of a function you might initialize several int variables to the value 0. The example code sequence shows one way this might be encoded. Sequence CMP register_X,01In many cases, generated code needs to inspect a value to determine if it's 0. If so, the result of the inspection should be nonzero (typically 1). If the input value is any value other than 0, the result should be 0. Using 0 to mean Boolean FALSE, and everything else being TRUE, this instruction sequence does a logical NOT of the input value. The code comprising this instruction sequence certainly isn't intuitive. Its distinctive characteristic is the use of the SBB instruction (integer subtraction with borrow). SBB is rarely used outside of this sequence. The first instruction (CMP) sets or clears the carry flag as appropriate. SBB then uses the carry flag as part of its subtraction. Since the two arguments to SBB in this sequence are always the same, the carry flag alone determines the outcome (which is always 0 or -1). The NEG instruction finishes up by changing a -1 to a 1 and leaving 0 values alone.
Oops! How did I Get Here?
|
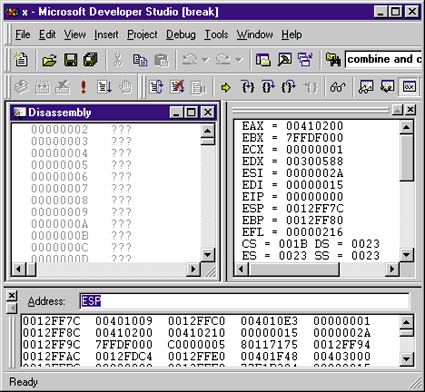 |
| Figure 2 A NULL Pointer Fault |
|
Incidentally, if the DWORD at ESP doesn't turn out to be a valid return address, it's certainly worth your while to look further up on the stack for values that look like they could be return addresses. If something looks like a valid address, change the code window to display at that address and see if you can make sense of it. If your ESP register is bogus, try looking for return addresses at positive offsets from the EBP register. Remember, this isn't an exact science. You're sifting through the rubble, looking for something that will give you a clue as to where you'll start doing more in-depth investigation.
Moving away from NULL function pointers, let's say you've faulted in some code that you don't recognize, but the faulting address is nowhere near 0. What's worse, the code looks like garbage. In other words, it doesn't look like the normal instructions you'd see. Instead, you see instructions such as ARPL, AAA, and OUTSB. There are two likely ways your code got there. First, you may have called through a corrupted function pointer. Second, you may have corrupted the return address on the stack. When the RET instruction executed, control transferred to the bogus address. In either situation, the underlying problem is valid code addresses that were overwritten with garbage. In this case, your chance of getting a valid return address is lessened. However, you may be able to get an idea of what happened by looking at the faulting address. Try interpreting the fault address as a stream of data—you may find a pattern. Figure 3 shows the code for a small Hello World program with a big bug. The szBuffer array is only four characters wide, while the strcpy function copies the whole 13 bytes of "Hello World!" This buffer overrun actually overwrites the stack frame where function main's return address is stored. When I run the program, it correctly prints out "Hello World!," but then faults at address 0x21646C72. The faulting address yields a clue if you think of the address as a pattern of bytes. In memory, 0x21646C72 is stored as four sequential bytes: 0x72, 0x6C, 0x64, and 0x21. Note that each of these values is above 0x20, and below 0x80. That happens to be the range of printable ASCII characters. Looking up the four bytes in an ASCII table, you get |
|
|
As you can see, those four bytes form the end of the string "Hello World!" You could then search your code for places where rld! appears. While not a perfect answer, you'll have substantially narrowed down the places to begin an initial search for the problem. Admittedly, this is a contrived example and there are tools available that find these types of memory overwrites. Nonetheless, I've found many obnoxiously difficult bugs only because I noticed a familiar pattern in the corrupted data.
Other Common Causes of Faults
|
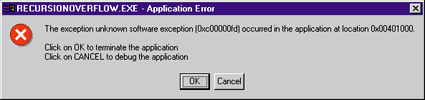 |
| Figure 6 An Unhelpful Fault Dialog |
|
If you select Cancel to debug, the Visual Studio debugger briefly tells you that a stack overflow occurred, but not at the same time as it shows you the faulting instruction. However, there are clues you can infer from the debugger that would indicate a stack overflow. For starters, the ESP register value is probably on a 4KB boundary. Likewise, the faulting instruction is probably a PUSH. There are other ways to cause a stack fault, but most of the time it will look something like what I've described.
While I'm on the subject of the stack, my final tidbit this month is on problems caused by PUSHing or POPing too much data to or from the stack. When whole programs were written in assembly language, programmers spent a lot of time matching up every PUSH instruction with an equivalent POP or ADD ESP,XX instruction. However, since compilers are so widespread, this tedious process isn't normally necessary. Believe it or not, it's still sometimes necessary to verify that what's pushed on the stack eventually gets removed. For example, if the code for calling a __stdcall function places two DWORD values on the stack, the called function should end with a RET 8 instruction. Likewise, if you see a __cdecl function being called with three DWORD parameters, there should be an ADD ESP,0Ch instruction following the call. More importantly, the called function should return with a simple RET instruction. If you're not familiar with __cdecl versus __stdcall functions, see my February 1998 column. These kinds of stack parameter mismatch problems can be minimized by following a few simple rules. First, make sure that there's only one prototype for any given function. Put that prototype in a .H file, never in a .C or .CPP file. Finally, make sure that the source file that actually defines the function includes the .H file. If you follow all these steps, you'll get a compiler or linker error rather than a bogus program. I've seen programmers cheat by including prototypes for just one or two functions in their code modules. (You know who you are!) These functions have a prototype in a .H file, but the programmer doesn't want to incur the overhead of bringing in a whole .H file for just a few items. Inevitably something changes and the programmer ends up counting PUSHs, POPs, and ADD ESPs because the code crashes.
Wrap-up
Have a question about programming in Windows? Send it to Matt at mpietrek@tiac.com. From the June 1998 issue of Microsoft Systems Journal.
|