November 1998
![]()
Supporting Multilanguage Text Layout and Complex Scripts with Windows NT 5.0
Download Nov98MTLCS.exe (629KB)
The three authors of this article work in the Windows Operating System division International group at Microsoft. F. Avery Bishop is an evangelist for international software development. David C. Brown is the architect of Uniscribe. David M. Meltzer manages the OpenType specification and related developer resources.
|
All international versions of Windows NT® 5.0, from Japanese to Hebrew, are based on the same binary files. In addition, Microsoft has created new services for text layout that support a wide range of languages. By internationalizing the Windows® text layout interfaces, Microsoft has made it easier to develop applications that can lay out text for almost any language.
For developers of global applications, the shift to a single worldwide binary strategy is welcome news; different localized versions of an application can now be developed under a single Windows NT 5.0-based system. That is, for most applications you won't have to switch from one localized system to another during development (although you should certainly test on each targeted platform before release). In this article, we'll explore techniques for developing applications that handle multilingual text and complex scripts. We'll introduce Uniscribe, the Windows Unicode script processor, which comes with Windows NT 5.0. This article also will cover existing interfaces that Microsoft has extended to meet the requirements of complex text layout.
Multilingual Features in Windows NT 5.0
Characteristics of Complex Scripts
The OpenType Font Format
Multilingual Input
|
|
|
|
|
| Each time the callback function is called, it builds a string containing the typeface name and the language name, and adds that string to the listbox in a dialog box.
As you can see from the sample code in Figure 1, Indic scripts must be handled separately because they have no charset values. Since there is no default ACP value for Indic scripts, none of the Win32® ANSI entry points (the A routines) will work with Indic text. Indic text is not automatically translated to Unicode. There are ways to force translation of Indic text to or from Unicode using MultiByteToWideChar and WideCharToMultiByte by specifying the appropriate code page. However, an Indic input locale can only pass Indic text to a Unicode application, so full support for Indic scripts requires a Unicode application.
Doing Text Layout Using Win32 APIs
Many applications deal mostly in plain text—text that is all in the same typeface, weight, color, and so on. Such applications have traditionally displayed text using standard Win32 display entry points (TextOut, ExtTextOut, TabbedTextOut, and DrawText) to write text to a window, and the GetTextExtent family of functions to measure line lengths. As you'll see later, Uniscribe provides ScriptString APIs for better plain text processing on Windows NT 5.0 and Windows 9x. There is good news for existing applications that use the standard Win32 API for plain text processing; it just works! In Windows NT 5.0, the standard entry points have been extended to support display of complex scripts and, through the font fallback mechanisms mentioned earlier, multilingual Unicode text. In general, this support is transparent to the application itself, so properly designed applications require no changes to support complex scripts through these interfaces. There are two requirements for displaying complex scripts correctly using the standard Win32-based applications. First, applications should save characters in a buffer and display the whole line of text at once rather than, for example, calling ExtTextOut on each character as it is typed in by the user. When characters are written out one by one, the complex script shaping modules cannot determine the context for correct reordering and glyph shaping. Second, applications should use one of the GetTextExtentXxx functions to determine line length rather than computing line lengths from cached character widths. This is because the width of a glyph used to display a character may vary by context. In addition, complex script-aware applications should consider adding support for right-to-left reading order and right alignment to their applications. You can toggle the reading order or alignment between left and right with the code shown in Figure 2. Of course, you can toggle both attributes at once, as Notepad does, by executing the following statement: |
|
| Follow this by the calls to SetTextAlign and ExtTextOut as shown in Figure 2.
Standard Edit Control
|
|
| After setting the lAlign value, enable the new display by setting the extended style of the edit control window as follows: |
|
| One new feature of the standard edit control is a context menu that allows the user to toggle the reading order and insert/display Unicode bidirectional control characters (see Figure 3). |
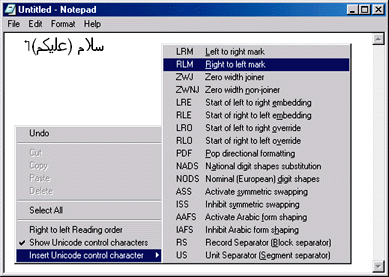 |
| Figure 3 Edit Control Context Menu |
|
RichEdit Control
Uniscribe
Problems with Common Text-layout Methods
Formatting Paragraphs in the Sample Application
Shaping Engines and Font Association
Shaping Functions
|
|
| Applications may use these properties to help combine their own layout rules with the required shaping engine divisions.
All the complex script shaping engines, the digit shaping engines, the punctuation and ASCII shaping engines validate the font in the hdc before shaping, and will return HRESULT USP_E_SCRIPT_NOT_IN_FONT if the font does not contain sufficient glyphs and/or shaping tables. Only scripts that have the property fComplex should be shaped with the script returned by ScriptItemize. All other runs may be merged and shaped with SCRIPT_UNDEFINED. If there are characters not supported by the font, SCRIPT_UNDEFINED will not fail with USP_E_SCRIPT_ NOT_IN_FONT. Missing glyphs will usually be displayed as an empty rectangle. An application can determine if a codepoint is supported by a font by calling ScriptGetFontProperties to obtain the default glyph index, and ScriptGetCMap to look up font glyphs for Unicode codepoints.
The Unicode Bidirectional Algorithm
Experimenting with the Sample App
Caret Placement and Hit Testing
Digit Shape Selection
Caching
Symbol and Device Fonts
Supporting Multilingual and Complex Scripts
|
|
| In this example, the application actually calls MessageBoxW if you compile your source code with the –DUNICODE switch; otherwise it calls MessageBoxA. Text strings passed to or from these entry points all have the LPCTSTR or LPTSTR data types, which are typedefed as unsigned short if the symbol UNICODE is defined, and char otherwise. Unicode applications (those that call the W interfaces) get all characters and strings from the system as Unicode, whereas ANSI applications (users of the A routines) get text encoded in the ACP. It's important to keep in mind that this applies not only to the arguments of the Win32 entry points, but to all text passed to or from the application. For example, window messages such as WM_CHAR, WM_GETTEXT, and WM_SETTEXT that pass text in the wParam or lParam parameters also use Unicode or ANSI, depending on the type of application.
With this in mind, how can you encode text in Unicode and run on all Win32-based platforms? Strategy 1 Always run as a pure Unicode application. Compile the application with the –DUNICODE switch so that you use only the W entry points. All text passed to and from the application is in Unicode. This is the easiest to program by far. It also supports all Indic scripts and all new script added to Windows NT in the future. However, the application will not run on Windows 95 or Windows 98. This is the best approach if your application is targeted for Windows NT only, as is the case for many in-house or vertical applications. Strategy 2 Create two binaries, one for Windows NT using Unicode and one for Windows 95 and Windows 98 using ANSI. Use LPTSTR for pointers to string buffers, TCHAR for characters, and so on. Use –DUNICODE to compile the Windows NT version only. This strategy is easy to program in its simplest form, and covers Windows 95, Windows 98, and Windows NT. Unfortunately, the ANSI version is basically restricted to the Win32 API standard calls. Localization, distribution, and maintenance of two binaries is difficult. Only recommended for simple or special in-house applications. Strategy 3 Always run as an ANSI application, but use Unicode internally. This is the strategy used by the CSSamp sample code. The source code is compiled as an ANSI application, which receives text from the keyboard through the WM_CHAR or WM_IME_CHAR messages in the codepage of the current input locale. In general, this is not the same as the ACP. The application converts text to Unicode using the codepage of the current input locale. If the input locale changes in the middle of a string, the application will have to concatenate strings converted from different codepages. With this strategy, the same binary runs on Windows NT, Windows 95, and Windows 98, and it supports nearly all of the scripts in Unicode. On the other hand, it's somewhat more difficult to program than the pure Unicode approach. Also, it does not support scripts without an ACP, such as Indic scripts, even when running on Windows NT. This is a sound approach if your application must run on Windows 95 and Windows 98 and does not need to support Indic scripts and others without an ACP. Strategy 4 Detect the system and explicitly call the W APIs for Windows NT and the A routines for Windows 95 and Windows 98. The application registers itself as a Unicode application on Windows NT and as an ANSI application on Windows 95 and Windows 98. The easiest way to implement this approach is to write a set of functions, say U routines, that parallel the Win32 W and A routines. Your application first calls GetVersionEx to detect the system, and stores that information into a global variable: |
|
| Each U interface looks just like the corresponding W interface. For example, the prototype for CreateWindowExU would be: |
|
| You can implement CreateWindowExU as a function pointer. When the app is launched, your initialization code checks to see if g_IsWindowsNT is TRUE, and if s, sets CreateWindowExU equal to CreateWindowExW. Otherwise (that is, when running on Windows 95 or Windows 98), CreateWindowExU is set to a routine you write yourself, say CreateWindowsExAU. This routine converts lpClassName and lpWindowName to the ACP using WideCharToMultiByte, and passes those parameters along with everything else to CreateWindowExA.
This approach also requires special handlers for messages such as WM_CHAR and WM_GETTEXT to convert the text passed in the wParam or lParam parameters to or from Unicode when g_IsWindowsNT is false. In the case of WM_CHAR and WM_IME_CHAR when running on Windows 95 and Windows 98, the application will also have to build up the Unicode string from multiple conversions via MultiByteToWideChar if the user switches input locales while typing in text. This strategy runs on all platforms with the same binary files. It supports all scripts when running on Windows NT, including Indic, and allows use of Uniscribe on all platforms. The only disadvantage to this approach is that it requires considerable development investment. This strategy is your best choice for any application that needs to run on Windows 95 and Windows 98 and needs universal support for all scripts on Windows NT.
Summary
See the Glossary of terms for Supporting Multilanguage Text Layout and Complex Scripts with Windows NT 5.0. From the November 1998 issue of Microsoft Systems Journal.
|