November 1998
![]()
A File System for the 21st Century: Previewing the Windows NT 5.0 File System
Download Nov98NTFS.exe (5KB)
Jeffrey Richter wrote Advanced Windows, Third Edition (Microsoft Press, 1997) and Windows 95: A Developer’s Guide (M&T Books, 1995). Jeff can be reached atwww.JeffreyRichter.com.
Luis Felipe Cabrera is an architect in the Windows NT Base Development group at Microsoft. His responsibilities are in
Windows NT 5.0 storage management.
|
Many of your
programming tasks will be simplified when you take advantage of the new innovations in the Windows NT® 5.0 file system (NTFS). Let's go on a whirlwind tour of the Se new features. Remember, we are discussing software that is in beta, so everything is subject to change. Please check Microsoft's most recent documentation before writing any code based on this information.
Let's begin with an overview of the NTFS file system layout on disk. While this information is programmatically off-limits to the application developer, a high-level explanation will make it much easier for you to understand many of the new NTFS features. At the heart of the NTFS file system is a special file called the master file table (MFT). This file is created when you format a volume for NTFS. The MFT consists of an array of 1KB entries; each entry identifies a single file on the volume. When you create a file, NTFS must first locate an empty entry within the MFT array (growing the array if necessary); then it fills the 1KB entry with information about the file. A file's information consists of a collection of attributes. Figure 1 shows a list of standard attributes that can be associated with a single file (or directory). When a file is created, the system creates the set of attributes for the MFT's file entry and attempts to place the M inside the 1KB block. But there are two problems: most attributes are variable length, and many attributes (like Name, Data, and Named Data) can be much larger than 1KB. So NTFS can't just simply throw all the attributes inside an MFT entry. Instead, NTFS must examine the attributes; if the length of an attribute's value is small, the attribute's value is placed inside the MFT entry. This is called a resident attribute. If the attribute's value is large, then the system places the attribute value in another location on the disk (making this a nonresident attribute), and simply places a pointer to the attribute's value inside the MFT entry. Today, everybody has lots and lots of small files stored throughout their hard drives. We all have lots of shortcut (.LNK) files and probably lots of DESKTOP.INI files sprinkled around. Because of the way that NTFS stores attributes in an MFT entry, it is possible for all of the attributes of a single file, including its Data attribute, to be resident. This greatly improves performance when accessing small files. In addition, NTFS also stores the most common attributes of a file in the directory entry that represents the file. This means that when the system does a FindFirstFile/FindNextFile operation to retrieve a file's name or basic attributes, the data for the Se attributes is found in the directory entry, so no other disk access is needed. Prior to Windows NT 4.0, an MFT entry in NTFS was 4KB in size. This, of course, allowed files with slightly more data to have their data resident. In Windows NT 4.0, Microsoft pared the size of an MFT entry to 1KB. Microsoft studied the number of files and their sizes on many typical systems and saw that NTFS was wasting a lot of space in MFT entries and that it would be more efficient to make the MFT entry 1KB. Now let's go over some of the features offered by NTFS that software developers can (and should) take advantage of.
Streams
|
|
|
When you execute this command, the system creates a file called XX.TXT. This file contains two streams: an unnamed stream that contains 0 bytes and a named stream (called MyStream) that contains the text "Hi Reader". If you haven't guessed by now, you access a file's named stream by placing a colon after the file name followed by the name of the stream. As with file names, Win32® functions treat stream names as case-preserved and searches are case- insensitive.
Unfortunately, the tools supplied with the system treat streams as second class citizens at best. For example, execute the following command: |
|
|
As you can see, DIR reports that the file size is 0 bytes, but this is not true. The DIR command only reports to the user the size of a file's unnamed stream; the sizes of named streams within the file are not shown to the user. By the way, Explorer also reports a file size of 0 bytes. This allows for some geeky party games where you can allocate a large stream in a file on a friend's disk. The friend won't be able to discover where all the disk space has gone because all of the tools report that the file occupies only 0 bytes! When working with streams, remember that it's only the tools that don't treat streams with the respect that they deserve; NTFS has full support for streams (they even count against your storage quota).
Now, to see the contents of the stream, execute this command: |
|
|
Here's another way to use streams. Say that you are writing a word-processing application. When the user opens up an existing document, you will probably create a temporary file that holds all of the user's changes. Then, when the user decides to save the changes, you will write all of the updated information to the temporary file, delete the Original file, and finally move the temporary file back to the Original file's location while renaming the file.
This sounds fairly simple and straightforward, but you're probably forgetting a few things. The final file should have the same creation timestamp as the Original, so you'll have to fix that. The final file should also have the same file attributes and security information as the Original. It is very easy to miss properly updating some of the Se attributes during this file-save operation. If you use streams, all of the Se problems go away. All streams within a single file share the file's attributes (timestamp, security, and so on). You should revise your application so that the user's temporary information is written to a named stream within the file. Then, when the user saves the data, rename the temporary named data stream to the unnamed data stream, and NTFS will delete the Old unnamed data stream and do the rename in an all-or-nothing manner. You won't have to do anything to the file's attributes at all; they'll all just be the same. Before we leave streams, let us just point out a few more things. First, if you copy a file containing streams to a file system that doesn't support streams (like the FAT file system used on floppy disks), only the data in the unnamed stream is copied over; the data in any named streams does not get copied. Second, named data streams can also be associated with a directory. Directories never have an unnamed data stream associated with the M but they certainly can have named streams. Some of you may be familiar with the DESKTOP.INI file used by the Explorer. If the Explorer sees this file in a directory, it knows to load a shell namespace extension and allows the shell namespace extension to parse the contents of the directory. The system uses this for folders such as My Documents, Fonts, Internet Channels, and many more. Since the DESKTOP.INI file describes how the Explorer should display the contents of a directory, wouldn't it make more sense for Microsoft to place the DESKTOP.INI data into a named stream within a directory? The reason Microsoft doesn't do this is backward compatibility. Streams are implemented only on NTFS drives; they do not exist on FAT file systems or on CD-ROM drives. For the same reason, streams may not be good for your application. But if your application can require NTFS, you should certainly take advantage of this feature. The code in Figure 2 demonstrates how an application can work with streams. The code is well-commented, so we won't describe it here. After you compile the code, step through it in the debugger. As you reach each TEST comment line, execute what it says in a command shell to see the results.
Hard Links
|
|
|
When calling CreateHardLink, you must pass it the path name of an existing file and the path name of a nonexistent file. This function will find the existing file's entry in the MFT and add another file name attribute (whose data identifies the new file's name) to this entry. This function also increments the hard link's count attribute as well. If the lpSecurityAttributes parameter is not NULL, the security descriptor associated with the file is changed to the security descriptor passed in.
After CreateHardLink returns, the directory where you created the hard link will show a new file name. Open this file to access the data within the Original file. In fact, you can create several hard links to a single file. The file is actually on the drive once but has several path names on the drive that all access the exact same file data. When you open the file by one path name and change its contents, and then open the same file later using one of its other path names, you will see the change. Since all of the Se hard links are contained inside a single MFT entry, all of the M share the exact same attributes (timestamp, security, streams, and file sizes). We mentioned that every time you create a hard link, the system adds a new Name attribute and increments a reference count to the file's MFT entry. Each time you delete a hard link, you are simply removing the corresponding Name attribute and decrementing this reference count. When you delete the last hard link to the file, the reference count goes to 0. Then NTFS will actually delete the file's contents and free the file's MFT entry. You can determine how many hard links a file has by calling GetFileInformationByHandle and examining the BY_HANDLE_FILE_INFORMATION structure's nNumberOfLinks member. Like streams, hard links have been a part of NTFS since its inception because the POSIX subsystem required the M. The new CreateHardLink function now exposes this capability to programmers using Win32. You should note that hard links are for files only; you cannot create a hard link of a directory. Figure 3 shows a simple utility that allows you to easily create hard links on your NTFS volume.
File Stream
Compression
|
|
| To compress the stream, NTFS logically divides the data stream into a set of compression units. A compression unit is 16 clusters long (32KB, assuming 2KB per cluster). Each compression unit is read into memory, the algorithm is run over the data, the data is compressed, and the resulting data is written back out to disk. If the compressed data saves at least one cluster, then the no-longer-needed clusters are freed and given back to the file system. If the compression doesn't save any clusters, then the Original data is left on the disk uncompressed.
So, for our 120KB stream, it is possible that the first 32KB compresses down to 20KB, saving 12KB (6 clusters); the second 32KB might not compress down at all, saving 0 KB; and the third 32KB might compress down to 24KB, saving 8KB (4 clusters). So far, NTFS has compressed the first 96KB of the stream. The stream contains another 24KB. Since 24KB is smaller than a compression unit (32KB), NTFS doesn't even touch the end of the file at all; it simply stays on the disk uncompressed. As NTFS compresses this file, it builds a table that looks much like Figure 4 . Now, you might look at this compression algorithm and think that it could compress the data much better. For example, the stream would be much smaller if NTFS would compress the whole 120KB stream and then write the compressed data back to the stream. But there is an enormous cost in performance associated with this. In addition, if NTFS did this and an application wanted to randomly seek to an offset that is 40KB into the stream and start reading, NTFS would have to decompress the whole stream on the fly in order to accommodate the application's request. By breaking up the file into compression units, NTFS can read the clusters associated with the second compression unit within the stream, decompress this unit into the system's cache, and return the decompressed bytes to the application. The end result is a nice tradeoff between compression and speed. NTFS can also compress streams as you write to the M. When an application writes data to a stream, the data is actually cached in memory and is not immediately written to disk. Periodically, the system's lazy-writer thread awakes, figures out how the data bytes fit into a compression unit, compresses the data, and finally writes the compression unit out to the disk. You can determine whether a stream is compressed by calling DeviceIoControl passing the FSCTL_GET_COMPRESSION control code. You can also determine if any stream within a file has ever been compressed by calling GetFileAttributes and checking the FILE_ATTRIBUTE_ COMPRESSED bit flag. If you want to figure out whether a specific stream is compressed, call GetFileInformationByHandle and check the FILE_ATTRIBUTE_COMPRESSED bit flag. The GetFileSize function returns the full size of a stream assuming no compression, while the GetCompressedFileSize function returns the actual number of bytes that a file's stream requires. You can also call DeviceIoControl passing FSCTL_SET_ COMPRESSION for a directory. When you do this, any new file streams and subdirectories created within this directory are automatically compressed. No change occurs to any existing file streams or directories; you would have to explicitly call DeviceIoControl with FSCTL_SET_COMPRESSION to compress any existing streams or directories. Finally, you can tell if the file system supports compression by calling GetVolumeInformation and checking to see if the FS_FILE_COMPRESSION bit flag is on. Compression will be triggered the next time a file is accessed in a directory.
Sparse Streams
|
|
|
After this code executes, take a look at this file in Explorer; you will see that it is 64GB in size even though your hard drive may be much smaller than that (my hard drive is only 4.5GB). In the Streams section, we mentioned a party game in which you create streams with lots of data in the M, for which Explorer showed file sizes of 0. Now you have a new party game, where you can create streams with no data in the M and Explorer shows enormous file sizes. What fun!
Encrypted Streams
Reparse Points
Quotas
|
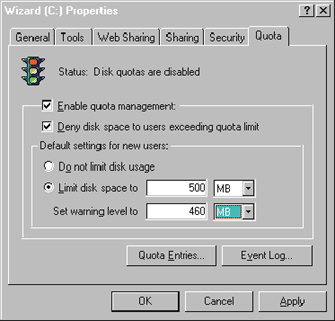 |
| Figure 7 Quota Tab |
|
|
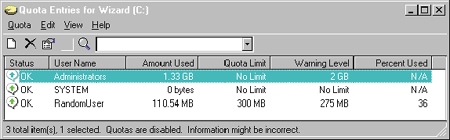 |
| Figure 8 Quota Entries Tool |
|
Conclusion
From the November 1998 issue of Microsoft Systems Journal.
|