![]()
This article assumes you're familiar with Java, COM and
Database Fundamentals
Download the code (1KB)
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
RDO Programming with Visual J++
Ted Pattison |
| When you’re using Visual J++ to create a data access solution, you must choose your strategy wisely. Remote Data Objects is a complete solution based on ODBC. |
|
If you are programming with Java to create an application that accesses a client-server database management system (DBMS) such as SQL Server™ or Oracle, you must choose a data access strategy. Most of the currently publicized strategies rely on evolving technologies that aren't quite ready for use in production code. JDBC is the new, all-purpose data access strategy from Sun Microsystems that is part of the JDK 1.1. JDBC could evolve into a good strategy, but its limited API functionality and lack of available drivers currently make it a poor choice for serious database developers. The Microsoft® ActiveX™ Data Objects (ADO) also shows promise, though many people (falsely) see it as a work-in-progress that is not fully implemented. ADO shipped one year ago and now incorporates proven cursor functionality. One day in the not-too-distant future, ADO will have all the capabilities of all the present Microsoft database APIs combined; at that point it will be the preferred method for programmatic data access, but that day is not yet here. If you need to write production code today, you might want to use something that has already been around the block once or twice.
Many applications currently use Remote Data Objects (RDO), which has been layered on top of ODBC. There are a wealth of high-performance ODBC drivers for every major database, making the combination of ODBC and RDO a very open solution. This article is intended to get you started with RDO programming using Visual J++™. It will present some background information on both ODBC and RDO, and then present some RDO coding examples you can use to connect to your DBMS and to access your database.
What Is ODBC?
ODBC Architecture
|
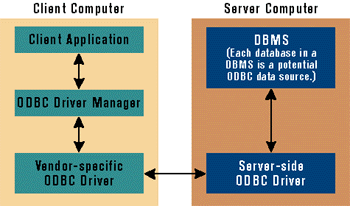
Your client application communicates with a core set of ODBC services provided by a component that ships with the operating system. These services are collectively known as the ODBC driver manager, and are responsible for loading and interacting with vendor-specific ODBC drivers. Each ODBC driver is responsible for connecting to and communicating with a unique data source. A data source can be a database within a client-server DBMS or a database file like those used by the Jet database engine. Each ODBC driver is responsible for reading and writing data to and from its own proprietary data source. Client applications track the profile of each data source with a data source name (DSN). A DSN is a set of registry entries that define an ODBC driver, a host computer, and a target database.
Client-side ODBC components provide a conduit between your application and a remote DBMS. Client applications establish remote connections and execute SQL statements and stored procedures. The DBMS responds by returning messages as streams of data. The ODBC API also makes it possible to handle output parameters, return values, and error messages from stored procedures.
If you're accessing the ODBC API directly, you'll need to understand the purpose of three different ODBC objects: the environment object, the connection object, and the statement object. The environment represents the ODBC runtime
environment. The connection represents an established
communications channel between a client application and
a database within a DBMS. Within the context of an established connection you can create statement objects to submit SQL statements and manage resultsets returned by the server. ODBC allows you to connect a single client application with several DBMS hosts at the same time. Some, but not all, DBMSs allow a single connection to support multiple statements.
The ODBC API is accessible through a set of DLLs that provide a standard call level interface. ODBC was written in C and is intended to be used by C programmers. Modern languages like Visual Basic® and Java have tried to hide the grungy details of dealing with handles, pointers, memory buffers, and character arrays from its programmers. When you write to the ODBC API you are expected to think and act like a C programmer, grunge included.
As a Java programmer, you could use J/Direct™ to write Java code that talks directly to the ODBC API. If you go down this road, you will have to confront conversion issues between C and Java. For example, Java doesn't support unsigned integers, and ODBC uses ANSI strings while Java uses Unicode. While you might feel compelled to wrap ODBC calls in generic Java classes to hide the grungy stuff and improve your productivity, there is no reason to create a collection of ODBC wrapper classes when RDO already does this for you.
Object-oriented Access to ODBC
RDO was created for one reason: to provide a set of COM objects that offer friendly object-oriented access to the ODBC API. The philosophy behind RDO is that programmers working with Visual Basic and Java are more productive and less prone to creating bugs when they use COM objects instead of a C-style call level interface. The first version of RDO shipped with Visual Basic 4.0 Enterprise Edition in 1995. Version 2.0 of RDO, which shipped in 1997, addresses enhancements made to ODBC 3.0.
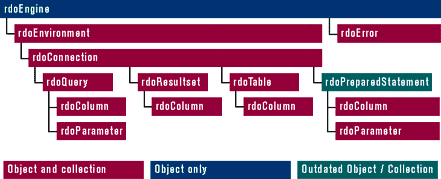 |
| Figure 2: RDO Object Model |
|
Figure 2 shows the object model exposed by RDO. If you have used Data Access Objects (DAO), you will notice that it resembles the RDO object model. Both object models provide a top-level object that controls the database engine. DAO has a Workspace object, while RDO provides a similar rdoEnvironment object. DAO has a Database object, while RDO has rdoConnection. DAO uses the terms recordset and field, while RDO uses resultset and column. Porting code from DAO to RDO is straightforward, if tedious. DAO is usually employed to access Jet database files, but you can also use it to communicate with DBMS hosts through ODBC. Using DAO to access a DBMS like SQL Server requires bulky, inefficient runtime components on the client. Moreover, DAO is limited in its control over stored procedures. In particular, DAO doesn't give you control over stored procedure parameters, nor does it handle error messages generated by the server. A recent release of DAO contains a new component called ODBCDirect, which simply provides an additional layer so DAO can communicate with RDO. ODBCDirect was intended for developers of Microsoft Office-based apps who do not have the licensing rights to distribute RDO to client desktops. If you can write your application to RDO, you are better off. If you have Visual J++ Enterprise Edition, you should use RDO because ODBCDirect only supplies a subset of RDO functionality and it introduces additional runtime layers. (For more information on ODBCDirect, see the November 1997 issue of MIND.)
COM Programming with Java and Visual J++
|
|
|
After importing the RDO shim class package, you can use the classes and interfaces as if they were written in Java. If you have already done RDO programming using Visual Basic, you will find that writing the equivalent code in Java is a little more challenging. One of the bigger obstacles is dealing with the variant datatype. Variants are commonly used as argument types in COM components like RDO and DAO. Visual Basic will convert back and forth automatically whenever a variant is required. Java programmers must explicitly create variant objects and set the values before passing them as an argument. It's not that hard to do, but setting up variants makes for more lines of code. You will find it difficult to locate adequate online help or documentation for Java/RDO programming. Even the help files that ship with Visual J++ were written for programmers using Visual Basic. These help files will tell you everything you need to know about each RDO database object and the semantics of each method, but it will not tell you the correct Java types to use when you call them. OLEVIEW.exe is a handy COM utility that comes with Developer Studio. This tool will allow you to examine the entire RDO type library. It shows a list of methods for each interface that includes method signatures. It also lists the enumerations of RDO constants you can use. The only problem with OLEVIEW is that it uses COM's native language, IDL, to show you all this information. If you don't know how to read IDL, you might still be confused over what Java type to use in a particular method call. (Your efforts to learn IDL and OLEVIEW will make you a much stronger COM programmer.)
Connecting to a DBMS
|
|
| Once your application or applet has an _rdoEngine reference, you can use it to create an rdoEnvironment object, which wraps an ODBC environment handle and provides the means for establishing a connection to a DBMS. The environment is also responsible for providing a scope for transactions. If you want to conduct two separate transactions at the same time, you must use two separate rdoEnvironment objects. You can create an rdoEnvironment by using the rdoCreateEnvironment method like this: |
|
|
rdoCreateEnvironment takes three parameters. The first argument is the name. Passing a name allows you to associate a unique string with the rdoEnvironment object. There usually isn't a need to associate a unique name with an rdoEnvironment object, so you can pass an empty string for this argument. (Only rdoEnvironments that have names will be appended to the rdoEnvironments collection.) The other arguments allow you to pass a default user name and password. Typically you pass these when you establish a connection so you can leave them blank as well. After acquiring a reference to an rdoEnvironment, you can now open an ODBC connection by creating an rdoConnection object. To open an rdoConnection you must have a specific database in mind. This means that you must know which ODBC driver to use (SQL Server or Oracle, for example), where the host machine is located, and the name of the logical database within the server. There are a few options as far as how to profile this information. One way is to create a DSN on the machine that will be running the application. The DSN can be stored in the form of registry settings or in a simple text file. User DSNs and system DSNs are both stored as collections of registry settings. User DSNs are associated with a single user and will not be available when one user logs off and another logs on. System DSNs are usually a better choice because a single DSN can accommodate any user that has logged on to the computer. The ODBC driver manager also provides a graphical utility to help create DSNs. You can run this utility by double-clicking on the ODBC icon in the control panel of any Windows system. ODBC recently introduced file DSNs, which store all settings in a simple text file on the user's computer. All three types of DSN are recognized by a logical name. When your code references a DSN, the ODBC driver manager looks through all sets of DSNs on the local machine to find a matching name. Once you have registered a DSN, you can connect to a DBMS by invoking the OpenConnection method on a rdoEnvironment. |
|
|
This code shows a very simple connection technique. The first argument to OpenConnection passes the logical name of the DSN and all the other arguments are set to use their default values. However, using these other arguments will give you more control over the login process. The second argument allows you to control the interactive dialogs that the user receives when connecting to a DBMS. The third argument allows you to set a read-only flag which can help to optimize a connection. The fourth argument passes a connect string, which gives you more control than merely supplying the name of a DSN. The last parameter allows you to set various connection options. Many developers prefer to use the connect string argument instead of the DSN because it provides the ability to pass values for the user name and password to the DBMS. The following code demonstrates two calls to OpenConnection that illustrate the differences between these techniques: |
|
| Many developers are not comfortable letting users configure their own DSNs. If you don't want users messing with DSN settings you can either create a DSN programmatically with the RegisterDSN method of the rdoEngine or you can create a DSN-less connection string. The following example shows you how to connect with a registered DSN. Note that you must include the driver, the database server name, and the target database. |
|
|
When you include the second argument to OpenConnection you should use the constants provided in the RDO enumeration PromptConstants. (OLEVIEW will let you examine all the RDO constant enumerations.) These constants allow you to control whether the user receives a dialog to select a DSN or a dialog to provide a user name and password for logging onto a DBMS. Some RDO applications require each user to log in with a unique user account maintained on the database server. Other applications rely on a single, generic account for every user on the system. If your application can use a single user account it eliminates the need to administer an account for each user. Whether you use a single user account or a separate one for each user, you have complete control over these interactive dialogs at connection time. If you use the constant rdDriverPrompt, the driver manager displays the ODBC Data Sources dialog box. The connection string used to establish the connection is constructed from the DSN selected and completed by the user with the dialog boxes provided by ODBC. If you use rdDriverNoPrompt, the driver manager uses the connection information provided by the DSN and connect string arguments to establish a connection without user interaction. If sufficient information is not provided, the OpenConnection method throws a runtime exception. If you use rdDriverComplete, the ODBC driver manager only interacts with the user if the connect string doesn't supply all the needed information. If the connect string has everything, then the connection is made without user interaction. This is the default setting for this argument. RdDriverCompleteRequired behaves like rdDriverComplete except the driver disables the controls on the ODBC dialogs for any information that is supplied by the connect string. This means any settings you pass in the connect string cannot be modified by the user. Another option for connecting to a DBMS is to create a standalone rdoConnection object. This type of connection doesn't require you to create an rdoEnvironment object. Instead, it uses the default rdoEnvironment object in the rdoEnvironments collection. You can create a standalone connection object by using operator new. After you have created the new rdoConnection object, you must set the Connect property and execute the EstablishConnection method to connect to the DBMS. A simple example looks like this: |
|
|
Executing SQL Statements
Once you have successfully connected to a database within a DBMS, you can begin modifying and retrieving data. When you would like to retrieve or modify data, you must supply the SQL statements that instruct the database engine what to do. If you have used DAO and the Jet engine, you're probably used to asking for the name of a table or QueryDef, but when using RDO and ODBC everything you do will require a SQL statement. You must know enough about the SQL language to be able to insert, update, and delete rows from a table. The following SQL statement will add a new row to a table: |
|
| The example above demonstrates a SQL statement that will modify a database. You, of course, will not hardcode the actual column values for a row into your Java code; you must parse these together at runtime. One tricky aspect of doing this is dealing with string values that have embedded single quotes. Most DBMS engines such as SQL Server use the single quote to delimit string values in a SQL statement. If a string within a SQL statement contains a single quote, the SQL engine will think this is another delimiter and will become very confused. Most DBMSs will reject a SQL statement that contains a literal string value with an embedded quote like the name O'Leary: |
|
| There are a few different techniques that developers have used to deal with this problem. The best way is to double-pack all the single quotes within string values. The DBMS engine will interpret two consecutive single quotes as a single quote. The following SQL statement will fix the problem and insert the row into the database: |
|
|
Many ODBC and RDO developers who use this double-packing technique create a utility function that takes a string value and returns a string with single quotes at the beginning and end and double-packs any embedded single quotes. After executing a SQL statement that modifies data, you can examine the RowAffected property. This property can be used to determine if the correct number of records was inserted, updated, or deleted.
Managing Resultsets
Using Stored Procedures
|
|
|
Each question mark in the string will become part of the rdoParameters collection. If you want to use a return value, it must be the first parameter in the collection. Each parameter has a Direction property that defaults to rdParamInput. If your parameters aren't designed for input parameters, you must change them before executing the procedure. It's pretty simple once you set up the parameter directions. You assign a value to input parameters, execute the procedure, and inspect the values of output parameters and return values.
RDO Exception Handling
Where to Go from Here
|
From the February 1998 issue of Microsoft Interactive Developer.
