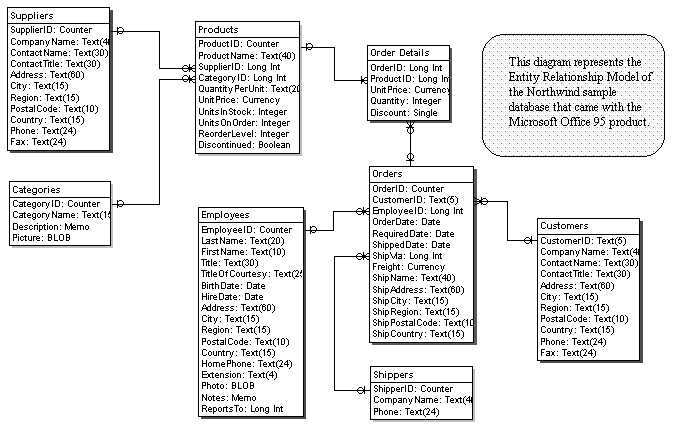
 Rounding off the database
Rounding off the database
Markus Bosshard graduated in
1986 from Wits University, South Africa, with a bachelors degree in computer
science. He owns the company MSB Software Engineering, which develops Windows
software under contract. Currently, he's re-engineering a suite of business
applications originally written for BTRIEVE to use a client/server architecture
with a SQL database at the backend. Markus_Bosshard@compuserve.com.
Once the data model of an application has been clearly defined, the remaining
work on the application will be greatly reduced.
Sidebar: Data Domains
As you define your attributes, you should
start thinking about the attributes' domains. An attribute's domain describes
what values are permissible for the attribute. This can vary from a list
of specific values (for example, all the states in the union) to a rule
that describes the valid values (for instance, all positive integers between
0 and 500). In Access, the decisions you make about the attributes' domains
will not only help you understand your data better, they can also translate
directly into entries in the ValidationRule properties for the field and
table.
Understanding the field's domain also helps when setting your field names.
You'll have to decide whether you want the same field in different tables
to have same name. What's meant by the "same field in different tables"
is that these fields share the same domain. The question is whether you
want to use unique names for these fields. As an example, do you call the
description field in the bills table and the description field in the customer
table both "Description"?
I give unique names to these tables, but I follow a naming convention that
allows me to see that the fields share a domain. I do that by giving fields
that share the same domain the same name and then adding a prefix to the
field name based on the table the field is in. As a result, the customer
description field will be called CustomerDescription and the field in the
Bills table will be called BillDescription. This method saves quite a bit
of typing when creating queries and helps to reduce confusion.