![]()
This article assumes you're familiar with Internet basics.
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
The ABCs of TCP/IP Marco Tabini |
| The Internet is based on TCP/IP, a protocol that originated years before there was an information superhighway. But what does TCP/IP really do? |
|
You probably already know that the Internet grew from a small military project during the sixties into the largest computer network in the world. When the ARPANet project kicked off almost thirty years ago, its goal was to create a distributed and decentralized computer network for the defense community. If an enemy destroyed a strategic command center, others would be able to keep on working to ensure the security of the nation. Needless to say, network connectivity was limited. If you think that connections are slow today, in those days a 300 bps connection was a luxury that only large organizations (like the government) could afford.
TCP/IP was the set of protocols developed to provide transmission and addressing for these connections. (You need to know two important things on a network—what you're sending and where it's going.) Surprisingly, the underlying structure of the ARPANet (which eventually became what is called the Internet) was fundamentally the same then as it is today, and so are many of the protocols widely used in network applications. This makes TCP/IP a pretty amazing and adaptive suite of protocols. Change has been sporadic because of the increasing complexity of the Internet itself. It's one thing to order a bunch of military sites to change their firmware; it's another thing entirely to convince millions of unrelated people to spend money upgrading all their systems. While backwards compatibility is a generally acceptable compromise in the case of high-level protocols (such as HTTP), low-level protocols do not benefit from this kind of solution because of their strategic role in the exchange of information. Consider what would happen if a new protocol revision changed the number of bits used for IP addressing as an optional implementation. All of a sudden, computers that do not comply with the specification would be unable to access machines that do. This would be big trouble.
The Multilayered Internet Cake
|
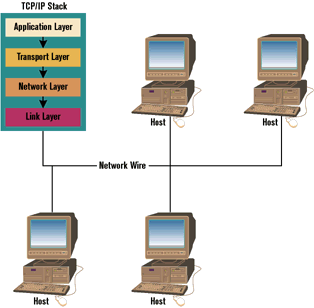
The transport layer takes care of the flow of data between two network hosts. The network layer controls how data is moved around in the network. For example, it establishes what route a particular packet must follow to move from host A to host B, and provides a method for identifying hosts in a unique way. The link layer sends and receives data over the physical medium chosen for the transmission of information. The important part of this surprisingly simple scheme is that every layer in the chain treats the information received from or destined to the higher-level layer as pure data. This means that each layer is virtually independent from the others and its implementation can be arbitrary. Thus, as long as the link layer pours data onto the wire, the other layers are not affected in any way by its implementation, and vice-versa.
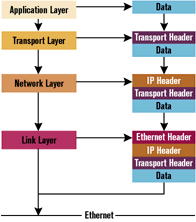
To better understand the way this works, take a look at Figure 2. During a send operation, each layer encapsulates all the information sent by the previous one with a series of headers. During a receive operation, these headers are peeled off the data chunk one by one so that only the relevant data reaches the application layer. Keep in mind that a packet can contain data destined for someplace other than the application layer. In that case, the processing of information stops when no more data is available.
TCP/IP uses two transport protocols: Transmission Control Protocol (TCP) and User Datagram Protocol (UDP). TCP provides a reliable, connection-based transmission channel; it takes care of breaking large chunks of data into smaller packets, suitable for the physical network being used, and guarantees that data sent from one end is received on the other. UDP, on the other hand, is a connectionless protocol and does not guarantee the delivery of data sent, thus leaving the whole control mechanism and error-checking to the application itself. Most networking programs and application-layer protocols, such as HTTP or FTP, rely on TCP
because it is easy to implement and provides most of the
traffic control operations. However, there are cases in which UDP works better, particularly when data delivery is of little or no importance. DNS and the old Talk protocol are partly based on UDP, and it's the choice of many streaming formats like NetShow.
It's Ethernet, but Not Forever
Ethernet is probably the most common type of LAN on the Internet. Chances are, unless you are particularly lucky and can afford a Token Ring connection, your office will be
interconnected using a Ethernet network, too.
The Ethernet standard was developed by IBM, DEC, and Xerox, and was published in 1982. It can reach speeds up to 100 Mb/s, and revolves around a protocol known as Carrier Sense, Multiple Access with Collision Detection (CSMA/CD). In the basic design principle of Ethernet, the wire is considered one large pipe, to which every host has access at the same time and on the same level. When a network card has a packet to send, it waits until the pipe is available and then tries to send its own data. If another network card tries to do the same thing concurrently, a collision occurs; both cards abort the transmission and retry after a random amount of time. The randomization of the retry interval ensures that if two packets collide, they will not be resent at the same time again.
Needless to say, collisions are bad for your LAN. When they occur, the network stops working—even if for a short amount of time—and its efficiency decreases. Collisions can be caused by many factors, including the number of hosts on the network and the quality of the cabling, and they can affect throughput performance even with minimal amounts of bandwidth usage.
As the Ethernet implementation considers the wire to be one shared data pipe, data has to be divided in chunks of an appropriate size to guarantee an even bandwidth usage to all hosts on the network. This way, each host will only send packets of up to a predefined number of bits, allowing every other network card to participate in the transmission of data. The maximum size that a packet can assume is characteristic to each specific network implementation, and is called Maximum Transmission Unit (MTU). For Ethernet, this value is 1,500 bytes.
The division of information in packets makes it also possible to implement an efficient error control system. When a network card sends a packet, a Cyclic Redundancy Check (CRC) value is attached to it. Once the destination host has received the packet, it recalculates the CRC and checks it against the one attached to the packet. If they do not match, the packet is discarded.
Internet ZIP Codes
As all hosts on an Ethernet network share the same data pipe, they also receive all the traffic that travels across the wire. For identification purposes, every network card is assigned a 32-bit hardware value known as its MAC address. Whenever a packet is sent across the network, the software in the link layer envelops it in an Ethernet datagram that contains the MAC address of the destination machine. Once on the wire, the packet is received by all the hosts on the LAN, but only the one with the MAC address specified in the destination field will actually process it.
Almost all cards now support a special working status, called promiscuous mode, that bypasses the MAC address filtering process and processes all the packets that it receives, regardless of the destination address. Promiscuous mode is the foundation of apps known as network analyzers or packet sniffers that allow a host to monitor all the traffic on its network—for diagnostic purposes, of course.
Since this hardware addressing model is specific to Ethernet, it is not suitable as a general system for uniquely identifying hosts on a WAN that is based on several networking systems. Remember, the network layer is completely independent from the link layer, and therefore it doesn't know what hardware addresses are.
To solve this problem, TCP/IP implements Internet Protocol (IP) addressing. I am sure
that you are familiar with numeric IPs, usually expressed in the well-known dotted decimal
notation:
|
|
Each of the fields in an IP address is an 8-bit integer. These 32-bit addresses perform a function that is very similar to hardware addresses, but they work across Token Ring, fiber-optic, and even phone networks just as well.
The structure of an IP address is shown in Figure 3. As you can see, the first few bits (up to five) determine what class an address belongs to. With the exception of multicast addresses, the class type tells you how many bits are used to identify a specific LAN (Network ID) and specific hosts inside that network (Host ID). The more addresses a network needs, the higher its assigned class level. But more address space means less efficiency in message routing. Thus, a class A network can contain about 224 hosts, while a class B network can contain up to roughly 216. In most cases, however, only class C networks, with 28 possible hosts, are efficiently usable, because only very few organizations worldwide have a need for more than 254 addresses. |
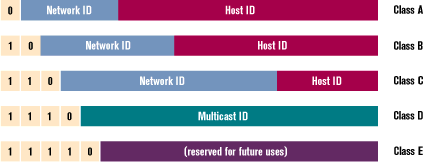 |
| Figure 3: IP Address Structure |
|
A few network spaces have been reserved for particular uses. The class A network 127.xxx.yyy.zzz, for example, is used for the internal loopback interface; any packet sent to the address 127.0.0.1 is automatically redirected from the send queue to the receive queue, without ever even reaching the link layer.
IP supports three types of addressing. In the simplest case, when a packet has to be sent to a specific host whose address is known, unicast datagrams are sent. These can be considered person-to-person calls in the sense that (at least in theory) no other host on the network should be interested in processing that data. When a host wants to send a datagram to all its counterparts on the network, a multicast packet is sent to the special address 255.255.255.255. IP will expect that packet to be delivered to all the hosts on its local network. Multicast datagrams are supposed to be delivered to a specific group of hosts. Multicast has been designed primarily for connectionless environments where one server has to send a stream of data to several clients with minimal bandwidth usage. During a normal TCP session, each client has to establish a separate connection to the server. At the same time, the server has to send the same data to each client independently, thus limiting the maximum number of clients that can be served due to bandwidth restrictions. Using multicast technology, only one copy of the data is sent out to a group of hosts, and that packet is routed through the Internet until it reaches every member of that group. Given the proper conditions, multicast is a terrific improvement over unicast for certain applications, such as audio or video streaming or push technologies. However, the Internet community has consistently ignored it for a long time; it's difficult to implement and it's almost unsupported by any major network programming libraries. Due to increasing interest in streaming technologies and the requirement of a more bandwidth-friendly transmission system for multimedia-intensive applications, some vendors are beginning to develop multicast-based solutions. A server running Microsoft® NetShow™ 2.0 (or higher), for example, is capable of transmitting high-quality audio and video over the Internet with very limited bandwidth usage.
Mind the Gap
When the Gap is Bigger
|
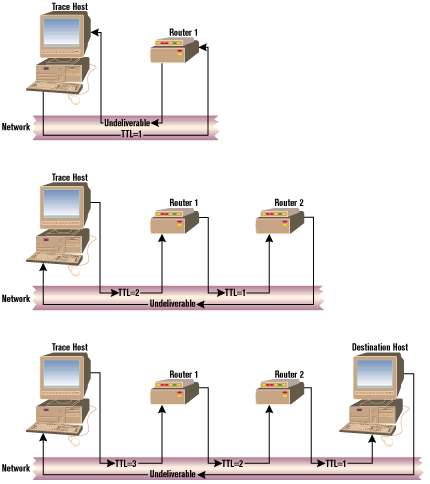 |
| Figure 4: Tracert in action |
|
The TTL value is the key to the popular tracert program, whose working principle is shown in Figure 4. Tracert sends a packet of data to a given host, starting with a TTL of 1 and increments it by one until the host is reached, thus receiving "time exceeded" messages from every router that is encountered by the packet on its way. Since every IP message carries the IP address of its sender, tracert can output the exact path followed by the packet to its destination. This program is very useful for finding faulty routers on the Internet and working around them.
Moving Up
Reaching the Top
Where to Go from Here
|
From the October 1998 issue of Microsoft Interactive Developer.