
by Tom Trinko
This is the second part of a two-part article in which we show how to create a picture class that handles loading and manipulating images in applets. Last month, we demonstrated how to use interfaces to provide callbacks, the MediaTracker class to load images, and the Runnable interface to make classes with threads. We developed the HTML and applet subclass, called image_tools, to test the picture class, as well as the picture_user interface, which provides the callbacks used by picture to inform the image_tools instance when images are ready or when errors occur. We also filled in the basics of the picture class that loads an image.
In this installment, we'll show how to convert an image into an array of pixel values and how to apply various operations to those pixels, then convert the modified pixels back into an image. Don't panic if you missed the last issue, because the overview that follows will get you up to speed on what you missed.
OverviewLast month, we built a simple test applet that loads and displays a GIF file. We also developed a picture class that loads images and uses callbacks in our image_tools class to tell it when the image is ready to display. This month, we'll extend picture so it allows us to modify the image. Let's take a closer look as the classes we'll use.
image_toolsThis is the test applet we built last month. It sets things up, creates an instance of the picture class, then lets the picture instance do most of the work.
pictureThis class is a nice black box for getting and processing images. It's designed to be easily extensible so that we can quickly add new image-processing functions. It hides all the details of loading an image so all we have to do is pass a filename into it and get an image from it. A picture instance lets the applet that created it know when an image is ready to be displayed by invoking a callback method that the applet supports.
We used an interface, called picture_user, that contains the declarations of the callback methods so that instances of picture can be used with any class that extends (i.e., inherits from) Applet and implements picture_user .
The basic Java toolset contains a number of classes that make it very easy to work with images. Two of the most valuable are MediaTracker, which handles the asynchronous loading of images, and PixelGrabber, which lets us convert an image into an array of pixels that we can manipulate. We saw how to use MediaTracker in part 1, and in this part we'll see that PixelGrabber is just as easy to use.
MediaTracker addresses the problem of making the asynchronous loading of images easy. Essentially, we tell MediaTracker that we're loading an image, and it tells us when the image is fully loaded. While we used a GIF file in this example, we could just as well have used a JPEG-formatted file.
PixelGrabber is designed to convert a Java image—or a rectangular piece of an image—into an array of pixels. Each pixel is an int containing the Alpha, Red, Green, and Blue values for the pixel. The first two bytes of the int are the alpha channel (used for transparency and other effects), the second two are for red, the third two are for green, and the last two are for blue. This arrangement allows each channel or color to have a value ranging from 0 to 255.
Once you have an array of pixels, you can create methods that manipulate the image just like PhotoShop does. In this example, we'll apply a blurring function to an image, and we'll also provide the code needed to apply a variety of unsharp masks, which enhance detail.
The sample appletAs we left things last month, image_tools, the HTML that calls it, and the picture_user interface were all complete. All that's left is to add some methods to the picture class to handle the modification of the base image. So let's walk through those methods now.
Making space for the modified imageThis method, shown in Listing A, is called in the run method when the base image is finished loading. It creates two int arrays, which are the size of the just-loaded image. The dimensions of the array, stored in the picture class attributes x_max and y_max, are in pixels.
Listing A: Getting ready for pixels
/**This method initializes a workingClouding the issue: blurarray, which we will use as temporary storage when we modify an array, andthe modified array, which is used tostore the modified image using theimage size values determined when thebase image was loaded */private void init_working_image() {working_pixels = new int[x_max*y_max];modified_pixels = new int[x_max*y_max];}
After the base image is loaded, we can call various image-manipulation routines to change the loaded image and save it to a new, modified image. The one we call in image_tools is blur, which applies a simple blurring convolution to the base image to provide a kinder, gentler, fuzzier image, as you see in Figure A.
Figure A: We applied a simple blurring convolution to the base image to obtain the blurred image.
Convolutions are a very important part of image processing. Like anything developed in the scientific community, they're somewhat obscured by the use of intimidating terminology. The good news is that a convolution is really very simple. All a convolution does is compute a new value for a pixel based upon the current value of the pixel and the values of some set of its neighboring pixels. For example, a simple way to blur an image is to average the value of each pixel with the values of its nearest neighbors.
The convolution array for a blur of radius 1 pixel, shown in Figure B, is a 3-by-3 matrix filled with 1s. Each entry in the matrix is a weight that's used to multiply the value of a pixel offset from the pixel whose value we're computing. So if we're computing a new value for the pixel at point (x=10,y=13) and we have a 3-by-3 convolution, we'll use pixels whose y coordinates range from 12 to 14 and whose x coordinates range from 9 to 11. If the pixel whose value we're calculating is at (x=10,y=13), then we'd use the upper right-most entry in the matrix as the weight for pixel (x=9,y=12).
To compute the new value for the pixel, we take the values for each of the nine pixels, multiply them by the relevant weight, add them together, then divide by the sum of the weights in the matrix, 9 in this case. The result is the new value for the pixel in the center. We can apply this matrix to each color or to just one color or any combination of the red, green, and blue color values for a pixel. In order to blur color images, we'll apply the convolution separately to each color and use the new value as the value for that color.
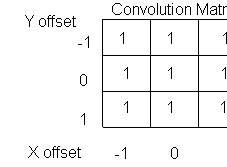
Figure B: Here's our convolution array for a blur of radius 1 pixel./P>
Please note: You can obtain interesting effects by mixing colors. For example, you can use the red values to compute the new blue value.
We apply this convolution process for every pixel in the image that's farther than radius pixels from any edge. That limitation lets us avoid problems that would arise if we tried to get the values of nonexistent pixels—ones with negative coordinates or coordinates larger than x_max or y_max. In keeping with our concept that the picture class is a black box, all we need to do to create a blurred version of the base image, or blur the currently modified image, is call the blur method, shown in Listing B.
Listing B: Blurring an image
/** Blur an image@param radius The radius, in pixels, to compute the blur over@param use_base_image if true use the base image. If false use the modified image@return true if ok, false if there is a problem, such as the requested image not being available */public boolean blur(int radius,boolean use_base_image) {int i;int npixels;//handle problems such as the modified//image not being availableif(!use_base_image &&!mod_pixels_loaded_flag) {return false;} else {//the convolution is a square with sides//radius + center pixel + radius longnpixels = (2*radius + 1)*(2*radius + 1);//construct the weights applied to each//neighboring pixel in the blur//convolutionpixel_weights = new double[npixels];for(i=0;i<npixels;i++) {pixel_weights[i] = 1;}//apply the blur convolution to the dataapply_convolution(radius,use_base_image);return true;}}
This method is fairly simple. First, it makes sure that, if you've told it to operate on the modified image, there's a modified image to work with. Next, it sets up the values for the convolution matrix you'll use. You must do this dynamically, since whatever calls blur can specify the size of the convolution matrix by specifying the value of radius. Finally, it calls the apply_convolution method, which is a general engine for applying convolutions to an image.
Generic convolutions: apply_convolutionThis method is fairly long because it's designed to do the work for any convolution with any radius value. Let's start by looking at the initialization part of the method, shown in Listing C.
Listing C: Getting ready to do the convolution
/** This is a generic convolution routine.It takes the pixels around each pixel,multiplies them by a weight held in thepixel_weight array, adds the result up,and divides the total by the number of pixels being processed. This is doneseparately for the red, green, andblue channels.@param radius The radius, inpixels of the area to be processed@param use_base_image If trueuse the base image,if false use the modified image */private void apply_convolution(int radius,boolean use_base_image) {//loop variables x,y go over the image.//i,j go over the convolution matrixint x,y,i,j;//index of a pixel in the convolution//array.int ir,jr;//these hold the running sums generated//by the convolution weights times the//pixel valuesdouble sum_r, sum_g, sum_b;//integer versions of the sumsint isum_r, isum_g,isum_b;//sum of the weights in the convolution//matrixdouble scale;//holds the value of the pixel being//examinedint temp_pixel;//values for the various color channels//for a pixelint alpha, red, green, blue;//This sets the alpha channel so that our//reconstructed pixels are visiblealpha = 255 << 24;//if the pixels aren't loaded then load//them. Should check to see if the image//isn't loaded as well. Note that we//don't have to check if the modified//pixels are loaded because when the//modified picture is made its pixels//are loaded as we'll see below.if(!pixels_loaded_flag) {get_pixels();}//because the radius is around a central//point, a radius of 3 pixels defines a//box which is 3(left side) + 1(middle//pixel) + 3(right side) = 7 wide by 3 +//3 + 1 = 7 highscale = 1.0/(4*(radius + 0.5)*(radius + 0.5));//fill the working copy with the original//image so that pixels that aren't//processed because they're on the edge//of the image have their original//values.if(use_base_image) {System.arraycopy(pixels,0,working_pixels,0,(x_max*y_max));} else {System.arraycopy(modified_pixels,0,working_pixels,0,(x_max*y_max));}
We have two sets of loop variables: x and y, which will loop over all of the pixels in the image that aren't too close to the edge, and i and j, which loop over the pixels that are used to compute the new pixel value at each x,y location. The ranges that i and j will assume depend upon the size of the convolution matrix, which in turn depends on the radius for the effect. The radius specified the maximum offset, in both x and y, that a pixel in the convolution has with respect to the pixel whose new value is being computed. For example, if we're applying the convolution to pixel 13,19 and the radius is 3, then the pixels whose x value varies from 10 to 16 and whose y values range from 16 to 22 will be used. As a result, i will range from -3 to 3, as will j.
The alpha channel, the highest order byte in a 4-byte int, controls the transparency of an image. By setting the alpha value to 255, by using the << operator to shift 255 twenty-four bits to the left and into the most significant byte of the int variable alpha, we ensure that the new pixels we're computing will be fully opaque. Feel free to experiment with other values of alpha.
When we're modifying the base image, we must make sure that we put the base image pixel values into an array of ints. We do so in the get_pixel method, described below.
The scale parameter is the inverse of the sum of the weights in the convolution matrix. We use this value every time we apply the convolution to a pixel. Because it doesn't change, we compute it just once. We use the inverse of the sum rather than the sum, so that every time we use scale, we do a multiply rather than a divide. This is a simple example of an easy optimization. By precomputing this value, we save two adds and two multiplies for each pixel in the image. By using the inverse, we save the difference between a multiply and a divide for each pixel in the image.
In order to do a convolution correctly, we need a working copy of the image to store the new convoluted values as we apply the convolution matrix to successive pixels. To see why we do this, imagine that we apply the convolution across the image. When we compute the convolution of radius 1 for a pixel with x =103, it will use the value of the pixel at x = 102. But since we've already applied the convolution to the pixel at x= 102, we'll use the wrong (i.e., already convoluted) value, of the pixel at x=102 when we compute the convolution for the pixel at x = 103. This same problem occurs as we go down in y—pixels with y values less than that of the pixel whose new value is being computed will have already been convoluted. In this method, we use the modified_pixels or pixels array as the original data that isn't modified. We write the new pixel values to the working_pixels array.
Because we can't apply the convolution to pixels that are closer than the value of radius to any edge of the image, we want to fill in those pixels with the values from the original image. The simplest way to do that is to use the arraycopy method, which is optimized for speed. One thing you might want to try if you're working with large images is to use the arraycopy method to copy just the edge regions of the image, rather than the entire image, as we do here. You can do that by using the arraycopy parameters shown below:
System.arraycopy(Object the_source_array, int starting_point_in_the_source, Object the_destination_array, int starting_point_in_the_destination, int length)
You'll only be able to use this for two edges, because the other two edges aren't stored in sequential order in the source array. For those other two edges, you can copy individual pixels. Another option is to just leave the outer pixels empty and crop the image before displaying it. Now that we've initialized things, we can proceed to actually applying the convolution to the pixels, as shown in Listing D.
Listing D: Computing the new pixel values
/*Here we loop over the width of the image,leaving an edge where pixels don't haveenough neighbors to do the convolution. */for(x=radius;x<(x_max - radius);x++) {//Here we loop over the height of the//image once again leaving an edgefor(y=radius;y<(y_max - radius);y++) {//initialize the sums for each color.sum_r = 0.0;sum_g = 0.0;sum_b = 0.0;//process the nearby pixels to compute//the convolution sumsfor(i=-radius;i<radius+1;i++) {for(j=-radius;j<radius+1;j++){//translate the i,j values into indices//for the pixel_weight array.ir = i + radius;jr = j + radius;//get the pixel value once to save timeif (use_base_image) {temp_pixel = pixels[(x+i)+(y+j)*(x_max)];} else {temp_pixel = modified_pixels[(x+i)+(y+j)*(x_max)];}/*extract the color information from thepixel value. The highest order byte isthe alpha channel followed by the red,green, and blue values. */red = (temp_pixel & 0x00FF0000) >>> 16;green = (temp_pixel & 0x0000FF00) >>> 8;blue = temp_pixel & 0x000000FF;//increment the sums by the pixel values// weighted by the appropriate weightsum_r = sum_r + red*pixel_weights[ir + jr*radius];sum_g = sum_g + green*pixel_weights[ir + jr*radius];sum_b = sum_b + blue*pixel_weights[ir + jr*radius];}//end of loop over j}//end of loop over i//round here to minimize rounding errorisum_r = (int)(Math.round(sum_r*scale));isum_g = (int)(Math.round(sum_g*scale));isum_b = (int)(Math.round(sum_b*scale));//Alternative way to compute new pixel//value using a Color instance/*Color c = new Color(isum_r,isum_g,isum_b);working_pixels[x+y*x_max] = c.getRGB();*///create new pixel values without using a//Color instance to save timeworking_pixels[x+y*x_max] = alpha +(isum_r << 16) + (isum_g << 8) + isum_b;}//end of loop over y}//end of loop over x
The basic structure of this part of the method is defined by four loops. The outer two loop over every pixel in the image that's at least radius pixels away from the edge. Each pixel that meets this criteria is convoluted using the convolution matrix, contained in the pixel_weights attribute. The inner two loops walk over all of the pixels defined by the size of the convolution matrix.
Since this algorithm is designed to work with RGB color images, we process the three color channels in parallel for each pixel. Each pixel's color is stored as int, with the first byte as the alpha channel, the next the red value, the next the green value, and the last the blue value. We extract the color values by using the & operator with the appropriate mask, then using the >>> right-shift operator to convert the values to integers between 0 and 255. We then multiply those values by the appropriate weight and add the result to the running sums for the appropriate color.
When we've finished the two inside loops, we scale the sums by multiplying by the inverse of the sum of the weights, stored in the scale local variable. We then round the sums to integers (rounding the full sum rather than each of the intermediate values reduces the round-off error) so we can use them to create a new value for the pixel. We use an efficient approach to rebuild the new int value based on left-shifting the various color values using the << operator. We don't have to shift the alpha value, because we did that back when we set the value of the alpha local variable.
There's another less efficient but simpler way to get the new value. It's shown commented out in Listing D. We could create a new instance of a Color object and then use the getRGB method, which returns an integer in just the format we need. Unfortunately, this approach is slower, because we have to continually keep making objects. On the plus side, though, the code is easier to maintain.
When the outer two loops are finished marching through and computing new values for all of the pixels within radius pixels of the edge, we're ready to save the new pixel values, which are in working_pixels, to the new modified image and do other cleanup as shown below:
make_image();
} //end of apply_convolution
Now we'll see how make_image converts the pixel array into an image.
Converting a pretty image into an array of numers: get_pixelsThe get_pixels method converts the base image into an array of pixels. We use PixelGrabber—which is a standard Java class—to build our pixel array, as shown in Listing E.
Listing E: Converting an image to pixels
/** This method gets an array of pixelsfrom the base image */public void get_pixels() {PixelGrabber get_pixels;/*create a PixelGrabber instance specifyingthe source image, the offset in x,the offset in y, the image width in pixels,the image height in pixels, the destinationarray, the offset to use in the destinationarray, and the width of a row of data in thedestination array */get_pixels = new PixelGrabber(the_image,0,0,x_max,y_max,pixels,0,x_max);try {//this actually fills the destination//pixel arrayget_pixels.grabPixels();//here we check and see if the pixel//array was properly filledif((get_pixels.status() &ImageObserver.ABORT) == 0) {pixels_loaded_flag = true;} else {System.out.println("ERROR:picture:get_pixels:problem reading in pixels "+ get_pixels.status());}} catch(InterruptedException e) {System.out.println("ERROR:picture:get_pixels:Problem getting pixelsfor the image " + e);}}// end of get_pixels method
.
To use PixelGrabber, we create a new instance of it where we define which part of the image we want transferred, the int array we want it transferred to, and what part of that destination array we want the transferred pixels stored in. While we're using PixelGrabber in the simplest way—copying the whole image into an array—it's very easy to copy rectangular pieces of an image into parts of the destination array. All you need to do is specify non-zero x and y offsets and specify the appropriate offsets. You can use this to combine multiple images into a collage.
Once we've properly configured the PixelGrabber instance, all we need to do is call the grabPixels method, then check to make sure that everything went well using the status method. We also need to catch exceptions that PixelGrabber may raise.
Trading pretty numbers for dull picture: make_imageThis method converts the working_pixel array, which contains the modified pixel values, into an image, which is stored in the the_modified_image attribute. The process is fairly straightforward, as shown in Listing F.
Listing F: Building an image from pixels
/**This method makes a modified imageusing an array of pixel values */public void make_image() {try {//flag that we're loading the imageloading_modified_image_flag = true;/*use createImage, a Component class method,to make an image from an array of pixels */the_modified_image =((Applet)my_parent).createImage(new MemoryImageSource(x_max,y_max,working_pixels,0,x_max));//put the new image into mediatracker so//we can tell when it's loadedmy_tracker.addImage( the_modified_image, 1);} catch (Exception e) {System.out.println("ERROR:picture:make_image:Problem trying to createa modified picture " + e);}//end of try}//end of make_image method
.
We create a MemoryImageSource, which is an ImageProducer, that takes an array of ints and feeds them to the createImage method. The parameters for the MemoryImageSource creator method are the width and height of the image we wish to make from the array, the array that contains the pixel values, the offset we use when reading from the source array, and the width of the destination image. We could also have specified a ColorModel to use –(we went with the default RGB model) by placing a ColorModel instance after the first two arguments in the MemoryImageSource call.
Because the creation of this image is asynchronous, we need to use MediaTracker to monitor when the new modified image is ready. We register the new image for monitoring by calling the addImage method (for details on how to use MediaTracker, see part H. As before, we'll periodically check the status of the modified image in picture's run method. The code that looks for the finished modified image is shown in Listing G. The whole run method was shown last month in part 1.
Listing G: Looking for the finished image in the run method
/* the first time through the whileloop after the modified image isloaded we call the parent instance soit can use the new loaded imageif(my_tracker.checkID(1,true) &loading_modified_image_flag) {loading_modified_image_flag = false;mod_image_loaded_flag = true;my_parent.modified_picture_loaded(this);}
When the image is loaded, as determined by the MediaTracker checkID method, we set the appropriate flags to signify the new state (i.e., the modified image is loaded), and we call the modified_picture_loaded callback method, defined in the picture_user interface, on the parent applet. At this point, the applet uses the picture as last month.
Getting the modified image: get_modified_pictureThe parent applet uses this method, shown in Listing H, to get the modified image. It's called from the modified_picture_loaded callback method.
Listing H: Getting the modified image
/** This method returns the modifiedpicture. If there is no modifiedpicture or it is being loaded null isreturned */public Image get_modified_picture() {//if the image is being loaded or hasn't//been loaded return nullif(loading_modified_image_flag ||!mod_image_loaded_flag) {return null;} else {return the_modified_image;}}
This method is essentially identical to the get_picture method, except we work with the modified image. We could have combined these two methods into one and passed an input parameter that tells the method which image to return, but I've found that short, simple methods are easier to maintain even if there are more of them.
Stopping the picture: stopThis is just a short public method that allows us to stop the thread if we've finished processing the images:
public void stop() {
my_thread.stop();
}
Special bonus: unsharp_mask
This method, which isn't used anywhere in this sample applet, performs an unsharp mask operation on the image. It sharpens the image and brings out detail. We can vary the effect by changing the first input parameter. The method, just like the blur method, simply defines the convolution matrix and lets the apply_convolution method do all the work, as we can see from Listing I.
Listing I: Another image processing function
public boolean unsharpmask(double effect,boolean use_base_image) {int i;/*use a fixed radius of 1 construct theweights applied to each neighboring pixelin the blur convolution */pixel_weights = new double[9];for(i=0;i<9;i++) {pixel_weights[i] = -1;}/* set the weight of the central pixel basedon the input param. The param should be atleast 8 and values between 9 and 12 arefairly useful */pixel_weights[5]=effect;/* handle problems such as the modifiedimage not being available */if(!use_base_image &&!mod_pixels_loaded_flag) {return false;} else {//apply the sharpen convolution to the//dataapply_convolution(1,use_base_image);return true;}}
You can extend the functionality of the picture class very easily with similar methods. Any book on image processing will contain a wide variety of convolutions that you can add just by creating a simple method that defines the convolution matrix.
ConclusionBecause Java makes it easy to convert images into arrays of pixels, we can easily perform fairly complex image processing without a lot of work. Here we've shown how to build a simple set of image processing effects, but the basic skeleton we've built is easily extensible and able to support much more complex processing. This approach is also usable for Java image-processing applications.
Copyright © 1998, ZD
Inc. All rights reserved. ZD Journals and the ZD Journals logo are trademarks of ZD
Inc. Reproduction in whole or in part in any form or medium without
express written permission of ZD Inc. is prohibited. All other product
names and logos are trademarks or registered trademarks of their
respective owners.